Live Big Data Project Interview Questions | Project Architecture | Data Pipeline #interview
Summary
TLDRThis video script discusses the implementation of Medallion architecture in data engineering projects, focusing on data processing through bronze, silver, and gold layers. It covers best practices for data extraction, refinement, and validation, including incremental loads, primary key handling, and schema checks. The script also explores concepts like normalization, data modeling with snowflake schema, and the CAP theorem for NoSQL databases. Additionally, it explains hash functions, slowly changing dimensions (SCD), and left joins, particularly left anti joins. Key topics on data quality assurance, performance considerations, and historical data tracking are addressed, offering valuable insights into data processing and analytics.
Takeaways
- 😀 Medallion Architecture consists of three layers: Bronze (raw data), Silver (refined data), and Gold (final business logic applied data).
- 😀 Data quality is a key focus in the project, ensuring that the data is correct by checking for nulls, duplicates, and schema consistency.
- 😀 Incremental data loads are used daily to refresh data, ensuring only new records are appended using techniques like left anti joins.
- 😀 In cases where a primary key is absent, composite keys or high cardinality columns are created to uniquely identify records.
- 😀 Normalization is crucial for reducing data redundancy, and the level of normalization depends on the specific use case—1NF for reporting and 4NF for transactional databases.
- 😀 Snowflake schema is ideal for transactional databases but less suited for reporting due to complex joins and high resource usage.
- 😀 Columnar storage organizes data by columns, improving query performance when only a subset of columns is needed.
- 😀 The CAP theorem emphasizes the trade-off between consistency, availability, and partition tolerance in distributed systems.
- 😀 Hash functions help efficiently distribute transactions across different buckets, ensuring better query performance.
- 😀 Slowly Changing Dimensions (SCD) are used to track data changes over time, with Type 1 keeping only the current version, Type 2 tracking all history, and Type 3 maintaining current and previous versions.
- 😀 Left joins return all records from the left table, while left anti joins return records from the left table that do not have a match in the right table.
Q & A
What is Medallion Architecture and how is it implemented in the project?
-Medallion Architecture in the project is implemented in three layers: Bronze, Silver, and Gold. The Bronze layer stores raw data from sources like files or tables, the Silver layer refines and filters the data by applying business logic, and the Gold layer contains the final processed data, ready for reporting and analytics.
What methods are used to ensure data quality in this project?
-Data quality is ensured through several methods, including incremental loading to capture only new data, null and duplicate checks, ensuring unique identifiers like 'M ID' are consistent, and schema consistency checks to verify the integrity of the data being loaded.
How does incremental loading work in this project, and why is it important?
-Incremental loading ensures that only the latest data is extracted and loaded, which prevents duplication and ensures efficiency. By reading the target table and performing a left anti join, only new records are extracted and appended to the dataset.
How is data handled when no primary key is available for incremental loads?
-In the absence of a primary key, a composite key is created by using a combination of columns that uniquely identify the records. This ensures that the data can still be correctly loaded and tracked for changes.
What is normalization, and why is it important in database design?
-Normalization is the process of organizing data in a way that reduces redundancy and dependency. By breaking data into smaller, related tables, it improves efficiency and data integrity. The importance lies in ensuring data consistency and reducing anomalies in the database.
What are the different normal forms (1NF, 2NF, 3NF, 4NF) and their use cases?
-The normal forms are levels of data normalization: 1NF ensures no repeating groups, 2NF eliminates partial dependencies, 3NF removes transitive dependencies, and 4NF prevents multi-valued dependencies. Higher normal forms are used in transactional databases, while lower forms are used in analytical databases to optimize performance.
What is a snowflake schema, and where is it most applicable?
-A snowflake schema is a normalized database structure where dimension tables are further split into related sub-dimensions. It is best suited for transactional databases where updates are frequent, but it can cause performance issues in reporting databases due to complex joins.
How do columnar databases work and what are their advantages?
-Columnar databases store data by column rather than row, making them highly efficient for read-heavy workloads where only specific columns are queried. This structure allows for faster data retrieval and improved performance in analytical tasks.
What is the CAP theorem and how does it apply to NoSQL databases?
-The CAP theorem states that in a distributed system, only two of the three guarantees—Consistency, Availability, and Partition Tolerance—can be achieved simultaneously. In NoSQL systems, it helps determine trade-offs between these factors based on the needs of the system.
What is a hash function and how does it help in data partitioning?
-A hash function takes an input (like an order ID) and generates a unique output, typically used to partition data into different buckets. This helps efficiently distribute and query data by assigning each data item to a specific group based on its hash value.
What are Slowly Changing Dimensions (SCD) and how are they used in ETL processes?
-Slowly Changing Dimensions (SCD) track changes in dimension attributes over time, such as a customer's address. SCD Type 1 overwrites old data, Type 2 adds new rows to track history, and Type 3 stores both the current and previous versions of the attribute. These types are used in ETL processes to maintain historical accuracy.
What is the difference between a left join and a left anti join?
-A left join combines all records from the left table with matching records from the right table, including non-matching records from the left. A left anti join returns only the non-matching records from the left table, excluding any matches from the right table.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowBrowse More Related Video

