What Could Go Wrong with a GraphQL Query and Can OpenTelemetry Help? - Budhaditya Bhattacharya, Tyk
Summary
TLDRThe speaker, a developer advocate, discusses common issues with GraphQL queries and how Open Telemetry can address them. They explore challenges like over-fetching, under-fetching, and the 'N+1' problem, demonstrating how to monitor and troubleshoot using Open Telemetry in a Node.js environment. The talk also covers the importance of semantic conventions and manual instrumentation for better observability, concluding with resources for further learning.
Takeaways
- 😀 The speaker is starting the session early and expects a loud applause at the end, setting a positive and engaging tone for the audience.
- 🌐 The talk focuses on potential issues with GraphQL queries and how Open Telemetry can help address them, providing a practical approach to API management.
- 🔍 The speaker, a developer advocate at Tyk, discusses the challenges and solutions related to GraphQL and Open Telemetry, indicating the relevance of their expertise.
- 📈 The importance of monitoring and observability in production environments is highlighted, emphasizing the need for visibility into the health and performance of distributed systems.
- 📊 The RED method (Rate, Errors, Duration) is introduced as a strategy for gaining insights into service health, suggesting a systematic approach to monitoring.
- 🛠 Open Telemetry is positioned as a tool for instrumenting GraphQL services to capture distributed traces, which is crucial for troubleshooting and performance analysis.
- 🔄 The speaker illustrates the use of Open Telemetry with a Node.js example, showing practical steps to integrate it with a GraphQL service for better observability.
- 📈 The integration of Open Telemetry with Prometheus and Jaeger is discussed, demonstrating how to visualize and analyze metrics for GraphQL services.
- 🚦 The challenges of HTTP status codes in GraphQL are addressed, where a 200 OK response might not always indicate success, and the need for deeper inspection is emphasized.
- 🔍 The 'N+1' problem in GraphQL is identified as a common performance issue, and the use of data loaders is suggested as a solution to prevent excessive database queries.
- 🔄 The importance of granular performance profiling is stressed, moving beyond average metrics to understand the specific needs and challenges of different clients and queries.
Q & A
What is the main topic of the speaker's presentation?
-The main topic of the presentation is discussing what could go wrong with GraphQL queries and how Open Telemetry can help address these issues.
Why might a speaker choose to start a session early?
-The speaker starts the session early because it is the last session of the day and they expect the audience to be with them for the journey over the next 15 to 20 minutes.
What is the speaker's professional background?
