What is Classification? What is a Classifier?
Summary
TLDRThis video introduces the concept of classification in data mining, focusing on predicting categorical variables, also known as classes. The presenter explains the process of building a model using both categorical and numerical variables, which are referred to as descriptors, attributes, or features. The video explores the idea of linear and nonlinear separability, using examples such as height and weight to demonstrate binary and multi-class classification. It emphasizes the importance of using diagrams for data visualization and highlights key classification methods such as decision trees, logistic regression, and K-nearest neighbors. The video also discusses transforming categorical data and provides a preview of upcoming topics on classification algorithms.
Takeaways
- 😀 Classification is a data mining task focused on predicting the value of a categorical variable, also known as a class or target.
- 😀 Variables used for classification can be numerical or categorical, and may be transformed between these types (e.g., binning, encoding).
- 😀 Descriptors or features (predictors) are used to build classification models. These can be categorical or numerical.
- 😀 A classification problem often involves predicting a binary outcome (e.g., 'yes' or 'no'), but multi-class problems can be transformed into binary ones using techniques like one-vs-all.
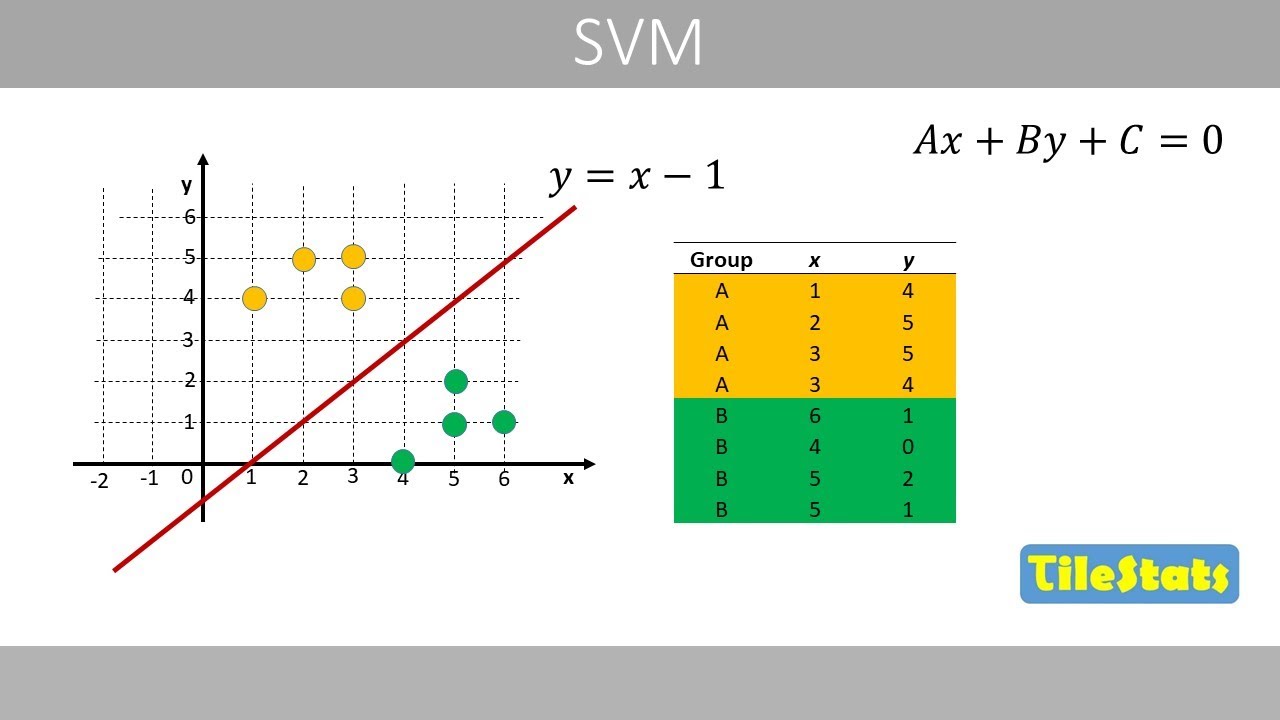
- 😀 Linear separability refers to data that can be separated by a straight line, while non-linear separability involves cases where no straight line can perfectly divide the data.
- 😀 Diagrams are essential for visualizing and understanding the structure and separability of the data, aiding in the classification process.
- 😀 Data with multiple dimensions (e.g., height and weight) can be split by a line in 2D, a plane in 3D, and a hyperplane in higher dimensions.
- 😀 The upcoming tutorials will cover different classification algorithms such as ZeroR, OneR, Naive Bayes, Decision Tree, Linear Discriminant Analysis, Logistic Regression, K-Nearest Neighbors, and Support Vector Machines.
- 😀 For non-linearly separable data, transformation techniques such as adding more dimensions or using specialized algorithms may be applied.
- 😀 Always remember that both categorical and numerical variables can be transformed to work in different classification algorithms (e.g., encoding for categorical, binning for numerical).
Q & A
What is classification in the context of data mining?
-Classification is a data mining task where the goal is to predict the value of a categorical variable, also known as the 'Target' or 'Class'. This involves using input data with numerical or categorical variables to build a model that predicts the class label.
What are descriptors or features in classification?
-Descriptors, also known as features, attributes, or predictors, are the variables or characteristics used to build a classification model. These can be numerical or categorical and help in predicting the class label.
