Python RAG Tutorial (with Local LLMs): AI For Your PDFs
Summary
TLDRThis tutorial video guides viewers on building a Python RAG application for querying information from a set of PDFs using natural language. It covers advanced features like running the app locally with open-source LLMs, updating the vector database, and evaluating AI responses. The host demonstrates how to index data sources, utilize embeddings, and integrate with local or online models for generating natural language responses, concluding with unit testing strategies to ensure quality.
Takeaways
- 📚 The video demonstrates building a Python RAG (Retrieval-Augmented Generation) application for querying information from a set of PDFs, specifically board game instruction manuals.
- 🔍 It introduces advanced features for the RAG application, including running it locally with open-source LLMs (Large Language Models) and updating the vector database without rebuilding from scratch.
- 🛠️ The tutorial covers the process of setting up the application, from gathering documents to using a PDF document loader and splitting the content into smaller chunks for indexing.
- 📈 The importance of creating embeddings for each chunk of text is highlighted, as these serve as keys in the vector database and are crucial for the RAG system to function effectively.
- 🔧 The video explains how to use ChromaDB as the vector database and how to tag each chunk with a unique ID to manage updates and additions to the database.
- 🔄 It shows how to detect new documents and update the database by checking for unique IDs, allowing for incremental updates instead of full rebuilds.
- 🤖 The application uses an LLM to generate responses to queries, with the video providing a demonstration of how the system formulates answers using context from the PDFs.
- 🔬 The script discusses the evaluation of the AI-generated responses through unit testing, using an LLM to judge the equivalence of expected and actual responses.
- 🔗 The video provides a GitHub link for those interested in accessing the full project code and running the application themselves.
- 💡 The tutorial encourages viewers to suggest further topics for future videos, such as deploying the application to the cloud, fostering a community of learners.
- 🚀 The video concludes by emphasizing the learning outcomes, such as using different LLMs, updating databases, and testing application quality, and invites viewers to engage with the content.
Q & A
What is the primary purpose of the application built in the video?
-The application is designed to allow users to ask natural language questions about a set of PDFs, specifically board game instruction manuals, and receive answers along with references to the source material.
What does RAG stand for and what is its role in the application?
-RAG stands for Retrieval, Augmented Generation. It is a method used to index a data source so that it can be combined with a Large Language Model (LLM) to provide an AI chat experience leveraging the indexed data.
How does the application handle the process of updating the vector database with new entries?
-The application updates the vector database by first giving each chunk of text a unique and deterministic ID based on the source file path, page number, and chunk number. It then checks if the chunk exists in the database; if not, it adds the new chunk.
What is the significance of embeddings in the context of this application?
-Embeddings are a key component in the application, serving as a numerical representation of the text chunks and queries. They are used to fetch the most relevant entries from the vector database when a question is asked.
What is the role of the Ollama server in the application?
-The Ollama server is used to run open-source LLMs locally on the user's computer. It provides the capability to generate responses using a local model, which can be more efficient and cost-effective than relying solely on online models.
How does the application handle the case of adding new PDFs or pages to an existing PDF?
-The application detects new documents or pages by comparing the unique IDs of the existing chunks in the database with the new chunks derived from the added PDFs or pages. Only the new chunks that do not exist in the database are added.
What is the significance of using a unique but deterministic ID for each chunk?
-Using a unique but deterministic ID for each chunk ensures that the application can accurately identify whether a chunk already exists in the database, allowing for efficient updates and avoiding duplication.
What is ChromaDB and how does it fit into the application?
-ChromaDB is a vector database used in the application to store the embeddings of the text chunks. It allows for efficient retrieval of the most relevant chunks when a query is made.
How does the application evaluate the quality of AI-generated responses?
-The application uses unit testing with a helper function that creates a prompt for an LLM to judge whether the expected response and the actual response are equivalent in meaning, despite potential differences in wording.
What is the importance of testing the application with both positive and negative test cases?
-Testing with both positive and negative cases helps ensure the robustness of the application. Positive cases confirm that the application works correctly with expected inputs, while negative cases verify that it can correctly identify and handle incorrect or unexpected inputs.
How can users access the full project code and run the application themselves?
-Users can access the full project code by visiting the GitHub link provided in the video description. This allows them to download the code and run the application end-to-end as demonstrated in the video.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowBrowse More Related Video
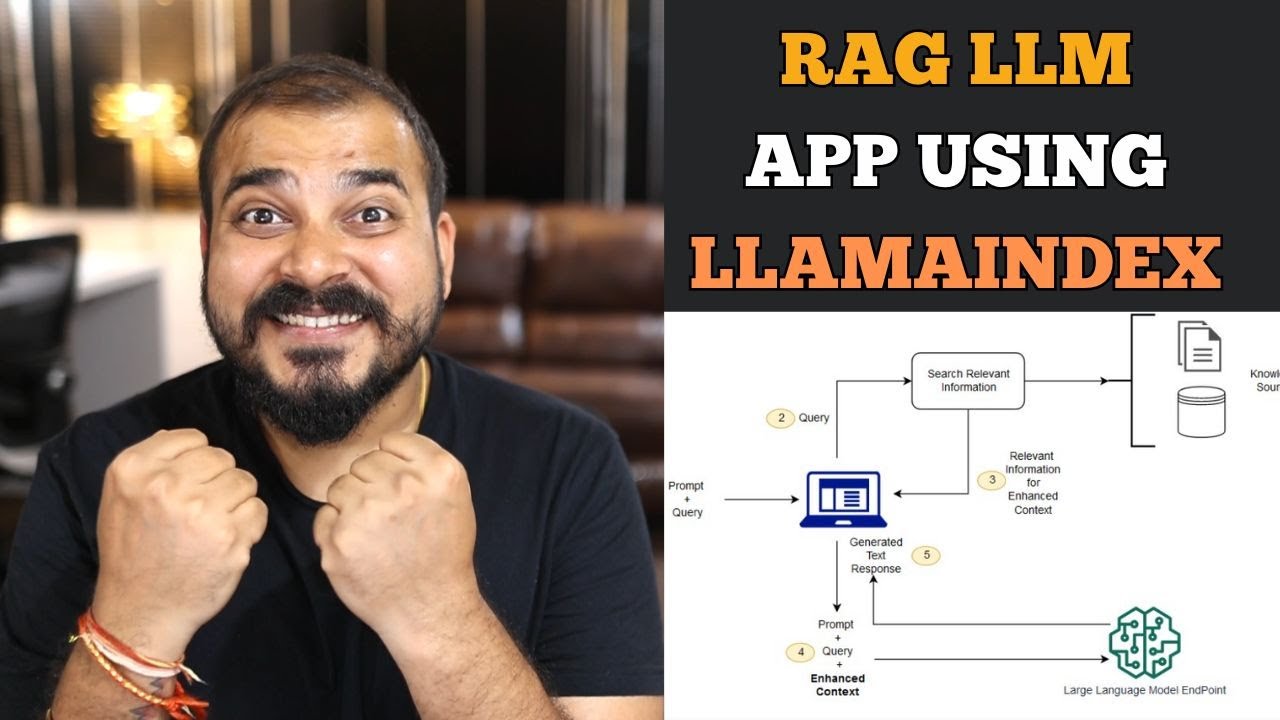
End to end RAG LLM App Using Llamaindex and OpenAI- Indexing and Querying Multiple pdf's