What is Databricks? | Introduction to Databricks | Edureka
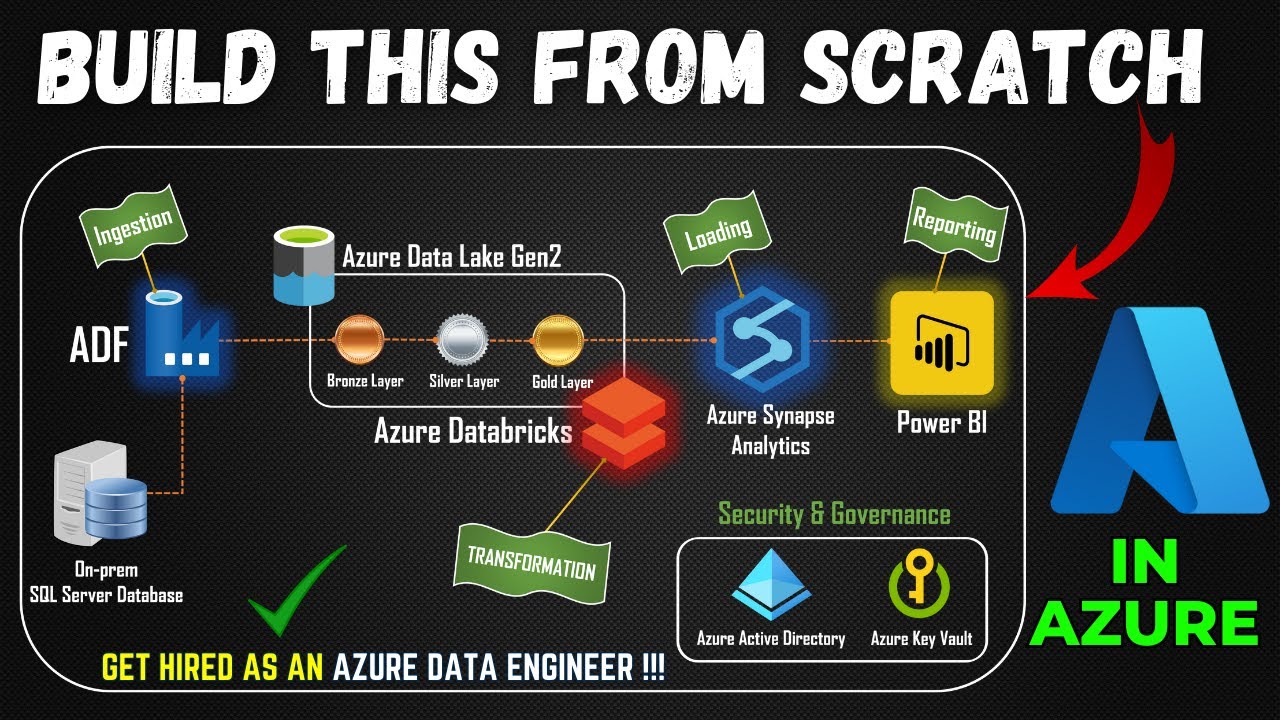
Part 1- End to End Azure Data Engineering Project | Project Overview

Learn Apache Spark in 10 Minutes | Step by Step Guide

Building a Serverless Data Lake (SDLF) with AWS from scratch

What is Microsoft Fabric? The GAMECHANGER data and analytics platform

Sistem Manajemen Database Ke 2
5.0 / 5 (0 votes)