LLMs: A Hackers Guide
Summary
TLDRDer Vortrag beschäftigt sich mit der Verwendung von KI und der Generierung von Dokumenten. Der Sprecher führt seine Erfahrungen mit verschiedenen AI-Projekten ein, wie dem Erstellen eines Kommunikations-Automations-Tools und eines visuellen RAG. Er betont die Bedeutung des iterativen Lernprozesses und der Verwendung verschiedener Modelle. Es werden auch Ressourcen und Werkzeuge für die Entwicklung mit KI vorgestellt, sowie Tipps zur Fehlerbehebung und zukünftige Entwicklungen in der KI-Branche.
Takeaways
- 🚀 Die Arbeitsweise mit künstlichen Intelligenzen (AI) und Generativen AI hat sich verändert und erfordert ein neues Denken.
- 💡 Die Verwendung von großen Sprachmodellen (LLMs) hat die Natursprachverarbeitung (NLP) stark verbessert und macht alle englischen Texte und Nachrichten zugänglich.
- 📈 Die Anwendung von AI bei kommerzieller Schifffahrt, einschließlich der Verwendung von Multi-Modal RAG (RAG für visuelle Informationen), hat die Beantwortung missionkritischer Fragen verbessert.
- 🔄 Der iterative Loop (CPLN) ist ein wichtiger Aspekt der AI-Arbeit, bei dem es darum geht, ständig neue Ansätze zu entwickeln und zu testen.
- 📚 Die Erstellung von Dokumenten kann durch die Verwendung von AI-Tools automatisiert werden, was die Wiederholung von Informationen in Meetings oder Dokumenten reduziert.
- 🎨 Die Verwendung von verschiedenen AI-Tools und -Methoden ist entscheidend, um komplexe Probleme zu lösen, und erfordert die Verwendung aller verfügbaren Modi und Strukturen.
- 🛠️ Die Verwendung strukturierter Eingaben und Ausgaben ist wichtig, um die Genauigkeit und Zuverlässigkeit von AI-Modellen zu verbessern.
- 🔄 Die ständige Iteration und Verbesserung von Prompts ist notwendig, um die besten Ergebnisse zu erzielen, und sollte einen großen Teil der Arbeitszeit einnehmen.
- 🔍 Die Verwendung von Debugging-Techniken ist entscheidend, um Probleme in AI-Systemen zu identifizieren und zu beheben, insbesondere durch die Identifizierung von Fehlerquellen und die Anwendung von Korrekturen.
- 📈 Die zukünftige Entwicklung von AI wird durch Hardware- und Speicheroptimierungen sowie Quantifizierung nochmals um ein Vielfaches schneller und kostengünstiger werden.
- 💬 Die Verwendung von AI in der Codierung und Programmierung wird zunehmen und wird in Zukunft einen großen Einfluss auf die Art und Weise haben, wie Entwickler arbeiten.
Q & A
Was ist das Hauptthema des Gesprächs in dem Transkript?
-Das Hauptthema des Gesprächs ist die Arbeit mit künstlichen Intelligenz (AI), insbesondere mit Generativen AI und der Verwendung von Prompts. Es wird auch über die Anwendung von AI in verschiedenen Bereichen und die Herausforderungen bei der Entwicklung mit AI diskutiert.
Wie definiert der Sprecher die 'iterative Schleife' im Kontext der AI-Entwicklung?
-Die 'iterative Schleife' bezieht sich auf den Prozess des kontinuierlichen Tests und Änderns von Prompts und Ansätzen bei der Arbeit mit AI-Modellen. Es geht darum, verschiedene Ansätze zu erkunden und zu optimieren, um bessere Ergebnisse zu erzielen.
Was ist der Hauptunterschied zwischen traditioneller Programmierung und der Arbeit mit AI-Modellen?
-Die traditionelle Programmierung ist deterministisch, während die Arbeit mit AI-Modellen nicht deterministisch ist und eher auf dem Experimentieren und Finden neuer Ansätze basiert. In AI ist es wichtig, sich neue Denkmuster anzueignen und sich nicht an die traditionellen Vorgehensweisen zu halten.
Welche Bedeutung haben 'CPLN'-Prompts in der AI-Entwicklung?
-CPLN steht für 'Chat, Prompt, Loop, Nest' und ist ein von dem Sprecher eingeführtes Muster für die Arbeit mit AI. Es betont die Bedeutung des Chattens mit Modellen, des Änderns von Prompts, des Hinzufügens von Daten und Testfällen sowie des unterteilens der Aufgaben in kleinere Unteraufgaben.
Welche Rolle spielt die Verwendung von Strukturen in der Eingabe und Ausgabe bei der Arbeit mit AI?
-Die Verwendung von Strukturen in der Eingabe und Ausgabe erleichtert es, die Modelle besser zu steuern und zu lenken. Strukturierte Eingaben helfen, die Relevanz und Richtigkeit der Anfragen zu erhöhen, während strukturierte Ausgaben dazu beitragen, dass die Antworten der Modelle präziser und leichter zu interpretieren sind.
Welche Ressourcen empfiehlt der Sprecher für die weitere Ausbildung in der AI-Entwicklung?
-Der Sprecher empfiehlt, sich auf der Suche nach Projekten und Ressourcen in der AI-Community zu orientieren. Er verweist auf seine eigenen Artikel sowie auf Artikel von anderen Experten, die er auf der Website bereitgestellt hat.
Was ist der Vorteil der Verwendung von verschiedenen AI-Modellen?
-Jeder AI-Modell hat unterschiedliche Trainingsdaten und -methoden und hat daher auch unterschiedliche Stärken und Schwächen. Durch die Verwendung verschiedener Modelle kann man bessere Ergebnisse erzielen und sich an unterschiedliche Anwendungsfälle anpassen.
Wie kann man die Effektivität von AI-Modellen bei der Problemlösung verbessern?
-Die Effektivität kann durch das Ändern der Eingabedaten, das Hinzufügen von Struktur zur Ausgabe, das Testen verschiedener Modelle und das kontinuierliche Experimentieren mit verschiedenen Ansätzen verbessert werden.
Welche Art von Fehlern können bei der Arbeit mit AI auftreten?
-Fehler können auf der App-Ebene, bei der Datenverarbeitung oder bei der Anweisungsbefolgung auftreten. Jeder Fehlertyp erfordert eine andere Art der Problemlösung, um die Leistung der AI-Modelle zu verbessern.
Wie sieht die Zukunft der AI-Entwicklung aus Ansehen des Sprechers?
-Die Zukunft der AI-Entwicklung wird von schnelleren Hardware, besseren Optimierungen und der Fähigkeit, komplexere Projekte mit weniger Ressourcen zu erstellen, geprägt sein. Der Sprecher erwähnt auch, dass die Kosten für die Nutzung von AI in naher Zukunft signifikant sinken werden.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowBrowse More Related Video

