Whitepaper Companion Podcast - Embeddings & Vector Stores
Summary
TLDRThis deep dive explores the transformative power of embeddings and vector stores in data science, particularly for Kaggle competitions. It covers the basics of embeddings—how they convert complex data into vectors for better processing—and the various types, including text, image, and multimodal embeddings. The video also highlights practical applications, such as semantic search, recommendation systems, anomaly detection, and retrieval-augmented generation for large language models (LLMs). It emphasizes the importance of selecting the right tools and databases for specific tasks, as well as the evolving role of embeddings in the future of AI and data processing.
Takeaways
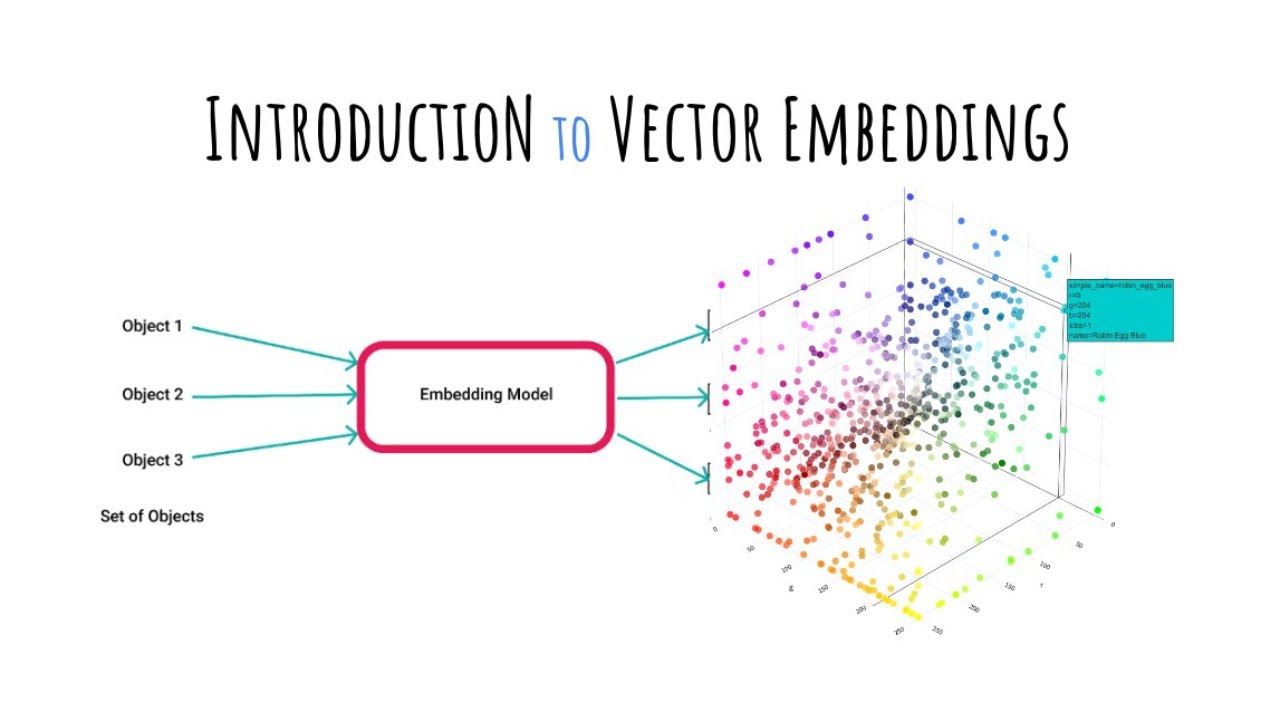
- 😀 Embeddings translate real-world data (like text, images, and videos) into numerical vectors that computers can process and compare, enabling more meaningful data analysis.
- 😀 Text embeddings, such as Word2Vec, GloVe, and FastText, help represent words based on their context and relationships, which is crucial for natural language processing tasks in competitions.
- 😀 Pre-trained language models like BERT, T5, and PaLM have revolutionized document embeddings by considering the entire context of a sentence, enabling more nuanced understanding.
- 😀 CNNs (Convolutional Neural Networks) are used for image embeddings, translating visual features into numerical vectors that represent images, allowing for meaningful comparisons between them.
- 😀 Multimodal embeddings combine different types of data (e.g., text, images, audio) to enhance search and analysis across diverse datasets, such as those in Kaggle competitions.
