Has Generative AI Already Peaked? - Computerphile
Summary
TLDRThe video script discusses the limitations of generative AI and the concept of CLIP embeddings, which are trained to match images with text descriptions. It challenges the notion that simply adding more data and bigger models will inevitably lead to general intelligence. The paper referenced suggests that the data required for zero-shot performance on new tasks is astronomically high, implying a plateau in AI capabilities without new strategies or representations. The script also touches on the imbalance in data representation and its impact on AI performance across various tasks.
Takeaways
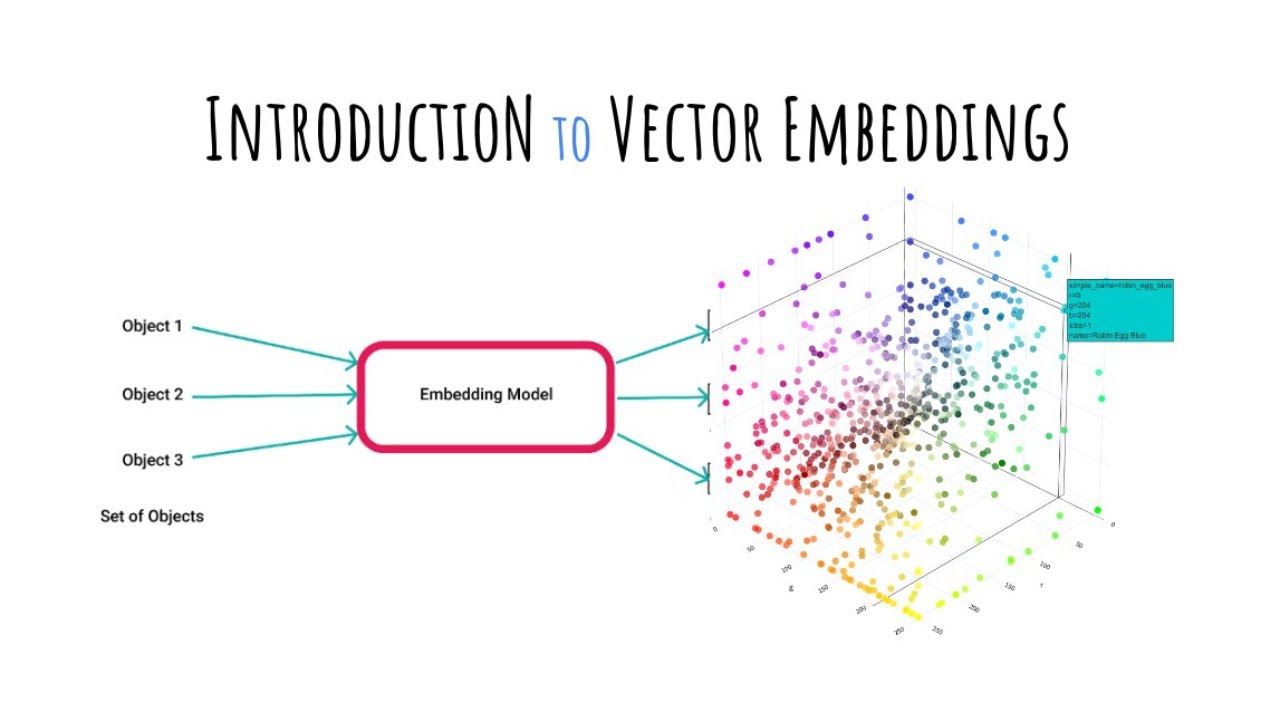
- 🧠 The script discusses the concept of CLIP (Contrastive Language-Image Pre-training) embeddings, which are representations learned from pairing images with text to understand and generate content.
- 🔮 There's an ongoing debate about whether adding more data and bigger models will eventually lead to general intelligence in AI, with some tech companies promoting this idea for product sales.
- 👨🔬 The speaker, as a scientist, emphasizes the importance of experimental evidence over hypotheses about AI's future capabilities and challenges the idea of AI's inevitable upward trajectory.
- 📊 The paper mentioned in the script argues against the notion that more data and larger models will solve all AI challenges, suggesting that the amount of data needed for general zero-shot performance is unattainably large.
- 📈 The paper presents data suggesting that performance gains in AI tasks may plateau despite increasing data, implying a limit to how effective current AI models can become.
- 📚 The script highlights the importance of data representation, mentioning that over-represented concepts like 'cats' perform better in AI models than under-represented ones like 'specific tree species'.
- 🌐 The discussion touches on downstream tasks enabled by CLIP embeddings, such as classification and recommendation systems, which can be used in services like Netflix or Spotify.
- 📉 The paper's findings indicate a potential logarithmic relationship between data amount and performance, suggesting diminishing returns on investment in data and model size.
- 🚧 The speaker suggests that for difficult tasks with under-represented data, current AI strategies may not suffice and alternative approaches may be necessary.
- 🌳 The script uses the example of identifying specific tree species to illustrate the challenge of applying AI to complex, nuanced problems with limited data.
- 🔑 The paper and the speaker both point to the uneven distribution of data as a significant barrier to achieving high performance across all potential AI tasks.
Q & A
What is the main topic discussed in the video script?
-The main topic discussed is the concept of CLIP (Contrastive Language-Image Pre-training) embeddings and the debate around the idea that adding more data and bigger models will lead to general intelligence in AI.
What is the general argument made by some tech companies regarding AI and data?
-The argument is that by continuously adding more data and increasing model sizes, AI will eventually achieve a level of general intelligence capable of performing any task across all domains.
