4.5 Regularized Autoencoders [Denoising, Contractive, Variational]
Summary
TLDRThis video explores regularization techniques in unsupervised learning, focusing on three types of autoencoders: denoising, contractive, and variational. The goal of regularization is to impose specific properties on the hidden representations of data, enhancing their usefulness for various tasks. Denoising autoencoders clean noisy data, while contractive autoencoders dampen irrelevant changes in the input. Variational autoencoders, in contrast, introduce stochastic hidden representations and are widely used in generative models. The video compares these methods, highlighting their differences in noise resistance and their applications in image generation and data reconstruction.
Takeaways
- 😀 Regularization in unsupervised learning differs from supervised applications, with the goal often being to learn representations with specific properties.
- 😀 In unsupervised learning, overfitting is less of a concern compared to supervised learning, as the target data in unsupervised tasks is often more complex and high-dimensional.
- 😀 Autoencoders are key unsupervised models that require regularization, especially when using high-dimensional hidden layers to prevent the model from simply copying inputs.
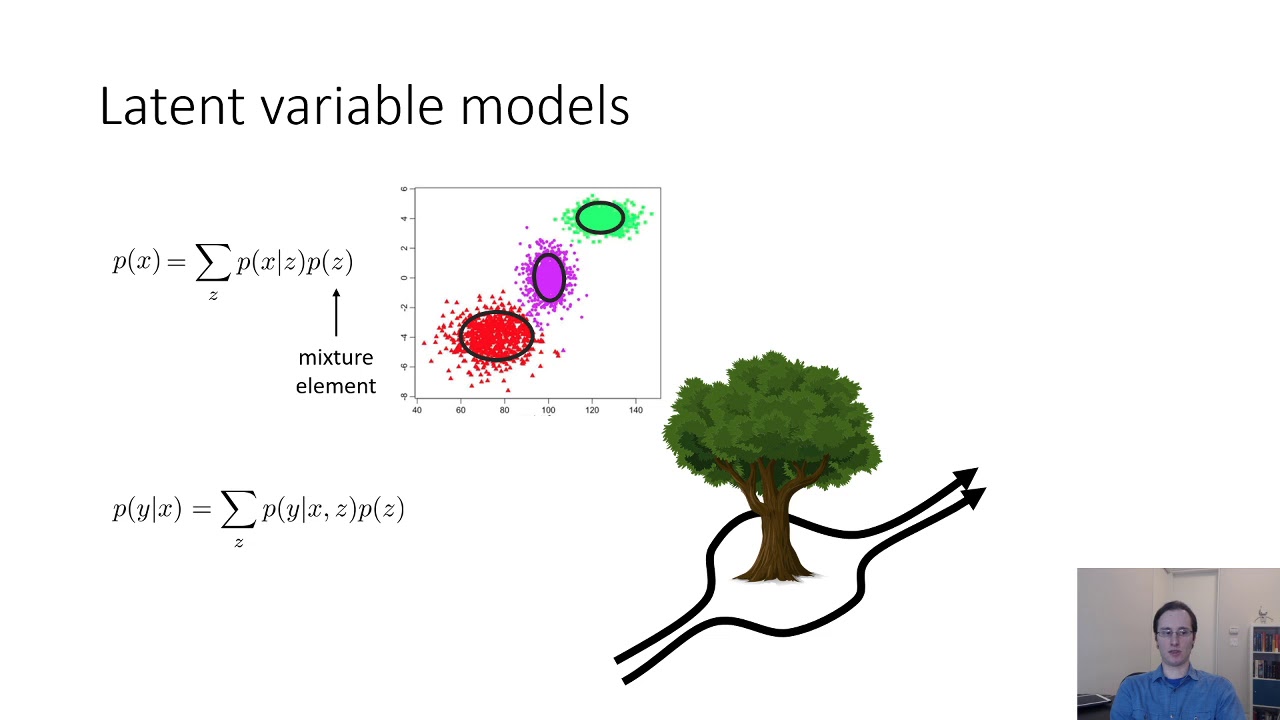
- 😀 Sparse feature learning in autoencoders involves using more hidden units than input units, with L1 penalties added to encourage sparse activation.
- 😀 Top K encoders enforce sparsity by keeping only the top K activations in the hidden layer, essentially creating an adaptive threshold for the activations.
- 😀 Denoising autoencoders are useful for removing noise from corrupted data by training on noisy inputs and clean outputs, with common noise types being Gaussian and masking noise.
- 😀 The denoising autoencoder's ability to learn from noisy data is similar to regularized Singular Value Decomposition (SVD), specifically when Gaussian noise is added.
- 😀 Contractive autoencoders apply regularization by penalizing the Jacobian (the gradient of the hidden layer with respect to inputs) to prevent the hidden representation from changing drastically due to small input noise.
- 😀 Contractive and denoising autoencoders both aim for robustness to input noise, but they achieve this in different ways: one through penalizing the Jacobian and the other through adding noise to the input.
- 😀 Variational autoencoders (VAEs) create stochastic hidden representations by sampling from a Gaussian distribution, and they regularize this hidden distribution to resemble a unit Gaussian.
- 😀 The VAE's regularization ensures that the hidden representation remains consistent with a unit Gaussian, enabling it to generate meaningful samples when decoding from this distribution.
- 😀 VAEs are often used for generative tasks, such as creating variations of images (e.g., digit generation from the MNIST dataset), by sampling from the learned latent space and decoding back into data.
Q & A
What is the primary focus of the lecture discussed in the transcript?
-The lecture focuses on regularization techniques in unsupervised applications, specifically in the context of autoencoders. It explains how regularization is used to control the hidden representations of autoencoders to have desired properties like sparsity, robustness to noise, and smoothness.
What is the difference between supervised and unsupervised applications regarding overfitting?
-In supervised applications, overfitting is a bigger concern because the model is typically trying to predict a single target value (e.g., a class label). In unsupervised applications, the model learns the entire data distribution, which involves more complex structures and therefore leads to less frequent overfitting.
What role does the dimensionality of the hidden layer play in overfitting for autoencoders?
-The dimensionality of the hidden layer influences the tendency of overfitting. If the hidden layer has too many units compared to the input data, the autoencoder might simply copy the input rather than learning meaningful features. Regularization techniques are used to control this overfitting risk.
How does sparse feature learning work in autoencoders?
