Convolutional Neural Networks from Scratch | In Depth
Summary
TLDRThis video provides a detailed exploration of forward propagation in Convolutional Neural Networks (CNNs), breaking down the mathematical processes involved in classifying images. It covers the model's architecture, including convolution and pooling layers, explaining how filters and activation functions work together to extract features from grayscale images. The video also illustrates the transition from pooling layers to fully connected layers, culminating in the model's ability to make accurate predictions. This insightful explanation aims to enhance viewers' understanding of CNNs and their practical applications in image classification.
Takeaways
- 😀 The video explains how convolutional neural networks (CNNs) classify images using forward propagation.
- 🖼️ The model discussed is pre-trained and achieves an accuracy of 95.4%.
- 📏 Input images have dimensions of 28x28x1, representing grayscale images without color channels.
- 🔍 The first layer involves convolution with two filters sized 5x5x1, using the ReLU activation function.
- 🔢 During convolution, kernel weights are multiplied by input pixel values, and results are summed up with a bias term.
- 📊 The activation layer outputs values based on the ReLU function, turning negative results into zero.
- 🧩 Max pooling with a 2x2 filter and a stride of 2 reduces output dimensions while retaining key features.
- 📈 The second layer employs four filters of size 3x3x2 with the sigmoid activation function, producing output values between 0 and 1.
- 🗂️ Flattening the output from the second layer leads to a fully connected layer with 100 input nodes and 10 output nodes.
- 🤖 The final output layer predicts class labels based on the processed input, demonstrating the model's capabilities.
Q & A
What is the main focus of the video?
-The video aims to provide an in-depth understanding of how forward propagation works in a convolutional neural network (CNN) by visualizing and explaining the underlying mathematics.
What is the accuracy of the pre-trained model discussed in the video?
-The pre-trained model has an accuracy of 95.4%.
What are the dimensions of the input image for the model?
-The input image has dimensions of 28 by 28 by 1.
What types of layers are involved in the convolutional neural network described?
-The network includes convolutional layers, pooling layers, a flattening layer, and a fully connected layer.
What activation function is used in the first convolutional layer?
-The first convolutional layer uses the ReLU (Rectified Linear Unit) activation function.
How does Max pooling differ from convolution?
-In Max pooling, the maximum value is extracted from a specific area of the input matrix instead of performing complex calculations like in convolution. It helps reduce the dimensions of the output.
What is the purpose of flattening the matrices in the CNN?
-Flattening the matrices prepares the output from the convolutional and pooling layers for the fully connected layer by converting it into a one-dimensional array.
What is the function of the sigmoid activation in the second convolutional layer?
-The sigmoid activation function outputs values in the range between approximately 0 and 1, helping to determine the activation of the neurons in this layer.
How are the outputs of the fully connected layer generated?
-The outputs are generated by multiplying the input nodes by their corresponding weights, summing the results, and adding bias terms before producing the final output.
What prediction does the model make at the end of the process?
-The model predicts that the input image represents the number 7, which is confirmed by the earlier discussions in the video.
Outlines

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraMindmap

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraKeywords

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraHighlights

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraTranscripts

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraVer Más Videos Relacionados
What is a convolutional neural network (CNN)?
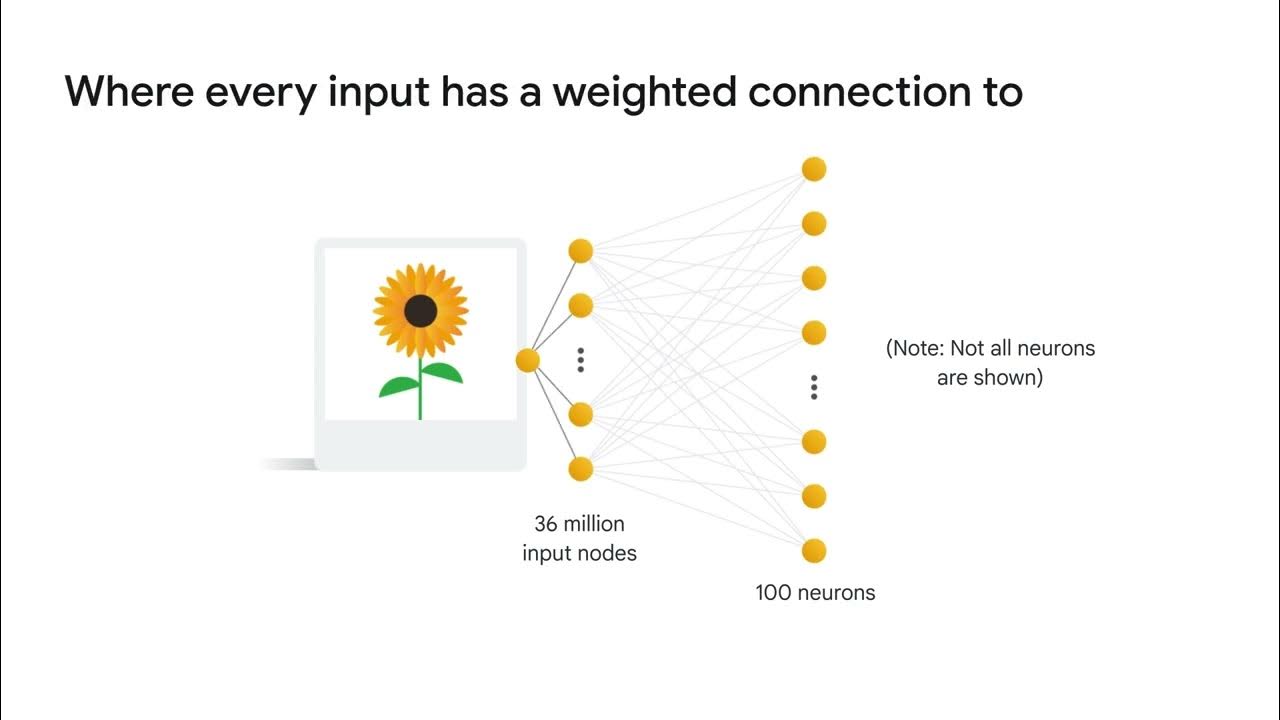
Convolutional Neural Networks

Convolutional Neural Networks Explained (CNN Visualized)

ANN vs CNN vs RNN | Difference Between ANN CNN and RNN | Types of Neural Networks Explained

ml5.js: Train a Neural Network with Pixels as Input

Neural Networks Part 8: Image Classification with Convolutional Neural Networks (CNNs)
5.0 / 5 (0 votes)
