Mechanistic Interpretability explained | Chris Olah and Lex Fridman
Summary
TLDRThis transcript delves into the fascinating field of mechanistic interpretability in neural networks, exploring how they 'grow' through training and the challenge of reverse-engineering their inner workings. The discussion highlights the importance of uncovering the algorithms and 'circuits' that drive network behavior, contrasting earlier interpretability methods like saliency maps. Key topics include the linear representation hypothesis, universality in neural networks and biological systems, and the philosophical value of pushing hypotheses, even when uncertain. The conversation underscores the importance of deep, systematic exploration in advancing our understanding of AI and neural networks.
Takeaways
- 😀 Mechanistic interpretability (Mech interp) is the study of how neural networks make decisions and function, focusing on understanding their internal representations and processes.
- 😀 Traditional software engineering is different from neural network-based systems, as neural networks learn to perform tasks without explicit programming, making them harder to interpret.
- 😀 Saliency maps, while useful for highlighting important parts of input, don't explain how neural networks perform tasks, which is the focus of mechanistic interpretability.
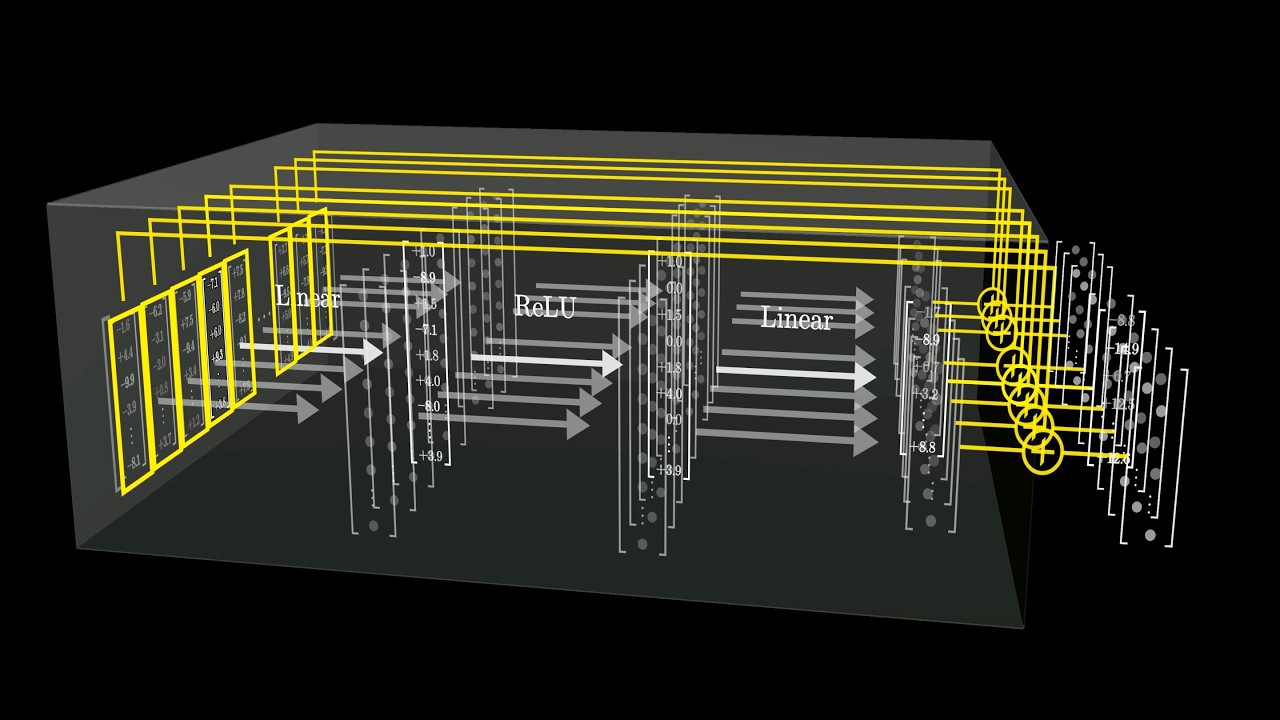
- 😀 One key concept in mechanistic interpretability is that neural networks learn algorithms through gradient descent, with weights acting as 'compiled binary' and activations as 'memory.'
- 😀 The 'linear representation hypothesis' suggests that neural network activations can be understood as linear combinations of features, forming directions in high-dimensional space.
- 😀 Features in neural networks correspond to particular aspects of data, like edges or objects in vision models, while circuits are groups of features that work together to perform computations.
- 😀 Biological neural networks and artificial networks often exhibit similar feature formations, such as Gabor filters, suggesting convergent evolution of visual processing systems.
- 😀 While evidence for linear representations is strong, some researchers are exploring whether neural networks might use multi-dimensional or non-linear representations, especially in smaller models.
- 😀 Mechanistic interpretability draws parallels with scientific methodology, emphasizing the importance of thoroughly testing hypotheses, even if they might ultimately be incorrect.
- 😀 Even if some hypotheses (like the linear representation hypothesis) are disproven, pursuing them can still yield valuable insights and spur technological advancements, much like historical scientific theories.
Q & A
What is mechanistic interpretability (MechInterp)?
-Mechanistic interpretability is the field of research focused on understanding how neural networks function internally. It aims to reverse-engineer neural networks to uncover the specific algorithms and features that allow them to perform tasks, beyond simply interpreting their outputs.
How does mechanistic interpretability differ from traditional interpretability methods like saliency maps?
-Traditional interpretability methods like saliency maps show which parts of the input influence the model's output, but they don’t explain how the model’s internal mechanisms or computations lead to the decision. Mechanistic interpretability, on the other hand, seeks to identify the internal features and circuits that correspond to the computations performed by the network.
What are features and circuits in the context of neural networks?