- 😀 Vector search allows for searching by meaning, not just keywords, enabling better semantic matching across various data types, such as text, images, and audio.
- 😀 Approximate nearest neighbor (ANN) search algorithms, like Locality Sensitive Hashing (LSH) and tree-based algorithms (KD trees, ball trees), speed up vector searches by grouping similar data points.
- 😀 Advanced algorithms like HNSW (Hierarchical Navigable Small Worlds) and SCAN (Scalable Approximate Nearest Neighbor) handle massive, high-dimensional datasets efficiently, ensuring fast and accurate searches.
- 😀 Specialized vector databases like Pinecone, Weaviate, and ChromaDB are designed for managing large-scale embeddings and support fast, flexible searches, filtering, and metadata management.
- 😀 Retrieval-augmented generation (RAG) combines embeddings, vector search, and large language models (LLMs) to improve the accuracy and reliability of generated content by allowing LLMs to access external knowledge bases.
- 😀 Embeddings can be used for anomaly detection by capturing the normal patterns in data (e.g., sensor readings, financial transactions) and flagging deviations as anomalies, even without specific prior knowledge.
- 😀 As the field evolves, vector stores are becoming essential for data science applications like search, recommendation systems, and LLM integration, but choosing the right database depends on the use case and resource requirements.
Q & A
What are embeddings, and why are they important in data science?
-Embeddings are numerical representations of data (such as text, images, or videos) that allow computers to understand complex information in a way that is computationally efficient. They are crucial in data science because they transform data into a format that can be processed and compared, enabling advancements in tasks like search, recommendation systems, and machine learning models.
How do embeddings help in Kaggler competitions?
-Embeddings are particularly helpful in Kaggler competitions because they allow for faster processing and storage of massive data sets. They are key to optimizing tasks like retrieval systems, recommendation engines, and predictive models, all of which are common in these competitions.
What is the difference between traditional word representations (like TF-IDF) and modern embeddings techniques like BERT?
-Traditional methods like TF-IDF treat words independently and only consider word frequency, missing the context and relationships between words. Modern techniques like BERT, on the other hand, use transformer architectures that understand words in context, capturing the grammar, flow, and semantic meaning of entire sentences or documents.
How do convolutional neural networks (CNNs) contribute to image embeddings?
-CNNs are used in image recognition by learning to extract key features from images. Once the CNN identifies these features, they are transformed into a numerical vector, or image embedding, which allows the image to be compared and analyzed by computers in the same way as text or other data types.
What are multimodal embeddings, and why are they important?
-Multimodal embeddings combine different types of data, like text, images, audio, or video, into a unified representation. This allows for more powerful analysis and comparison of various data forms, such as finding connections between an image and a text description or analyzing audio and video data together.
What is vector search, and how is it different from traditional keyword search?
-Vector search uses embeddings to search for data based on semantic meaning, not just keywords. For example, instead of searching for the word 'cat,' you could search for documents that discuss cats, even if they use different terms like 'feline' or 'kitten.' This allows for more relevant and contextually accurate results.
How do approximate nearest neighbor (ANN) search methods improve vector search efficiency?
-ANN search techniques, such as locality-sensitive hashing (LSH), KD trees, and hierarchical navigable small worlds (HNSW), are designed to speed up vector search by narrowing down the search space. These methods balance speed and accuracy, enabling faster retrieval of embeddings even in massive data sets.
What role do vector databases play in the world of embeddings and vector search?
-Vector databases are specialized systems designed to store, manage, and query embeddings efficiently. They are optimized for handling large-scale vector data, making search operations fast and enabling features like filtering and metadata management for real-world applications.
What is retrieval-augmented generation (RAG), and how does it improve the use of large language models (LLMs)?
-RAG is a method where large language models (LLMs) retrieve relevant external information in real-time to enhance the generation of text. By using vector search to find the most relevant documents or data, RAG helps LLMs provide more accurate, fact-based responses, reducing hallucinations and improving reliability.
What challenges exist when training embeddings, and how are platforms like TensorFlow Hub and Vertex AI helping?
-Training embeddings can be computationally intensive, especially for large data sets. Platforms like TensorFlow Hub and Vertex AI help by providing pre-trained models that can be used directly or fine-tuned on specific data. This reduces the need for massive computing resources and simplifies the process for data scientists.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowBrowse More Related Video





5.0 / 5 (0 votes)