BERT Neural Network - EXPLAINED!
Summary
TLDRThis video provides an in-depth exploration of BERT (Bidirectional Encoder Representations from Transformers), a revolutionary model in natural language processing (NLP). It discusses the transformer architecture behind BERT, which enhances language understanding by processing words in parallel. The training process is explained in two phases: pre-training, where BERT learns general language patterns through tasks like Masked Language Modeling and Next Sentence Prediction, and fine-tuning, where it is adapted for specific tasks such as question answering or sentiment analysis. The video also covers BERT’s use of embeddings and the model’s efficiency in solving diverse NLP problems.
Takeaways
- 😀 BERT is a transformer-based architecture designed to understand language and context.
- 😀 Unlike previous models, BERT uses a bidirectional approach, processing words in context from both directions simultaneously.
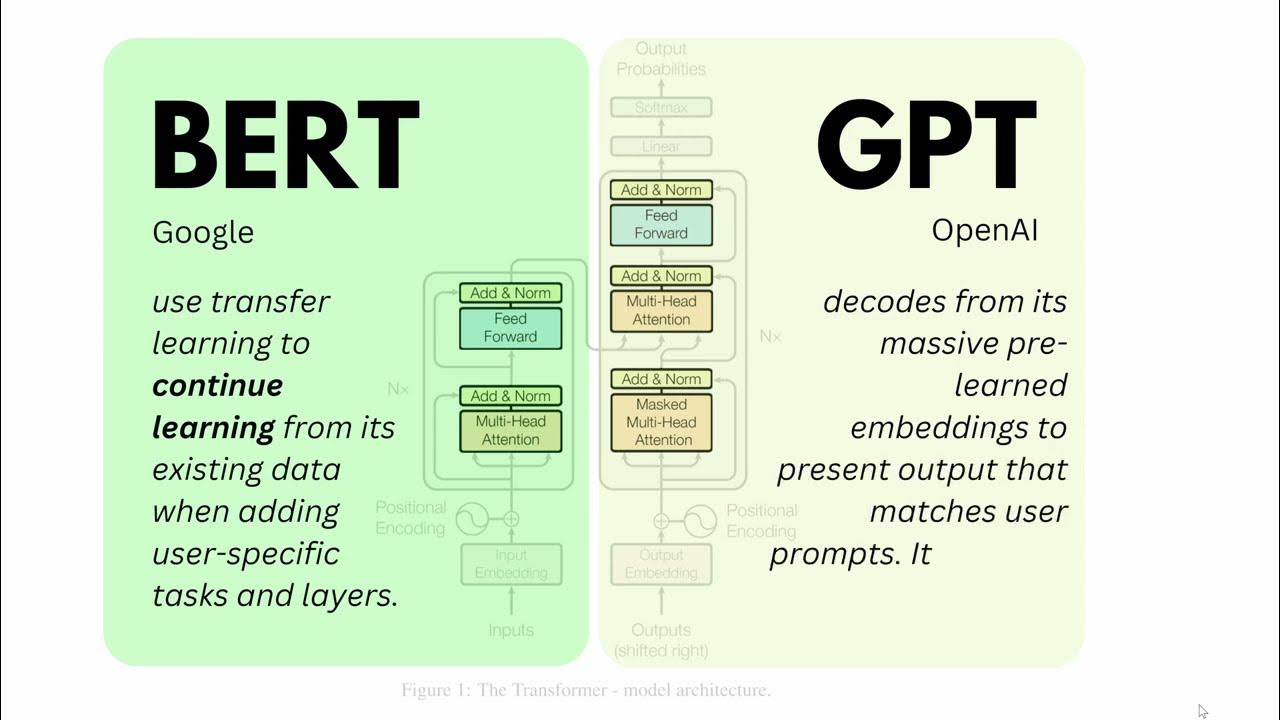
- 😀 The transformer architecture that BERT is built upon consists of an encoder-decoder structure, but BERT uses only the encoder.
- 😀 The two main phases of BERT's training are pre-training and fine-tuning.
- 😀 Pre-training involves two tasks: Masked Language Modeling (MLM) and Next Sentence Prediction (NSP).
- 😀 In MLM, BERT predicts missing words in a sentence, helping it learn word meanings and context.
- 😀 NSP helps BERT understand the relationship between two sentences, enhancing its contextual understanding across sentences.
- 😀 Fine-tuning adapts BERT for specific tasks like question answering or sentiment analysis by replacing the output layer and training with labeled data.
- 😀 BERT’s embeddings are created using token embeddings, segment embeddings (for sentence identification), and position embeddings (for word order).
- 😀 BERT achieves high performance on a variety of NLP tasks, including question answering, text classification, and named entity recognition.
- 😀 Fine-tuning BERT is relatively quick because only the output layer is learned from scratch, while the rest of the model parameters are fine-tuned.
Q & A
What is BERT and how does it relate to transformers?
-BERT (Bidirectional Encoder Representations from Transformers) is a deep learning model based on the transformer architecture. Unlike older models like LSTM, which process data sequentially, BERT processes input words simultaneously, making it faster and more efficient in learning word context.
What problems did LSTM networks face that BERT addresses?
-LSTM networks were slow to train, as they processed words sequentially. This made it time-consuming for the network to learn the context of words. Additionally, even bi-directional LSTMs struggled with capturing the true context, as they processed left-to-right and right-to-left contexts separately.
What are the main components of a transformer model?
-The transformer model consists of two main components: the encoder, which processes the input language, and the decoder, which generates the output. BERT uses only the encoder for tasks related to language understanding.
