Deep Learning(CS7015): Lec 9.3 Better activation functions
Summary
TLDRThis lecture discusses the importance of activation functions in deep neural networks, emphasizing why nonlinear activation functions are crucial for creating complex decision boundaries. It covers the limitations of sigmoid and tanh functions, such as vanishing gradients and lack of zero-centering, which can hinder network training. The speaker then introduces ReLU and its variants as popular alternatives, explaining how they address these issues and improve training efficiency. The talk also touches on the challenges of using ReLU, like dead neurons, and proposes solutions like leaky ReLU and parametric ReLU.
Takeaways
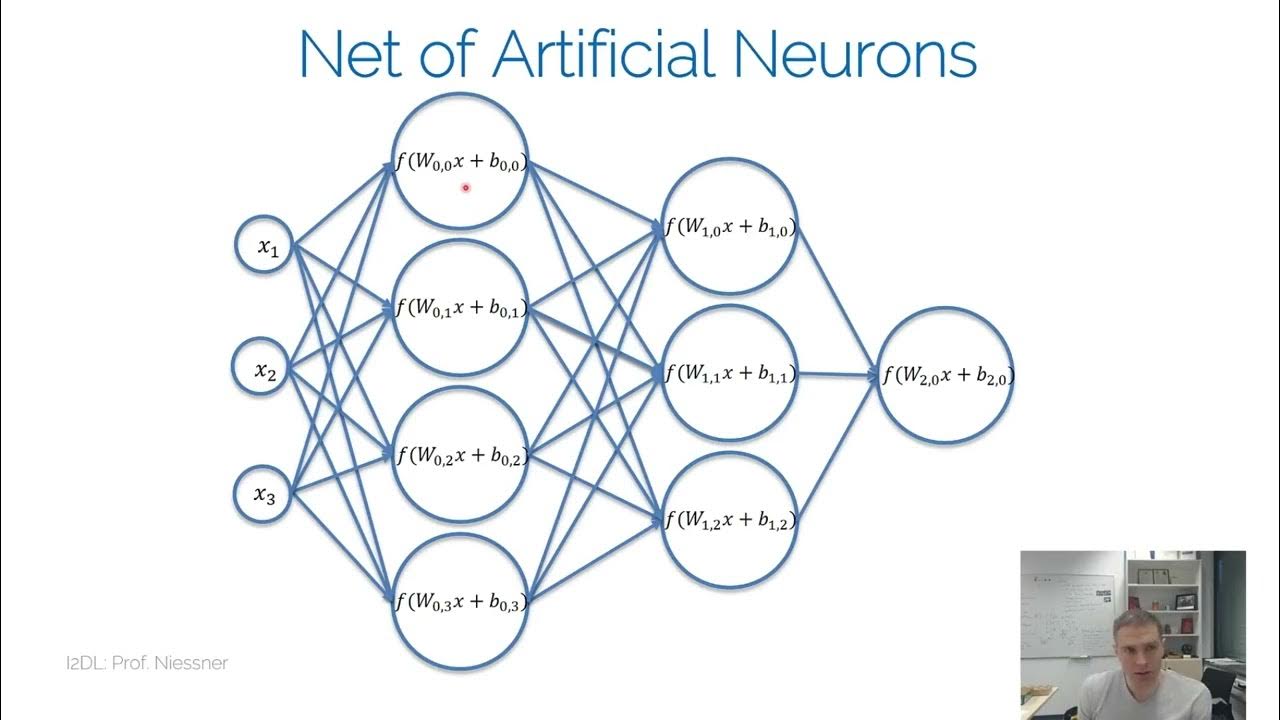
- 🧠 Activation functions are crucial for deep neural networks because they introduce non-linearity, allowing the network to learn complex patterns.
- 📉 Without non-linear activation functions, deep neural networks would essentially behave like a single-layer perceptron, only capable of linear separation.
- 🔍 The sigmoid function, once popular, is now considered less effective due to issues like vanishing gradients and non-zero centering.
- 📊 The vanishing gradient problem occurs when the gradient becomes extremely small, causing the network's weights to update very slowly or not at all.
- 🎯 The ReLU (Rectified Linear Unit) function has become a standard activation function due to its efficiency and effectiveness in training deep networks.
- ⚠️ ReLU can suffer from the 'dying ReLU' problem, where neurons can become inactive and never recover once they output zero.
