Presentasi Komputasi Lanjut & Big Data : Arsitektur Komputasi Paralel
Summary
TLDRThe presentation discusses various aspects of computer architecture and memory systems. It introduces the taxonomy of computer architectures, such as instruction data stream types (single, multiple, and SIMD) and the differences between shared and distributed memory architectures. The discussion then shifts to GPU technology, tracing its evolution from fixed-function graphics pipelines to programmable GPUs. The importance of GPUs in scientific computing is highlighted, with a focus on how they accelerate computational tasks by offloading work from the CPU. The presentation concludes with references and acknowledgments.
Takeaways
- 😀 The presentation introduces a discussion on taxonomy and computer memory architecture.
- 😀 Taxonomy in computer architecture was first classified by Michael in 1966, focusing on instruction types and data flow.
- 😀 There are four types of computer architectures: SISD (Single Instruction Single Data), SIMD (Single Instruction Multiple Data), MIMD (Multiple Instruction Multiple Data), and NIND (Multiple Instruction Multiple Data with different processors).
- 😀 SIMD allows for parallel processing with one instruction on multiple data streams, such as in processors like GPUs.
- 😀 MIMD uses multiple processors that can perform different instructions on different data streams, offering greater flexibility.
- 😀 The memory architecture of computers can either be shared (Uniform and Non-Uniform Memory Access) or distributed.
- 😀 In shared memory, multiple processors can access the same memory space, but the memory access pattern differs between uniform and non-uniform access.
- 😀 Distributed memory systems have local memory for each processor, requiring interconnect networks for communication.
- 😀 Hybrid memory systems combine shared and distributed architectures to optimize memory usage.
- 😀 The evolution of GPUs began with fixed-function graphics pipelines, but later Nvidia modified GPUs for general scientific computing purposes.
- 😀 GPUs enhance computational power by accelerating parallel tasks, using hundreds or thousands of smaller processors, compared to CPUs which typically have fewer, more powerful cores.
Q & A
What is the main focus of the presentation in the transcript?
-The main focus of the presentation is on computer architecture, specifically the classification of computer systems based on the instruction types and data processing. It also covers memory architecture in computers, including shared memory, distributed memory, and hybrid memory systems, and touches on the history and function of GPUs.
Who are the presenters in the group?
-The presenters in the group are Yandra Windonesia, Alvin Fairosani, and the speaker, Palestina.
What does the term 'taxonomy' refer to in computer architecture?
-In computer architecture, 'taxonomy' refers to the classification system created by Michael in 1966, which categorizes computers based on their data processing and instruction execution capabilities.
Can you explain the 'instruction stream' and how it affects computer architecture?
-The instruction stream in computer architecture refers to the flow of instructions processed by the computer. It affects how a system is classified, as it determines whether the system can process multiple instructions at once, whether it operates on a single instruction stream, or processes parallel data streams.
What are the different classifications of computer systems mentioned in the transcript?
-The computer systems are classified into four types: (1) Single Instruction, Single Data (SISD), where a computer can process one instruction on one data stream, (2) Multiple Instruction, Single Data (MISD), which can handle multiple instructions but only one data stream, (3) Single Instruction, Multiple Data (SIMD), where one instruction operates on multiple data streams, and (4) Multiple Instruction, Multiple Data (MIMD), where multiple processors execute different instructions on different data streams.
What is the difference between shared memory and distributed memory in parallel computing?
-In shared memory systems, multiple processors can access a single memory space. This type of architecture is characterized by either Uniform Memory Access (UMA), where all processors have equal access to memory, or Non-Uniform Memory Access (NUMA), where memory access times vary. In distributed memory systems, each processor has its own local memory, and processors communicate over a network to share information.
What is Hybrid Distributed Shared Memory architecture?
-Hybrid Distributed Shared Memory architecture combines both shared memory and distributed memory systems, allowing processors to share memory but also having local memory specific to each processor, which is interconnected via a network.
How does Uniform Memory Access (UMA) differ from Non-Uniform Memory Access (NUMA)?
-In UMA, all processors access the shared memory at the same speed, while in NUMA, some processors have faster access to certain regions of memory, leading to different performance characteristics depending on the processor's location relative to the memory.
What is the historical development of GPUs as mentioned in the transcript?
-The history of GPUs began with the development of graphics pipelines with fixed functions. Over time, GPUs became programmable, leading to Nvidia introducing the first GPU. Between 1999 and 2000, researchers in fields like medical imaging and electromagnetic studies started utilizing GPUs to accelerate scientific applications.
What is the role of a GPU in computational tasks, especially in comparison to a CPU?
-A GPU accelerates computation by offloading tasks from the CPU. While a CPU handles general-purpose tasks with fewer cores (typically 4-8), a GPU has hundreds or even thousands of smaller cores designed for parallel processing, making it much more efficient for handling large-scale, repetitive tasks like rendering graphics or running scientific simulations.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowBrowse More Related Video

