Unsupervised Learning: Crash Course AI #6
Summary
TLDRCrash Course AI explores unsupervised learning, where AI models learn from data without teacher-provided labels. Key concepts include clustering, where AI groups similar data points, and representation learning, which helps AI understand and compare complex data like images. The video uses the K-means algorithm to demonstrate how AI can identify patterns in iris flowers, and discusses the challenges and importance of unsupervised learning in advancing AI capabilities.
Takeaways
- 🤖 Unsupervised learning allows computers to learn from data without needing labeled examples, similar to how humans learn by observing patterns.
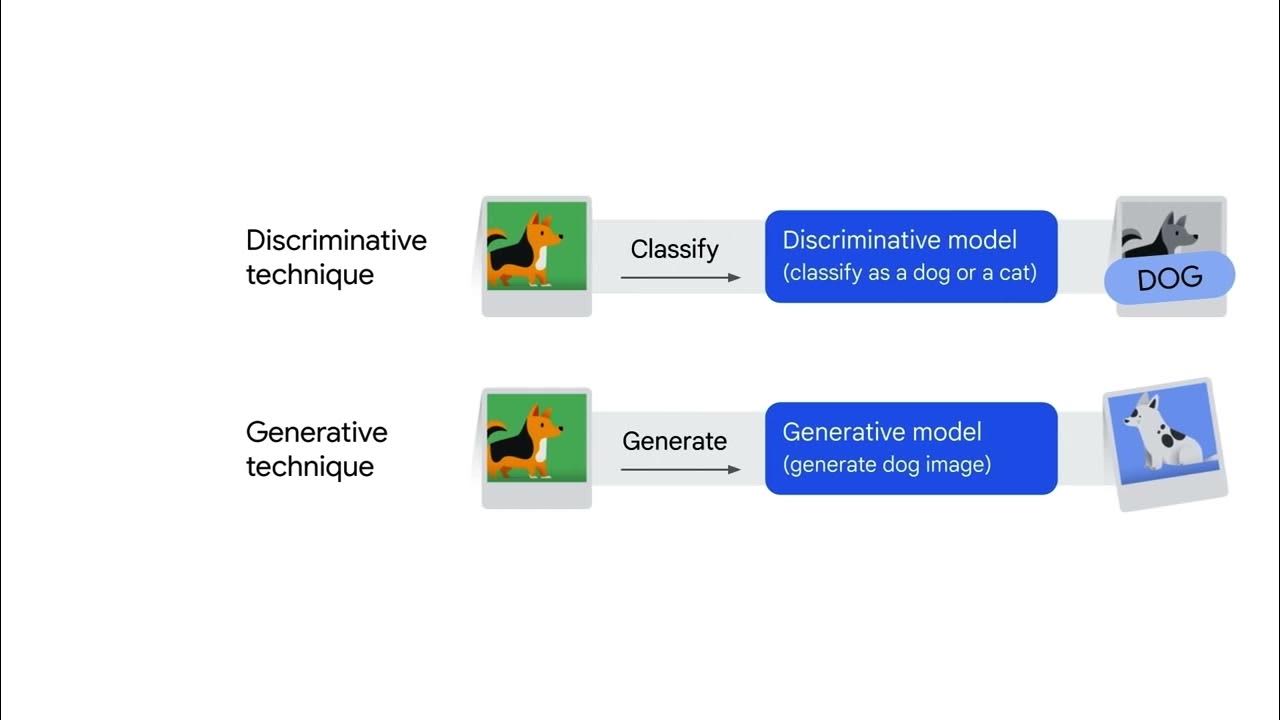
- 🧠 The difference between supervised and unsupervised learning lies in the presence of a teacher or labels; supervised learning predicts answers with labeled data, while unsupervised learning models the world based on patterns.
- 🌼 A practical example of unsupervised learning is clustering, where objects are grouped based on shared properties, as demonstrated by categorizing flowers by color, shape, or species.
- 📊 K-means clustering is an algorithm used for unsupervised learning that involves predicting and correcting the model's understanding of data clusters based on observed patterns.
- 🔍 Representation learning is a process in unsupervised learning where the AI learns to identify abstract patterns in data, such as recognizing features in images beyond individual pixels.
- 🎨 The script uses the analogy of drawing from memory to explain how representation learning works, where the mind reconstructs an image based on remembered features.
- 🌐 Unsupervised learning is crucial for AI as it mimics the human brain's ability to learn from the environment, which is essential for AI's grand ambitions.
- 🏆 Yann LeCun, a Turing Award winner, emphasizes the importance of unsupervised learning for AI's future, suggesting it's the 'ultimate answer'.
- 🌱 The script highlights the ongoing research in unsupervised learning, noting the complexity of designing AI systems that can effectively learn and recognize patterns like the human brain.
- 🌐 The application of unsupervised learning extends to natural language processing, where AI systems are trained to find patterns in words and language, which will be explored in future episodes.
Q & A
What is the main difference between supervised and unsupervised learning?
-Supervised learning requires labeled data and a teacher to guide the model, whereas unsupervised learning does not require labels or a teacher, and the model learns by finding patterns in the data.
How do humans naturally perform unsupervised learning?
-Humans perform unsupervised learning by observing the world and identifying patterns without explicit instruction, such as recognizing different animals or understanding the rules of a game by watching.
What is unsupervised clustering?
-Unsupervised clustering is the process of grouping similar objects together based on their properties without the use of predefined labels.
How does the K-means clustering algorithm work?
-The K-means clustering algorithm works by initially guessing the number of clusters (K), randomly assigning data points to clusters, calculating the average of each cluster, and then iteratively refining the cluster assignments and averages until convergence.
What are the two key questions that need to be answered when constructing a model for unsupervised learning?
-The two key questions are: 1) What observations can we measure? and 2) How do we want to represent the world?
Why is it important to measure petal length and width in the iris flower example?
-Petal length and width are chosen as measurements because they are distinguishing features that can help differentiate between different species of iris flowers.
What is representation learning in the context of unsupervised learning?
-Representation learning is the process of finding meaningful patterns in data that are more abstract than individual data points, which helps in understanding and comparing the data.
How does the autoencoder neural network contribute to representation learning?
-An autoencoder neural network contributes to representation learning by encoding the input data into a representation and then decoding it to reconstruct the original input, thereby learning meaningful patterns.
Why is unsupervised learning considered the 'ultimate answer' by Professor Yann LeCun?
-Unsupervised learning is considered the 'ultimate answer' because it mimics how humans learn from the environment without explicit supervision, which is a key aspect of AI's grand ambitions to understand and interact with the world.
What is the challenge in designing AI systems for effective unsupervised learning?
-The challenge lies in the fact that AI systems cannot learn exactly like humans do through simple observation and imitation; they require specifically designed models and guidance on how to find patterns.
How does the script suggest that unsupervised learning can be applied to natural language processing?
-The script hints that unsupervised learning can be applied to natural language processing by finding patterns in words and language, similar to how it finds patterns in other types of data.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowBrowse More Related Video





5.0 / 5 (0 votes)