How does BERT handle context differently than other models?
-BERT processes words simultaneously, allowing it to understand context from both directions at once. This bidirectional learning enables BERT to capture a deeper and more accurate understanding of word meanings within sentences.
What tasks can BERT be used for?
-BERT can be used for a wide variety of NLP tasks, including language translation, sentiment analysis, question answering, text summarization, and more. Its ability to understand language context makes it versatile across different domains.
What is the difference between pre-training and fine-tuning in BERT?
-Pre-training involves teaching BERT to understand general language patterns through unsupervised tasks like masked language modeling and next sentence prediction. Fine-tuning, on the other hand, adapts the model for specific tasks by modifying the output layer and training on labeled datasets.
What is masked language modeling (MLM) and how does it help BERT?
-Masked language modeling (MLM) is a pre-training task where BERT randomly masks some words in a sentence and trains the model to predict them. This helps BERT learn bidirectional context, improving its understanding of word meanings within sentences.
How does next sentence prediction (NSP) improve BERT's understanding?
-Next sentence prediction (NSP) helps BERT learn the relationship between sentences by determining whether the second sentence logically follows the first. This task enhances BERT’s ability to understand context across multiple sentences.
What is the role of embeddings in BERT?
-Embeddings in BERT are vectors that represent words. They are constructed from token embeddings (pre-trained word piece embeddings), position embeddings (to preserve word order), and segment embeddings (to differentiate sentences). These combined embeddings are fed into the model for processing.
How does fine-tuning work in BERT for specific tasks like question answering?
-In fine-tuning, BERT’s output layer is replaced with a task-specific output layer. For question answering, the model is trained on a dataset where the input consists of a question and a passage containing the answer. BERT learns to output the start and end tokens of the answer.
What is the difference between BERT Base and BERT Large models?
-BERT Base has 110 million parameters, while BERT Large has 340 million parameters. The larger model generally achieves higher accuracy but requires more computational resources and training time.
Outlines

此内容仅限付费用户访问。 请升级后访问。
立即升级Mindmap

此内容仅限付费用户访问。 请升级后访问。
立即升级Keywords

此内容仅限付费用户访问。 请升级后访问。
立即升级Highlights

此内容仅限付费用户访问。 请升级后访问。
立即升级Transcripts

此内容仅限付费用户访问。 请升级后访问。
立即升级浏览更多相关视频
BERT and GPT in Language Models like ChatGPT or BLOOM | EASY Tutorial on Large Language Models LLM

Practical Intro to NLP 23: Evolution of word vectors Part 2 - Embeddings and Sentence Transformers

Prerequisites For NLP Live Community Session For ML And DL

Building a new tokenizer

Transformers, explained: Understand the model behind GPT, BERT, and T5

🔥 NEW LLama Embedding for Fast NLP💥 Llama-based Lightweight NLP Toolkit 💥
5.0 / 5 (0 votes)