What is the difference between categorical and numerical variables?
-Categorical variables represent categories or distinct groups, such as 'Yes' or 'No', while numerical variables represent quantities or measurements, like height or weight. Categorical variables can be transformed into numerical values and vice versa using encoding or discretization techniques.
How does the concept of linear separability relate to classification?
-Linear separability refers to the ability to separate two classes in a dataset with a straight line (in 2D), a plane (in 3D), or a hyperplane (in more than 3D). If a dataset is linearly separable, it means that a clear boundary can be drawn to distinguish the classes.
What is nonlinear separability?
-Nonlinear separability occurs when a dataset cannot be separated by a straight line, plane, or hyperplane. In such cases, transformations or more complex algorithms might be needed to classify the data effectively.
What is the purpose of using diagrams in classification problems?
-Diagrams are helpful in classification as they provide a visual representation of data. They help in understanding the distribution of data, identifying patterns, and determining if the data is linearly or nonlinearly separable.
What is binary classification, and how is it different from multi-class classification?
-Binary classification involves predicting one of two possible classes, such as 'Yes' or 'No'. Multi-class classification involves predicting more than two classes. A multi-class problem can be transformed into a binary classification problem using techniques like 'one-vs-all'.
What is the 'one-vs-all' technique?
-The 'one-vs-all' technique is used to convert a multi-class classification problem into multiple binary classification problems. For each class, a separate binary classifier is trained to distinguish that class from all others.
What are some common classifiers discussed in the video?
-The video discusses several classifiers, including ZeroR, OneR, Naive Bayes, Decision Trees, Linear Discriminant Analysis, Logistic Regression, K-Nearest Neighbors, Artificial Neural Networks, and Support Vector Machines.
How can categorical variables be transformed for use in classification models?
-Categorical variables can be transformed into numerical variables using encoding techniques. Similarly, numerical variables can be transformed into categorical variables through binning or discretization techniques.
Outlines

此内容仅限付费用户访问。 请升级后访问。
立即升级Mindmap

此内容仅限付费用户访问。 请升级后访问。
立即升级Keywords

此内容仅限付费用户访问。 请升级后访问。
立即升级Highlights

此内容仅限付费用户访问。 请升级后访问。
立即升级Transcripts

此内容仅限付费用户访问。 请升级后访问。
立即升级浏览更多相关视频

Klasifikasi dengan Algoritma Naive Bayes Classifier

Variables and Types of Variables | Statistics Tutorial | MarinStatsLectures

Lec-5: Logistic Regression with Simplest & Easiest Example | Machine Learning

Support Vector Machine: Pengertian dan Cara Kerja

Wiskundige Geletterdheid Gr 11 - Klassifikasie van data
Support Vector Machines (SVM) - the basics | simply explained
5.0 / 5 (0 votes)
