Logs and Monitoring - N10-008 CompTIA Network+ : 3.1
Summary
TLDRThe video script discusses the importance of analyzing logs from network devices like routers, switches, and firewalls for monitoring traffic flows and identifying potential issues. It highlights how logs can provide detailed insights into network activity and be used for real-time monitoring or historical analysis. The script also covers the use of syslog for standardized log collection and the role of SIEM in centralizing log data. Additionally, it touches on environmental monitoring in data centers, the use of NetFlow for traffic analysis, and the value of third-party service status pages for gauging network health.
Takeaways
- 📡 Network infrastructure devices like routers, switches, and firewalls generate logs that provide insights into traffic flows and data summaries.
- 🔥 Firewall logs are particularly detailed, showing every flow of traffic with information about the protocol, hostname, username, ports, and disposition of the traffic.
- 🕵️♂️ Logs are useful for real-time monitoring and for retrospective analysis to determine the cause of network events.
- 🗂️ Different devices have different log types, such as audit logs in Active Directory that record login and logout events.
- 🔄 Logs can be consolidated using the syslog protocol, which allows for centralized logging and management.
- 👨💻 Syslog assigns facility codes and severity levels to logs, aiding network administrators in prioritizing and taking action on log information.
- 🔍 Administrators can filter logs based on severity levels to focus on critical alerts or view detailed debug information as needed.
- 🛠️ Monitoring individual interfaces on devices can help identify potential network issues such as runts, giants, or CRC errors.
- 🌡️ Environmental factors like temperature, humidity, and electrical systems are crucial for the health and availability of network equipment.
- 📊 NetFlow is a tool for collecting detailed statistics from network traffic, providing insights into conversations, endpoints, applications, and more.
- 🌐 Third-party services and cloud status pages can provide service availability and performance metrics, which can be cross-referenced with internal network data.
Q & A
What types of network devices can provide valuable logs for analysis?
-Network devices such as routers, switches, firewalls, and other infrastructure devices can provide logs that detail traffic flows and summaries of data traversing the device.
How detailed are the logs typically found in firewalls?
-Firewall logs are often very detailed, showing every single flow of traffic and providing information about what's contained within that traffic flow.
What is the utility of storing historical network logs?
-Storing historical network logs allows administrators to go back in time to determine what may have happened before or after a particular event.
What kind of information can be extracted from a highlighted firewall log?
-A highlighted firewall log can show the protocol, hostname, username, client field, client port number, server IP address, server port number, and the disposition of the traffic.
How can logs help in searching for specific network events?
-Logs allow administrators to run searches for particular IP addresses or port numbers to view all traffic flows on the network that match those values.
What are some examples of logs from an Active Directory infrastructure?
-Active Directory infrastructure logs might include audit logs that show who has logged in or out of the network, including details like process ID, file name, username, and login event.
How can syslog help in consolidating logs from various network devices?
-Syslog is a standard protocol that can be used to configure different devices to send log information to a centralized logging receiver, often consolidating this data into a SIEM (Security Information and Event Manager).
What is the purpose of severity levels in syslog?
-Severity levels in syslog help network administrators filter and take action on the information received from logs, distinguishing between informational details that may not require immediate action and critical details that do.
Why might a network administrator be interested in analyzing individual switch interfaces?
-Analyzing individual switch interfaces can help identify potential problems with data traversing the network, such as a large number of runts or giant frames, which may indicate a collision or communication problem.
What are some environmental factors that can affect the health and availability of a network?
-Environmental factors such as room temperature, humidity levels, electrical system stability, and the presence of water in cooling systems can all impact the health and availability of a network.
How can NetFlow provide additional network insights beyond SNMP and log files?
-NetFlow allows for the collection of statistics and details from the raw traffic traversing the network, providing extensive information on conversations, endpoints, applications in use, and more.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowBrowse More Related Video

Cours réseaux N°14 | équipements d'interconnexion (troisième partie) Par Dr MA.Riahla

CompTIA Security+ SY0-701 Course - 4.9 Use Data Sources to Support an Investigation.

Terms You Need to Know in Networking

Networking Devices - CompTIA Network+ N10-009 - 1.2
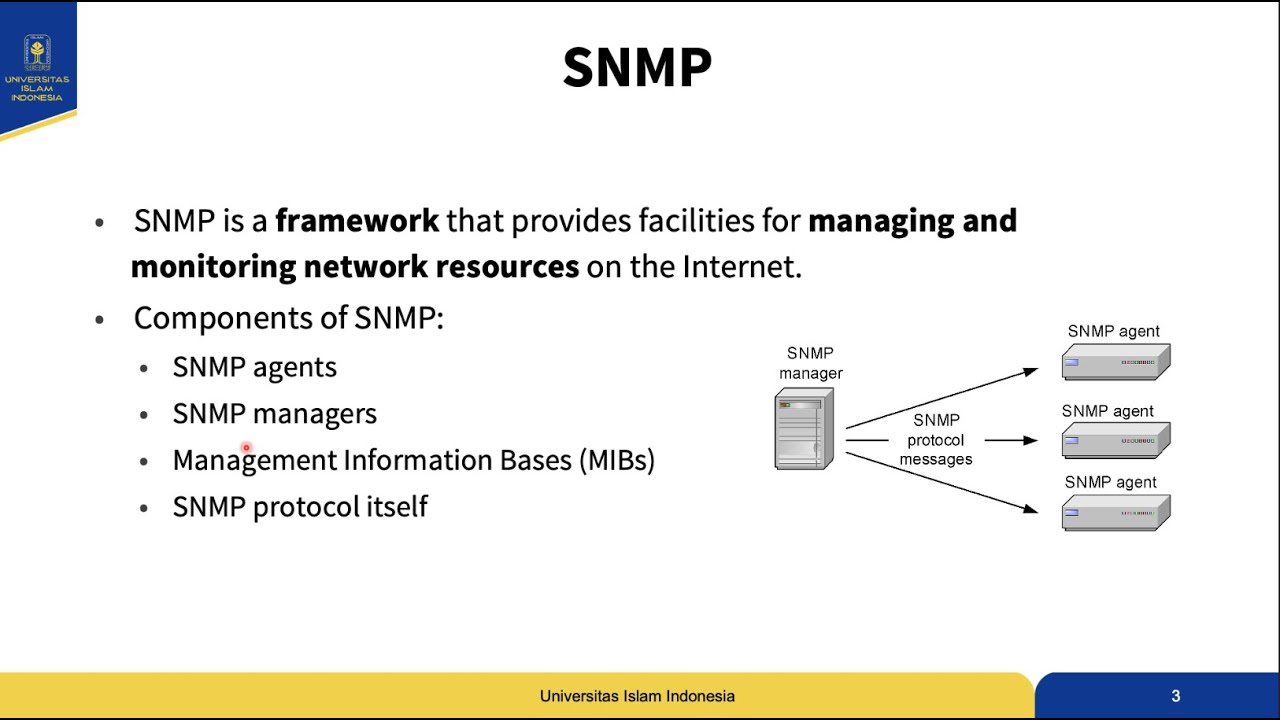
Manajemen Jaringan Komputer - Chapter 3 Simple Network Management Protocol (SNMP)

Hub, Bridge, Switch, Router - Network Devices - Networking Fundamentals - Lesson 1b
5.0 / 5 (0 votes)