Aerospace & AI - Airbus’ responsible and human-centric approach to AI | #aidatasummit24

22: Warum ist Pluto kein Planet mehr?

Definition von Kommunikation - Merten6

KI in der Justiz – Ein Anwendungsbeispiel

Nachgefragt: "Was ist systemisch?" mit Barbara Heitger
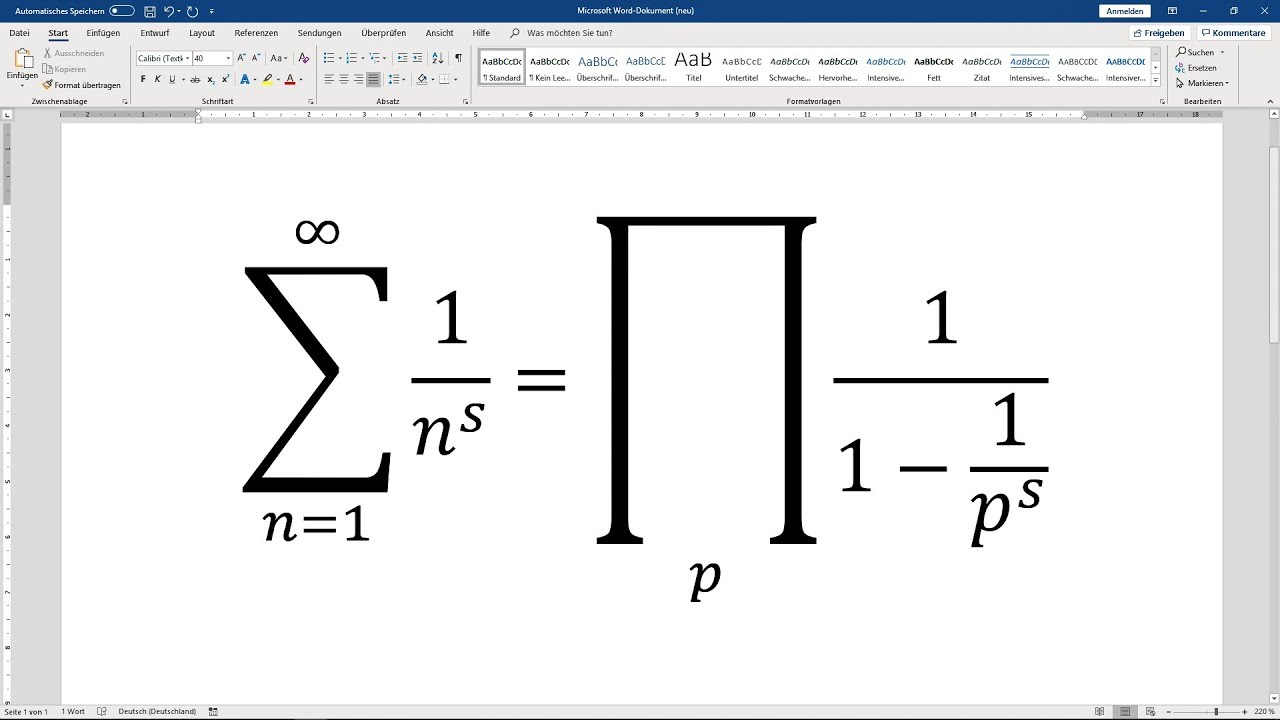
► WORD: mathematische Formeln einfügen - wissenschaftliches Arbeiten Tutorial (Formeleditor) [16]
5.0 / 5 (0 votes)