Easy 100% Local RAG Tutorial (Ollama) + Full Code

Step-by-Step Guide to Building a RAG LLM App with LLamA2 and LLaMAindex

How to chat with your PDFs using local Large Language Models [Ollama RAG]
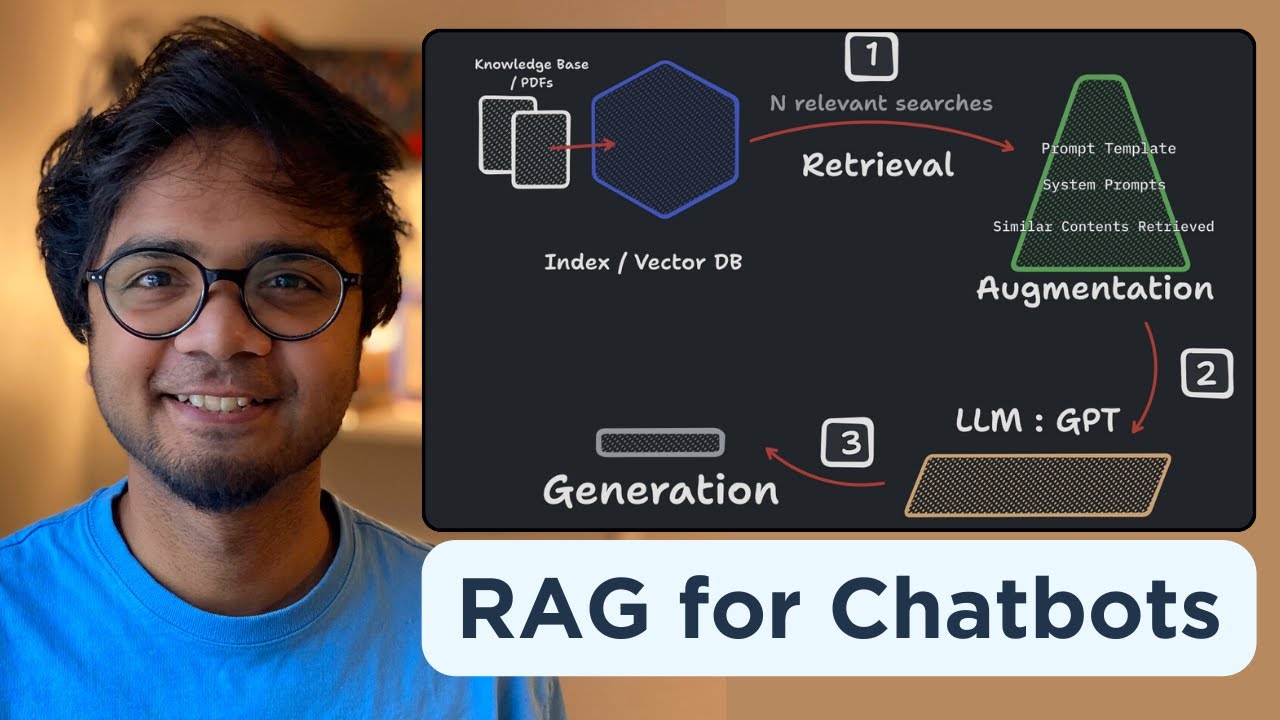
Build your own RAG (retrieval augmented generation) AI Chatbot using Python | Simple walkthrough

Retrieval Augmented Generation - Neural NebulAI Episode 9
5.0 / 5 (0 votes)