Transcribe Audio Files with OpenAI Whisper
Summary
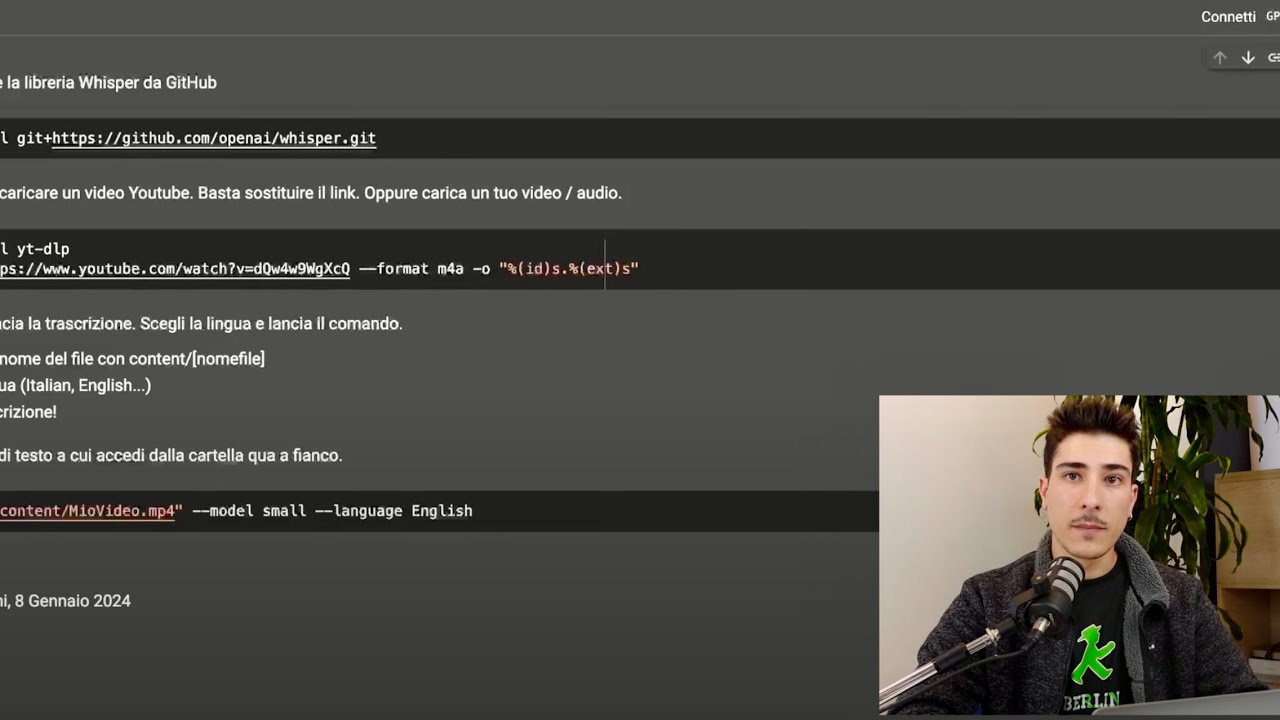
TLDRIn this informative video, the host demonstrates how to transcribe audio files using OpenAI's Whisper model in Python. The process is straightforward, requiring only a few lines of code and the Whisper package, which can be installed without an API key. The host uses an audio file from one of his videos to illustrate the transcription process, noting that while it won't be perfect, it will provide a high-quality result. The video also discusses potential challenges with recognizing certain technical terms not commonly found in dictionaries. The transcription is performed locally, eliminating the need for cloud-based models or extensive hardware resources. The host concludes by encouraging viewers to like, comment, and subscribe for more content.
Takeaways
- 🎓 The video teaches how to transcribe audio files using OpenAI Whisper in Python.
- 📚 The process is straightforward, requiring only a few lines of code.
- 🔊 An audio file, such as 'video_sound.mp3', is used as an example for transcription.
- 📝 The transcription can be used for creating subtitles or for machine learning tasks like building a video search engine.
- 🤖 OpenAI Whisper is a model that can be used without an API key or tokens.
- 💻 The transcription runs locally on the user's machine, so no cloud model is needed.
- 🖥️ The video presenter has tested the process on a five-year-old laptop with an AMD GPU, indicating it doesn't require top-tier hardware.
- ⏱️ The transcription process is relatively quick, although the presenter skipped the waiting part of the video.
- 📋 The result is saved in a text file, with only the transcribed text being written, not the entire output.
- 🚫 Some words, especially package names and less common terms, may not be recognized accurately and require manual adjustment.
- 📈 The quality of the transcription is described as very high compared to basic speech recognition methods.
- 📘 The video concludes with a call to action for viewers to like, comment, subscribe, and enable notifications for future content.
Q & A
What is the main topic of the video?
-The main topic of the video is learning how to transcribe audio files using Open AI Whisper in Python.
Why might certain words not be recognized during transcription?
-Certain words like package names, application names, and technologies not in the dictionary may not be recognized because they are not commonly used or understood by the transcription model.
What is the purpose of transcribing audio files?
-Transcribing audio files can be used for creating subtitles, performing machine learning tasks, or building a search engine to find specific terms within videos.
How many lines of code are needed to perform the transcription according to the video?
-The video suggests that only a few lines of code are needed to perform the transcription using Open AI Whisper.
What is the name of the Python package used for transcription in the video?
-The Python package used for transcription in the video is called 'openai-whisper'.
What is the file format of the audio file used in the example?
-The file format of the audio file used in the example is MP3.
What is the name of the file where the transcription result is saved?
-The transcription result is saved in a file named 'transcription.txt'.
Does the transcription process require an API key or tokens?
-No, the transcription process does not require an API key or tokens as the model can be used without them.
What hardware requirements are mentioned for running the transcription model?
-Decent hardware is mentioned, but the video also notes that it has been run on a five-year-old laptop with an AMD GPU, indicating that very modern or high-end hardware is not strictly necessary.
What are the potential issues with using basic speech recognition as compared to Open AI Whisper?
-Basic speech recognition might be a hassle to manage due to data limitations and is likely to have a higher rate of incorrect transcriptions compared to Open AI Whisper, which provides a higher quality transcription.
How can the transcription be improved for special names or package names that are not recognized?
-The transcription can be improved by manually adjusting the unrecognized names or package names after the initial transcription is complete.
What is the advantage of running the transcription model locally?
-Running the transcription model locally allows for free transcription without the need for an API key, tokens, or cloud-based services.
Outlines

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنMindmap

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنKeywords

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنHighlights

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنTranscripts

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنتصفح المزيد من مقاطع الفيديو ذات الصلة

Transcribe Audio to Text for FREE | Whisper AI Step-by-Step Tutorial

ازاي تحول اي فيديو او ملف صوتي الى ملف نصي تقدر تتكلم معاه و تلخصه باستخدام بايثون و ChatGPT

Transcribe and Translate in Real Time NO INTERNET REQUIRED!

STOP Losing Views! Add Captions to Your YouTube Videos Today

Predictions - Deep Learning for Audio Classification p.8
Usare l’AI per prendere appunti da qualsiasi video (TUTORIAL)
5.0 / 5 (0 votes)
