Fundamental Algorithm of Convolution in Neural Networks
Summary
TLDRThis video introduces the fundamental concept of a neural network's convolutional layer, focusing on how filters process input data to generate output. Using a 2D convolutional approach, the script explains how the network examines small patches of input to detect patterns like edges or colors, with deeper layers identifying complex features such as faces. The video emphasizes the computational efficiency and reduced parameter count of convolution, making it ideal for spatially structured data like images, video, and audio. The presenter avoids math to ensure clarity, promising future videos for in-depth explanations.
Takeaways
- 😀 The video focuses on explaining the fundamental algorithm of a neural network's convolutional layer without involving complex mathematics.
- 😀 The goal is to understand the core concepts of convolution, not the calculations, making it accessible to a wider audience.
- 😀 A convolutional layer processes a two-dimensional feature map, which has two spatial dimensions and one feature dimension.
- 😀 The weights in a convolutional layer are stored in four-dimensional tensors, broken into smaller three-dimensional tensors known as 'filters.'
- 😀 Filters contain values that control the output, and these values are adjusted during the training process to improve the network's performance.
- 😀 Convolution combines each filter with a local patch of the input to compute a single output value, measuring how well the input matches the filter's pattern.
- 😀 The output value corresponds to how well a pattern (e.g., color or edge) is found in the input, with deeper layers identifying more complex features (e.g., faces or dogs).
- 😀 The process repeats across the entire input, moving from patch to patch and row to row, producing an output feature map.
- 😀 The repetitive, local approach of convolution allows for spatially structured data (like images and audio) to be processed efficiently with fewer parameters.
- 😀 Multiple filters are used to generate different features of the output, with each filter producing a unique feature map, reflecting a specific pattern found in the input.
Q & A
What is the main goal of the video?
-The main goal of the video is to introduce the fundamental algorithm of a neural network's convolutional layer, focusing on the concepts rather than the math or calculations.
What type of convolutional layer is the video primarily focused on?
-The video is primarily focused on two-dimensional convolutional layers, which are the most common in practice.
What is a 'feature map' in the context of this video?
-A feature map is a tensor with two spatial dimensions and one feature dimension. It represents the input or output of a convolutional layer in a neural network.
Why does the video replace numbers with cubes when explaining convolution?
-The video replaces numbers with cubes to help viewers focus on the conceptual understanding of convolution, without getting bogged down by the complexity of the actual calculations or numbers.
What are 'filters' in a convolutional layer?
-Filters are parts of the weights in a convolutional layer that control the output. They are usually represented as three-dimensional tensors, and they help the network identify patterns in the input data.
How does the convolutional layer work with filters to generate output?
-In a convolutional layer, a filter is applied to small patches of the input. The filter detects a specific pattern in each patch and calculates an output value based on how well the patch matches the pattern. This process is repeated across the entire input to form the output.
Why does the convolutional layer use local patches of the input data?
-The convolutional layer uses local patches because spatially nearby information is often related, especially in data like images or audio. This local examination helps the network recognize smaller features such as edges or textures.
How does the use of local patches make convolution more computationally efficient?
-By focusing on small, local patches and applying the same operation across the entire input, convolution reduces the number of parameters and computations compared to fully connected layers, making it more computationally efficient.
What happens when multiple filters are applied in the convolutional layer?
-Each filter in a convolutional layer generates a different feature map. These features are combined to form the complete output of the layer, with each filter identifying a distinct aspect or pattern in the input data.
What is the significance of using deeper layers in a convolutional neural network?
-Deeper layers in a convolutional network can recognize more complex patterns, such as objects or faces, by building on the features detected in earlier, shallower layers. This hierarchical feature extraction helps in accurately identifying and classifying complex data.
Outlines

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraMindmap

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraKeywords

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraHighlights

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraTranscripts

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraVer Más Videos Relacionados