Processor vs Ram

1. Arsitektur Komputer - Organisasi dan Arsitektur Komputer
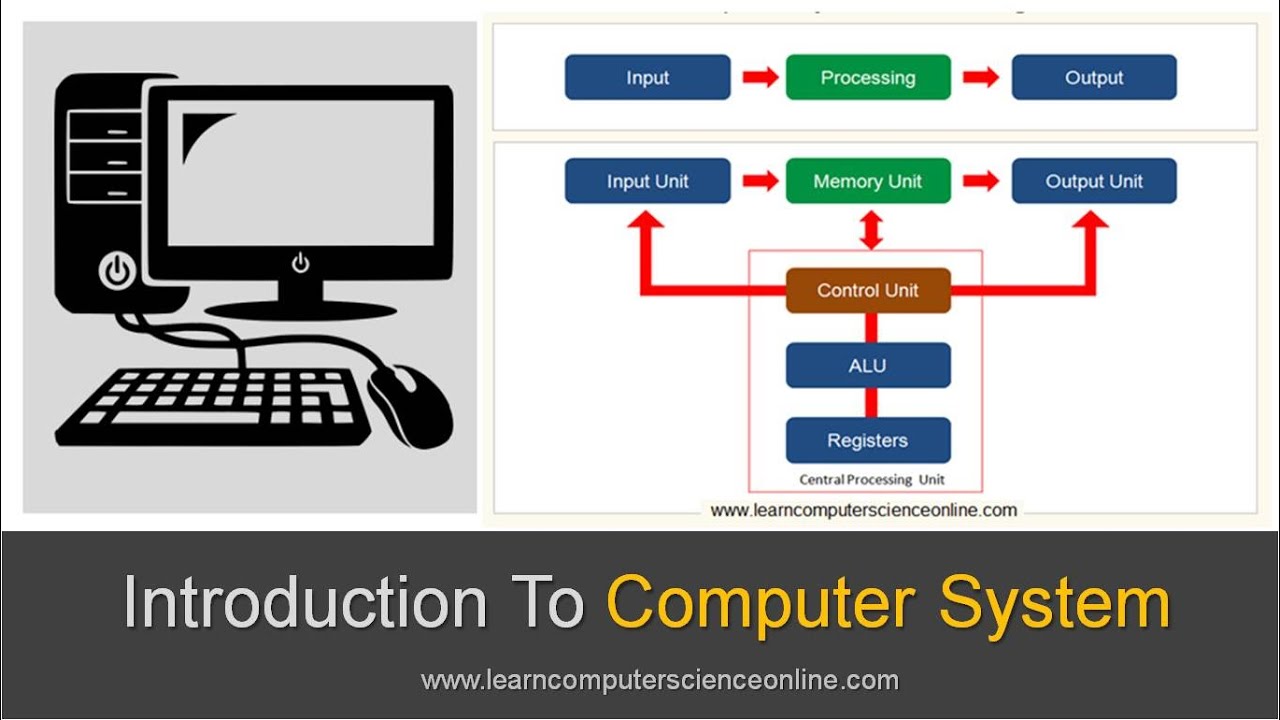
Introduction To Computer System | Beginners Complete Introduction To Computer System

Sistem Operasi - Manajemen Memori

Computer Architecture Important Questions | BCA 2nd Sem MAKAUT 2025 | Get 100/100 #makaut #bca2ndsem

Associative Mapping
5.0 / 5 (0 votes)