Univariate Visualizations, Part 2: How do you interpret bar graphs?
Summary
TLDRIn this video, the importance of univariate plotting for categorical variables is discussed, emphasizing how visualizing data helps ensure data integrity. The video highlights common issues in categorical data, such as missing data, redundant or mixed-up labels, unknown categories, and role reversals, and explains how these problems can lead to misleading analyses. Through engaging examples, the video stresses the need to carefully check data distributions to avoid errors, and it provides clarity on the difference between histograms and bar charts for visualizing categorical data.
Takeaways
- 😀 Univariate plotting is crucial for ensuring data integrity, especially when working with categorical variables like nominal and ordinal data.
- 😀 Visualizing categorical data helps identify issues like missing data, redundant labels, unknown categories, and incorrect groupings.
- 😀 Bar charts are the most effective way to display the distribution of categorical data, with the y-axis showing frequency and the x-axis representing categories.
- 😀 Missing data (represented as 'NA') can distort analysis and must be carefully considered in any dataset.
- 😀 Redundant labels, such as using both 'males' and 'men' for the same category, can cause confusion and skew results.
- 😀 Unknown groups, such as a category like 'PX 5 lbs 77', indicate problems in the dataset that need further investigation to avoid misleading conclusions.
- 😀 Having too few people in a group can make statistical analysis unreliable, as with the example of a group with only one non-drug user out of many drug users.
- 😀 Role reversals, where categories are misidentified (e.g., males coded as females), can lead to completely incorrect results if not spotted early.
- 😀 Mislabeling categories, such as flipping the coding for '0 sexual partners' and '10+ sexual partners', can produce absurd and misleading data distributions.
- 😀 Recognizing these issues is key to producing valid, reliable analyses, ensuring that the conclusions drawn from the data are accurate and meaningful.
- 😀 Regularly checking the univariate distributions helps catch 'wonky' data issues before they impact the final analysis, making it an essential part of the data analysis process.
Q & A
Why is it important to plot univariate distributions of categorical variables?
-Plotting univariate distributions helps to ensure data integrity by allowing us to visually inspect the data for errors, such as mislabeling, missing data, or inconsistencies that could distort analysis.
What are the potential consequences of failing to visualize categorical data distributions?
-Without visualization, we may miss data errors, such as coding mistakes or inconsistencies, leading to incorrect interpretations and flawed conclusions in statistical analyses.
What does missing data (NA) indicate, and why is it problematic?
-Missing data, marked as 'NA' in many statistical programs, indicates that certain information is absent from the dataset. This can be problematic because it may bias results or lead to incomplete analyses if not handled properly.
What is the issue with redundant labels in categorical data?
-Redundant labels, such as using both 'male' and 'man' to describe the same group, can lead to confusion in analysis. It can cause overcounting or undercounting specific categories, leading to misleading results.
What is an unknown group in categorical data, and how should it be handled?
-An unknown group occurs when a category appears in the data that doesn’t make sense (e.g., 'px five pounds seven'). It should be flagged and investigated to determine if it’s a mistake or if further data cleaning is needed.
Why is having too few people in a particular group problematic?
-When a group has too few participants (e.g., only one person in a category), the sample size is too small to draw valid conclusions or make generalizations, which can undermine the reliability of statistical tests.
What are role reversals in categorical data, and how do they affect analysis?
-Role reversals occur when the labels for two categories are mistakenly swapped (e.g., labeling females as males). This can result in incorrect grouping, which compromises the accuracy of the analysis and the conclusions drawn from the data.
How can mixed-up labels skew data interpretation?
-Mixed-up labels, such as when '10+' sexual partners are mistakenly recorded as '0', can create extreme values that don't reflect the true nature of the data, leading to false conclusions and misinterpretations of the data set.
How can a bar chart help identify data integrity issues?
-A bar chart can visually reveal discrepancies like missing data, redundant labels, or outliers. By inspecting the distribution of data in a bar chart, analysts can spot potential issues that require further exploration or correction.
What is the difference between a bar chart and a histogram, as discussed in the video?
-A bar chart displays categorical data with bars representing different categories, whereas a histogram is used for continuous data, where the bars represent ranges of values. Bar charts have spaces between bars to indicate distinct categories, unlike histograms.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowBrowse More Related Video

Estatística Descritiva Univariada Quantitativa - Boxplot
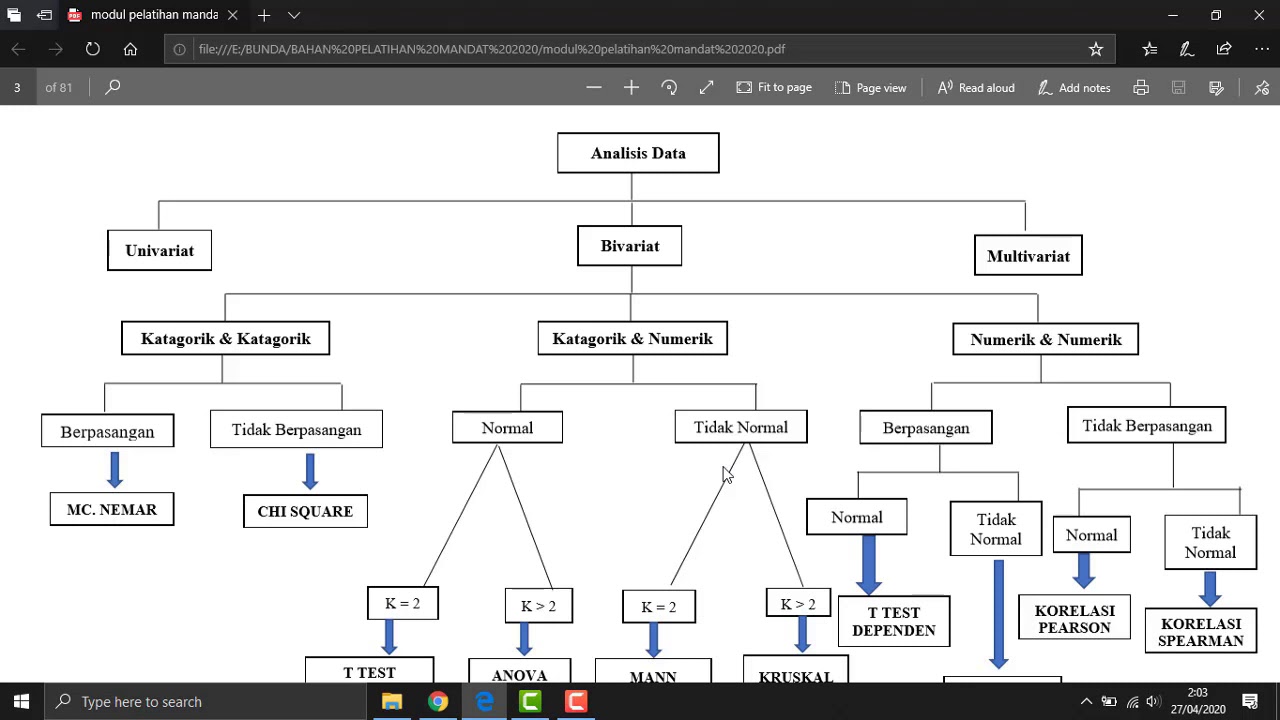
VIDEO 3 Jenis uji statistik AWAL

KONSEP DASAR UJI REGRESI (LOGISTIK DAN LINEAR)

What is Statistics (and why do we study it?)

Statistika menyajikan data dalam bentuk diagram garis | Matematika Dasar

Variables and Types of Variables | Statistics Tutorial | MarinStatsLectures
5.0 / 5 (0 votes)