-The speaker, Buddha, is a Developer Advocate at Tyk, a cloud-native API management platform. They are also the chairperson of the Open API initiatives business governance board.
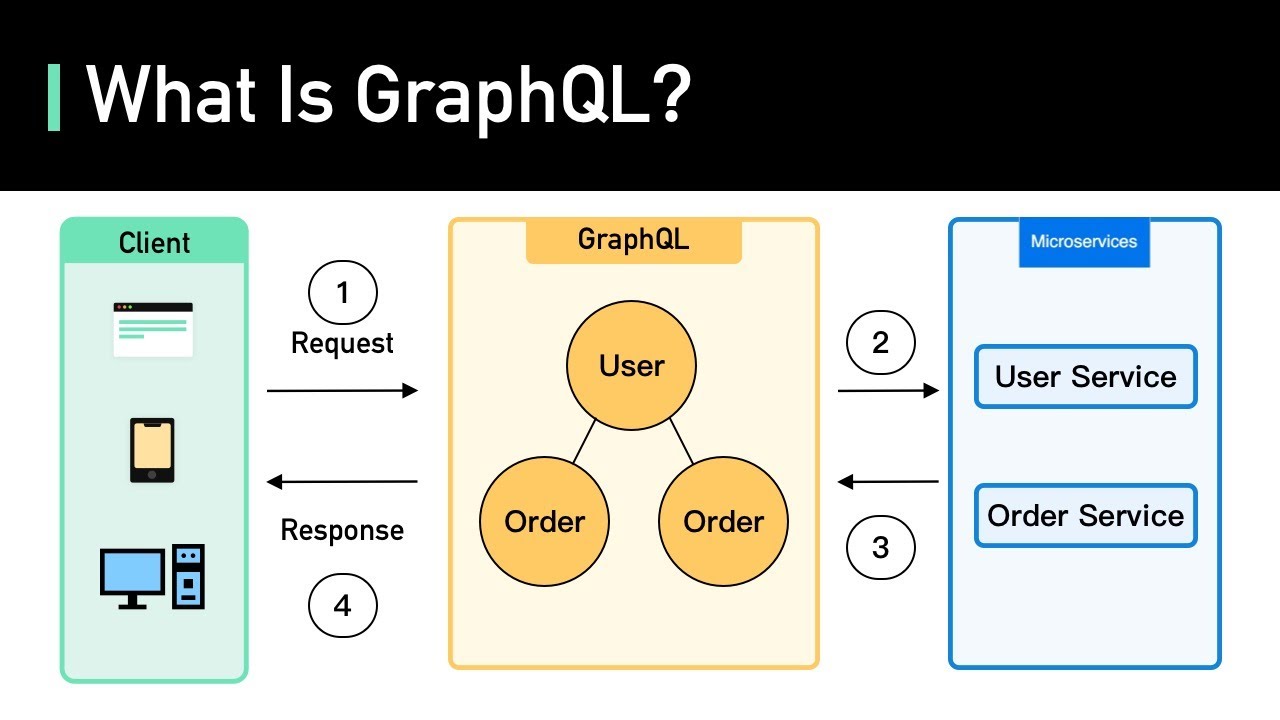
What is GraphQL and how does it differ from REST?
-GraphQL is a query language for APIs and a runtime for fulfilling those queries with existing data. It differs from REST in that it allows clients to request specific pieces of information, addressing issues like over-fetching and under-fetching that are common with REST.
What is the purpose of an API Gateway in the context of GraphQL?
-An API Gateway acts as a mediator between different security protocols, governance practices, and as an entry point for observability, especially when working with GraphQL to ensure reliability and stability in deployment.
What is the RED method in monitoring and what does it stand for?
-The RED method is a monitoring strategy used to gain insight into the health and performance of distributed systems. RED stands for Rate, Errors, and Duration.
How can Open Telemetry be integrated into a GraphQL service?
-Open Telemetry can be integrated by instrumenting the GraphQL service with Open Telemetry to get distributed traces. This involves using specific implementations for the technology stack, such as Node.js, and exporting spans to the Open Telemetry collector.
What are some common performance issues with GraphQL?
-Some common performance issues with GraphQL include the N+1 problem, where multiple requests are made for each resource in a response, leading to inefficient data fetching and high latency.
What is the significance of the 'graphql.error.message' attribute added manually to the GraphQL service?
-The 'graphql.error.message' attribute is significant as it allows for capturing specific GraphQL errors within the spans, providing more detailed information for troubleshooting issues that are not indicated by HTTP status codes.
How can the N+1 problem be detected and addressed using Open Telemetry?
-The N+1 problem can be detected by monitoring the number of outgoing requests for a GraphQL query. If the number is unusually high, it may indicate an N+1 issue. Open Telemetry can help identify this by providing detailed tracing information, and it can be addressed by implementing data loaders or other optimization techniques.
What resources does the speaker provide for further learning about Open Telemetry and API observability?
-The speaker provides courses on Open Telemetry API observability and API platforms, and encourages attendees to connect with them on LinkedIn for more information.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowBrowse More Related Video

Data Loaders (the N+1 problem) - GRAPHQL API IN .NET w/ HOT CHOCOLATE #6

GopherCon 2020: Ted Young - The Fundamentals of OpenTelemetry

Using Native OpenTelemetry Instrumentation to Make Client Libraries Better - Liudmila Molkova
What Is GraphQL? REST vs. GraphQL

Golang GraphQL Tutorial - Intro

GraphQL: The Documentary
5.0 / 5 (0 votes)