Machine Learning Tutorial Python - 4: Gradient Descent and Cost Function
Summary
TLDRThis script offers an insightful walkthrough of key machine learning concepts, focusing on the Mean Square Error (MSE) cost function, gradient descent, and the significance of the learning rate. The tutorial aims to demystify the mathematical underpinnings often encountered in machine learning, emphasizing a step-by-step approach to grasp these concepts without being overwhelmed. By the end, viewers are guided to implement a Python program that employs gradient descent to find the best fit line for a given dataset, illustrating the process through visual representations and debugging techniques. The practical exercise involves analyzing the correlation between math and computer science scores of students, applying the gradient descent algorithm to determine the optimal values of m and b, and ceasing iterations once a predefined cost threshold is met, showcasing the algorithm's convergence to the global minimum.
Takeaways
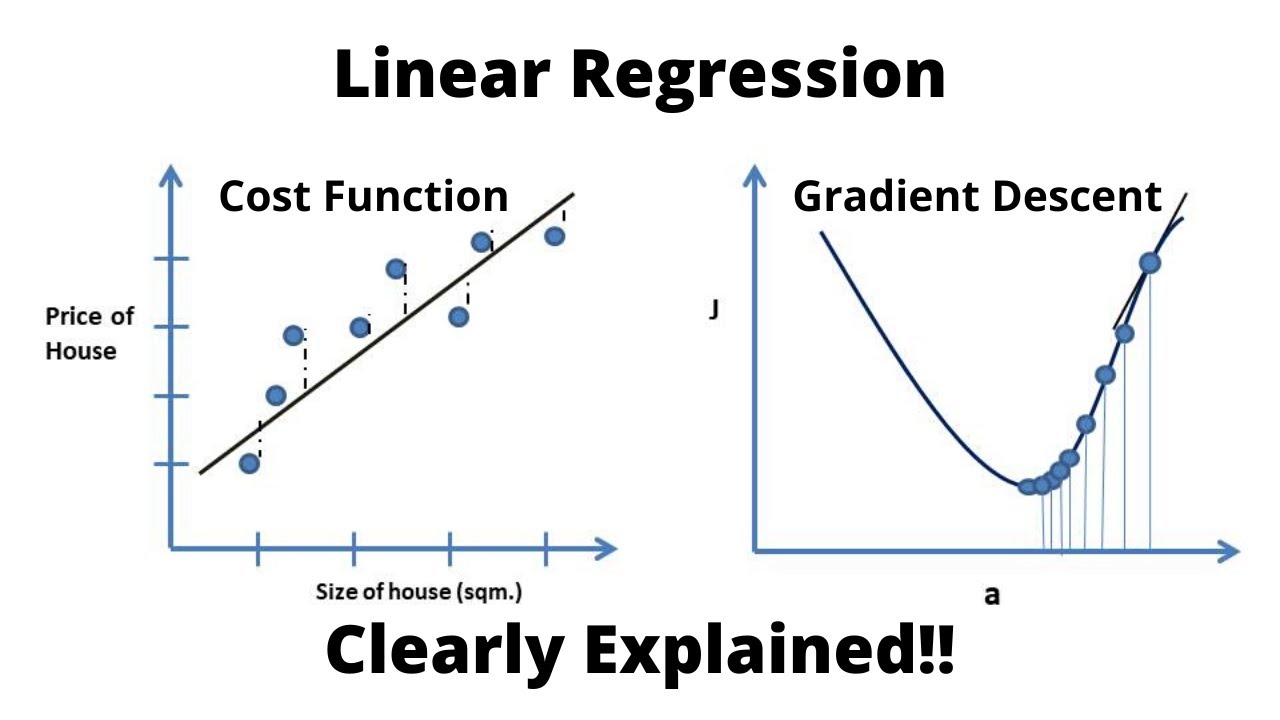
- 📘 Mean Square Error (MSE) is a popular cost function used in machine learning to measure the average squared difference between the estimated values and the actual value.
- 🔍 Gradient descent is an optimization algorithm used to find the best fit line by iteratively adjusting the parameters (m and b) to minimize the cost function.
- 📈 The learning rate is a key parameter in gradient descent that determines the size of the steps taken towards the minimum of the cost function.
- 📉 MSE is calculated as the sum of the squares of the differences between the predicted and actual data points, divided by the number of data points.
- 📊 To implement gradient descent, one must calculate partial derivatives of the cost function with respect to each parameter, which indicate the direction of the steepest increase.
- 🔢 The slope of the tangent at a point on a curve represents the derivative at that point, which is used to guide the direction of the step in gradient descent.
- 🔄 The process of gradient descent involves starting with initial guesses for m and b, then iteratively updating these values based on the partial derivatives and learning rate.
- 🔧 Numpy arrays are preferred for this type of computation due to their efficiency in matrix operations and faster computation speed compared to regular Python lists.
- 🔭 Visualization of the gradient descent process can be helpful in understanding how the algorithm moves through parameter space to find the minimum of the cost function.
- 🔴 The algorithm stops when the cost no longer decreases significantly, indicating that the global minimum has been reached or is very close.
- 🔬 Calculus is essential for understanding how to calculate the derivatives and partial derivatives that are used to guide the steps in gradient descent.
Q & A
What is the primary goal of using a mean square error cost function in machine learning?
-The primary goal of using a mean square error cost function is to determine the best fit line for a given dataset by minimizing the average of the squares of the errors or deviations between the predicted and actual data points.
How does gradient descent help in finding the best fit line?
-Gradient descent is an optimization algorithm that iteratively adjusts the parameters (m and b in the linear equation y = mx + b) to minimize the cost function. It does this by calculating the gradient (partial derivatives) of the cost function with respect to each parameter and updating the parameters in the direction that reduces the cost.
Why is it necessary to square the errors in the calculation of the mean square error?
-Squaring the errors ensures that all errors are positive and prevents them from canceling each other out when summed. This makes it easier to optimize and find the minimum value of the cost function.