Bentuk Otaknya AI | Pengenalan Artificial Neural Network

How Neural Networks work in Machine Learning ? Understanding what is Neural Networks
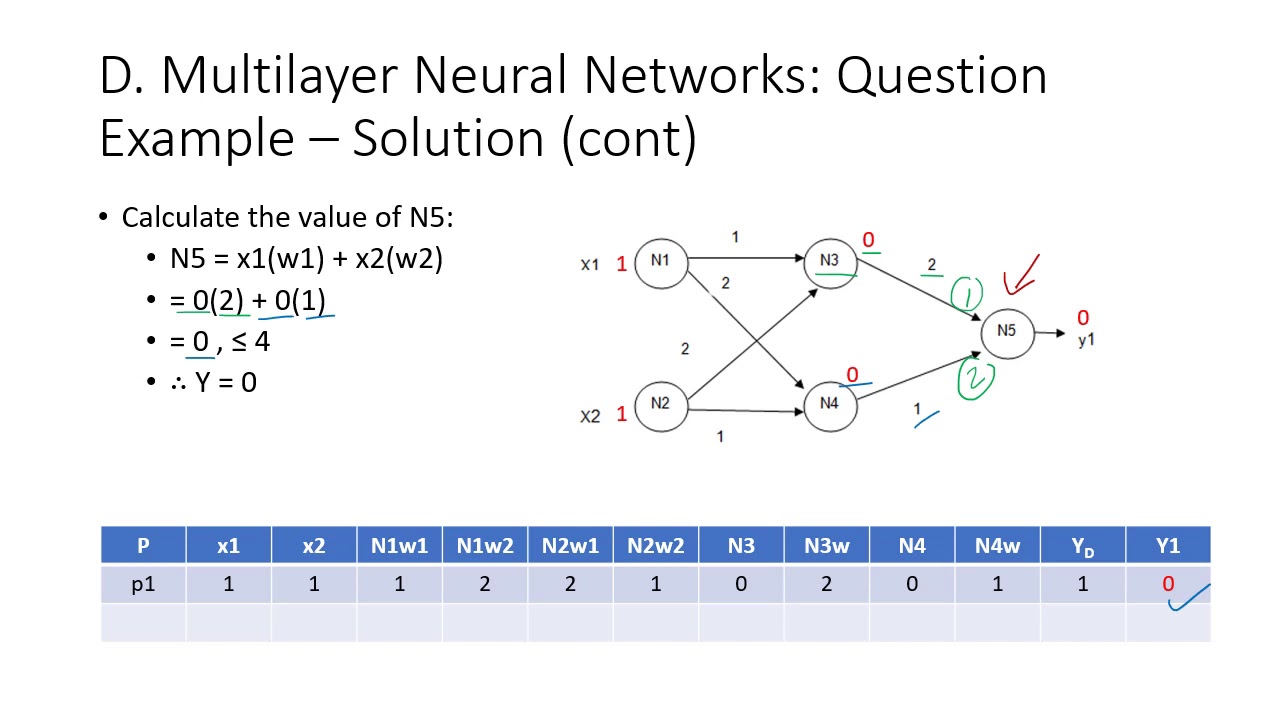
Topic 3D - Multilayer Neural Networks

TUGAS PEMROSESAN CITRA DIGITAL (RESUME TENTANG KONVOLUSI)

Redes Neurais Artificiais #02: Perceptron - Part I
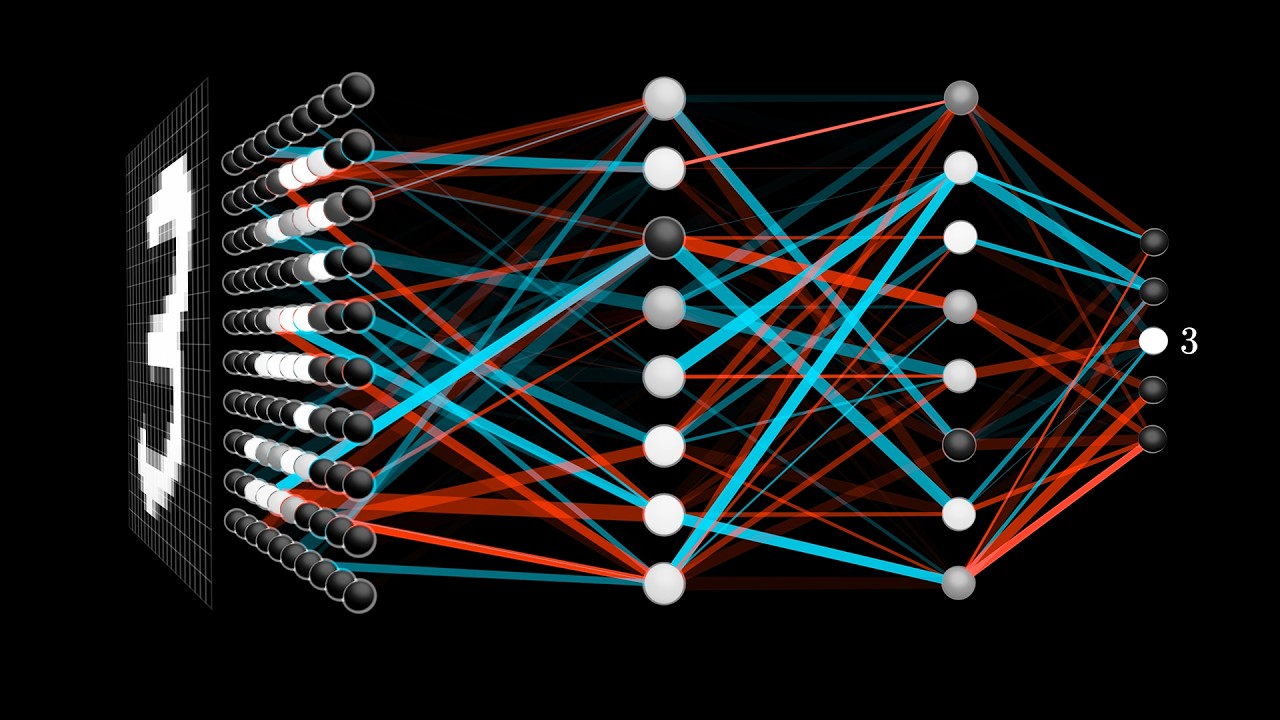
But what is a neural network? | Chapter 1, Deep learning
5.0 / 5 (0 votes)