-Sparse feature learning in autoencoders involves using a larger number of hidden units than the input units, but with a sparsity constraint. This constraint, often implemented via an L1 penalty, ensures that only a small number of hidden units activate for each input, leading to a sparse representation.
What is the difference between sparse feature learning and top K encoders?
-Sparse feature learning encourages most hidden units to remain inactive (zero), with only a few units activating for each input. Top K encoders, on the other hand, select only the top K most activated hidden units during both forward and backward propagation, effectively creating a sparse representation without needing L1 penalties.
What is a denoising autoencoder, and how is it trained?
-A denoising autoencoder is trained by adding noise to the input data and forcing the network to reconstruct the clean, noise-free version of the data. It is particularly useful for tasks like denoising images or cleaning corrupted data. Different types of noise, such as Gaussian or masking noise, can be added depending on the data type.
How does Gaussian noise affect autoencoders in the context of denoising?
-When Gaussian noise is added to the input of an autoencoder, it essentially regularizes the model by forcing it to learn to map noisy data back to its original manifold. If you have a single-layer autoencoder with linear activations, this results in a regularized Singular Value Decomposition (SVD).
What is the goal of a contractive autoencoder and how does it regularize the model?
-The goal of a contractive autoencoder is to make the hidden representation insensitive to small changes in the input data. This is achieved by adding a regularization term that penalizes the Jacobian of the hidden-to-input mapping, preventing large changes in the hidden layer from small input perturbations.
How do contractive and denoising autoencoders achieve similar goals?
-Both contractive and denoising autoencoders aim for robustness against noise, but they do so in different ways. Denoising autoencoders add noise to the input and learn to map noisy inputs back to the clean data, while contractive autoencoders regularize the hidden representation to prevent significant changes from small input changes.
What makes variational autoencoders (VAEs) different from other types of autoencoders?
-Variational autoencoders differ from other autoencoders in that they introduce a stochastic hidden representation. Instead of having a deterministic encoding, VAEs model the hidden layer as a distribution (typically Gaussian), and they sample from this distribution to reconstruct the input data. This stochastic nature makes VAEs suitable for generative tasks.
What is the role of the KL divergence in variational autoencoders?
-The KL divergence in VAEs is used as a regularization term to push the distribution of the hidden representation (mean and standard deviation) towards a unit Gaussian. This regularization ensures that the learned hidden space has desirable properties, making it suitable for sampling and generative tasks.
Why are VAEs more suitable for generating new data compared to other types of autoencoders?
-VAEs are well-suited for generating new data because their hidden representations are probabilistic, and the decoder learns to generate data from a distribution. By sampling from this distribution, VAEs can produce new, previously unseen data points that are similar to the training data, whereas other autoencoders typically do not support this type of generative capability.
How do VAEs differ from GANs (Generative Adversarial Networks) in terms of image generation?
-VAEs and GANs are both used for generative tasks, but they have key differences. VAEs use a probabilistic approach to learn a continuous latent space, allowing for smooth sampling and generation of new data. GANs, on the other hand, use a discriminator and generator network to create highly realistic images, but they tend to be harder to train and can result in higher-quality output compared to VAEs.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowBrowse More Related Video
CS 285: Lecture 18, Variational Inference, Part 1

90 - Application of Autoencoders - Image colorization

Classification & Regression.

What is Semi-Supervised Learning?

Types of Machine Learning for Beginners | Types of Machine learning in Hindi | Types of ML in Depth

Aprendizado de Máquina: Supervisionado e Não Supervisionado
5.0 / 5 (0 votes)