What is the role of the learning rate in the gradient descent algorithm?
-The learning rate determines the size of the steps taken during each iteration of the gradient descent algorithm. It is a crucial parameter that affects the convergence of the algorithm; a learning rate that is too high may overshoot the minimum, while a rate that is too low may result in slow convergence or getting stuck in a local minimum.
How does the number of iterations affect the performance of the gradient descent algorithm?
-The number of iterations determines how many times the gradient descent algorithm will update the parameters. More iterations allow for more refinement and potentially a better fit, but they also increase the computational cost. There is a trade-off between accuracy and efficiency that needs to be considered.
What is the significance of visualizing the cost function and the path taken by gradient descent?
-Visualizing the cost function and the path of gradient descent helps in understanding how the algorithm navigates through the parameter space to find the minimum of the cost function. It provides insights into the convergence behavior and can help in diagnosing issues such as getting stuck in local minima or failing to converge.
Why is it important to start with an initial guess for m and b in the gradient descent algorithm?
-Starting with an initial guess for the parameters m and b is important because gradient descent is sensitive to the starting point. Different starting points may lead to different local minima. However, with a well-behaved cost function, gradient descent can find the global minimum if the learning rate is properly chosen.
What are partial derivatives and how do they relate to the gradient descent algorithm?
-Partial derivatives are derivatives of a function with respect to a single variable, keeping all other variables constant. In the context of gradient descent, partial derivatives of the cost function with respect to each parameter (m and b) provide the direction and magnitude of the steepest descent, which is used to update the parameters and 'descend' towards the minimum.
How can one determine when to stop the gradient descent algorithm?
-The algorithm can be stopped when the change in the cost function between iterations falls below a certain threshold, indicating that the parameters have converged to a minimum. Alternatively, one can compare the cost between different iterations and stop when the cost does not significantly decrease, suggesting that further iterations will not yield a better fit.
What is the purpose of using numpy arrays over simple Python lists when implementing gradient descent in Python?
-Numpy arrays are preferred over simple Python lists for their efficiency in performing matrix operations, which are common in gradient descent calculations. Numpy arrays are also faster due to their optimized implementations and support for vectorized operations.
In the context of the tutorial, what is the exercise problem that the audience is asked to solve?
-The exercise problem involves finding the correlation between math scores and computer science scores of students using the gradient descent algorithm. The audience is asked to apply the algorithm to determine the best fit line (values of m and b) and to stop the algorithm when the cost between iterations is within a certain threshold.
Outlines

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraMindmap

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraKeywords

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraHighlights

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraTranscripts

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahora




5.0 / 5 (0 votes)