- 💡 Leaky ReLU and Parametric ReLU are variants designed to address the dying ReLU problem by allowing a small, non-zero output when the input is negative.
- 🔋 The 'dead neuron' issue with ReLU can be mitigated by careful initialization of weights and biases, and using techniques like dropout.
- 📈 Research in activation functions is ongoing, with new variants like ELU (Exponential Linear Unit) and Maxout neurons being explored.
- 📚 For most applications, especially in convolutional neural networks, ReLU is a reliable default choice, despite its potential drawbacks.
Q & A
Why are activation functions important in deep neural networks?
-Activation functions are crucial in deep neural networks because they introduce non-linearities, allowing the network to learn and model complex patterns and relationships. Without non-linear activation functions, a deep network would essentially behave like a single-layer network with linear decision boundaries, severely limiting its ability to solve complex problems.
What is the problem with using only linear transformations in a neural network?
-If a neural network only used linear transformations, it would collapse into a single layer with a single weight matrix, effectively losing the ability to learn complex patterns. This is because the composition of multiple linear transformations is still a linear transformation, which can only create linear decision boundaries and cannot capture non-linear relationships in data.
Why do we need to look at the gradients of activation functions?
-The training of neural networks relies on gradient-based optimization. Gradients indicate the direction and magnitude of the steepest increase in the loss function, guiding the update of weights to minimize the loss. Therefore, understanding the gradient behavior of activation functions is essential for effective training.
What is the concept of saturation in the context of activation functions?
-Saturation occurs when the output of an activation function approaches either 0 or 1 (for sigmoid) or -1 or 1 (for tanh), making the function's output insensitive to changes in the input. This leads to gradients that are very small (close to zero), a problem known as vanishing gradients, which can halt the training process.
How does the sigmoid activation function contribute to the vanishing gradient problem?
-The sigmoid function maps inputs to a range between 0 and 1. As the output of sigmoid neurons approaches 0 or 1, their gradients become very small, leading to vanishing gradients. This means that during backpropagation, the updates to the weights connected to these neurons become negligible, causing the network to struggle with learning and potentially getting stuck in suboptimal solutions.
Why are 0-centered activation functions considered better for training?
-0-centered activation functions, like tanh, have outputs that are symmetrically distributed around 0. This property can lead to more efficient training because the gradients for these functions do not all become positive or negative simultaneously, allowing for more diverse and effective weight updates. In contrast, non-zero centered functions like sigmoid can restrict the update directions, potentially slowing down convergence.
What are the advantages of using the ReLU activation function?
-The ReLU (Rectified Linear Unit) activation function has several advantages: it does not saturate for positive inputs, it is computationally efficient as it only outputs 0 or the input value, and it generally leads to faster convergence during training compared to sigmoid or tanh. However, it can suffer from the dying ReLU problem, where neurons can become inactive永久性.
What is the dying ReLU problem and how can it be mitigated?
-The dying ReLU problem occurs when a ReLU neuron's input becomes negative, causing the neuron to output 0 and never activate again, as the derivative of ReLU for negative inputs is 0, halting gradient flow. This can be mitigated by initializing biases to small positive values, using leaky ReLU variants that allow a small gradient when the input is negative, or by employing other activation functions like parametric ReLU or exponential linear units (ELUs).
What is a leaky ReLU and how does it address the dying ReLU problem?
-A leaky ReLU is a variation of the ReLU function that allows a small, positive gradient when the input is negative, typically defined as 0.01 times the input. This ensures that even when the input is negative, some gradient is still flowing, preventing the neuron from becoming completely inactive and thus addressing the dying ReLU problem.
What is the Maxout neuron and how is it related to ReLU and leaky ReLU?
-The Maxout neuron is a generalization of both ReLU and leaky ReLU. It outputs the maximum of a set of linear functions, each with its own weights and biases. ReLU can be seen as a special case of Maxout with one linear function that outputs the input directly, and leaky ReLU is also a special case with one linear function that outputs a scaled version of the input when it's negative.
Why are sigmoid and tanh not commonly used in convolutional neural networks?
-Sigmoid and tanh are not commonly used in convolutional neural networks (CNNs) because they suffer from the vanishing gradient problem, making it difficult for CNNs to learn effectively. Additionally, they are not zero-centered, which can restrict the update directions during training, slowing down convergence. ReLU and its variants are preferred due to their efficiency and effectiveness in training deep networks.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade Now




5.0 / 5 (0 votes)