-In mechanistic interpretability, 'features' are abstract representations formed by combinations of neurons in the network, each corresponding to a meaningful concept (e.g., edges, shapes, or objects). 'Circuits' are the connections between these features that perform higher-level computations, such as recognizing a specific object or pattern.
What is the linear representation hypothesis in neural networks?
-The linear representation hypothesis suggests that the activations of neurons in a neural network can be interpreted as linear combinations of features. In other words, the network's ability to perform complex tasks arises from combining simple, abstract features in a high-dimensional space.
Can you give an example of the linear representation hypothesis from word embeddings?
-An example of the linear representation hypothesis is seen in word embeddings, such as the famous analogy: 'King - Man + Woman = Queen.' This shows how relationships between words can be represented as arithmetic operations in vector space, supporting the idea that linear combinations of features can capture complex relationships.
Why is the linear representation hypothesis important for understanding neural networks?
-The linear representation hypothesis is important because it offers a framework to understand how complex patterns and behaviors emerge from simpler neural activations. It suggests that neural networks might operate by combining and modifying basic features in a structured way, making them more interpretable.
What challenges does mechanistic interpretability face?
-One major challenge is the complexity of neural networks, especially deep networks with millions of parameters, which makes it difficult to trace and understand how features and circuits lead to specific outcomes. Additionally, small models may not adhere to linear representations, adding further complexity.
What is the significance of 'pushing hypotheses as far as they can go' in scientific research?
-Pushing hypotheses to their limits is essential in science because it allows researchers to test theories rigorously, uncover potential flaws, and refine their understanding. Even if a hypothesis turns out to be incorrect, exploring it deeply can yield valuable insights and lead to new discoveries.
How does the analogy with caloric theory relate to the pursuit of hypotheses in mechanistic interpretability?
-The analogy with caloric theory illustrates that even outdated or incorrect scientific ideas can drive significant progress. Just as the belief in caloric theory led to the development of early combustion engines, pursuing hypotheses in mechanistic interpretability—whether ultimately correct or not—can lead to new insights and breakthroughs.
What role does confidence play in scientific research, particularly in MechInterp?
-In scientific research, confidence allows researchers to fully explore a hypothesis, even if they don’t have definitive proof of its correctness. Taking a hypothesis seriously and working within its assumptions can lead to valuable results, whether by disproving it or uncovering new understandings that refine or revise the theory.
Outlines

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraMindmap

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraKeywords

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraHighlights

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraTranscripts

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraVer Más Videos Relacionados

What Do Neural Networks Really Learn? Exploring the Brain of an AI Model
How might LLMs store facts | Chapter 7, Deep Learning

Generative AI: Processing & Neural Networks

Deep Fake | Nerdologia Tech

Backpropagation in Neural Networks | Back Propagation Algorithm with Examples | Simplilearn

Visualizing CNNs
5.0 / 5 (0 votes)