What does the speaker suggest about the idea of AI achieving general intelligence through data and model size alone?
-The speaker suggests skepticism, stating that the idea needs to be experimentally justified rather than hypothesized, and refers to a recent paper that argues against this notion.
What does the paper mentioned in the script argue against?
-The paper argues against the idea that simply adding more data and bigger models will eventually solve all AI challenges, stating that the amount of data needed for general zero-shot performance is astronomically vast and impractical.
What are the potential downstream tasks for CLIP embeddings mentioned in the script?
-The potential downstream tasks mentioned include classification, image recall, and recommender systems for services like Spotify or Netflix.
What does the script suggest about the effectiveness of current AI models on difficult problems?
-The script suggests that current AI models may not be effective for difficult problems without massive amounts of data to support them, especially when dealing with under-represented concepts.
What does the speaker mean by 'zero-shot classification' in the context of the script?
-Zero-shot classification refers to the ability of a model to classify an object or concept without having seen examples of it during training, by relying on the embedded space where text and images are matched.
What does the script imply about the distribution of classes and concepts in current AI datasets?
-The script implies that there is an uneven distribution, with some concepts like cats being over-represented, while others like specific tree species are under-represented in the datasets.
What is the potential implication of the findings in the paper for the future of AI development?
-The implication is that there may be a plateau in AI performance improvements, suggesting that more data and bigger models alone may not lead to significant advancements and that alternative strategies may be needed.
What is the speaker's stance on the current trajectory of AI performance improvements?
-The speaker is cautiously optimistic but leans towards a more pessimistic view, suggesting that the current approach may not yield the expected exponential improvements in AI performance.
What is the role of human feedback in training AI models as mentioned in the script?
-Human feedback is suggested as a potential method to improve the training of AI models, making them more accurate and effective, especially for under-represented concepts.
Outlines

Этот раздел доступен только подписчикам платных тарифов. Пожалуйста, перейдите на платный тариф для доступа.
Перейти на платный тарифMindmap

Этот раздел доступен только подписчикам платных тарифов. Пожалуйста, перейдите на платный тариф для доступа.
Перейти на платный тарифKeywords

Этот раздел доступен только подписчикам платных тарифов. Пожалуйста, перейдите на платный тариф для доступа.
Перейти на платный тарифHighlights

Этот раздел доступен только подписчикам платных тарифов. Пожалуйста, перейдите на платный тариф для доступа.
Перейти на платный тарифTranscripts

Этот раздел доступен только подписчикам платных тарифов. Пожалуйста, перейдите на платный тариф для доступа.
Перейти на платный тарифПосмотреть больше похожих видео





5.0 / 5 (0 votes)
