Dataframes Part 02 - 02/03
Summary
TLDRThe video script offers an in-depth tutorial on data manipulation using Python's pandas library. It covers essential operations like subsetting data frames, analyzing data with 'describe', handling missing values with 'fillna' and 'dropna', and removing duplicates. The script also explains merging and joining data frames akin to SQL, and introduces 'groupby' for aggregate operations. It's a comprehensive guide for data analysis, emphasizing practical applications.
Takeaways
- 📊 Use the `describe` function to get a statistical summary of a DataFrame, including mean, standard deviation, min, max, and quartiles.
- 🔍 The `value_counts` function helps to determine the frequency of unique values in a column.
- 📈 To normalize data, you can divide each value by the total count of that column using the `normalize` function.
- 🗂️ Access DataFrame columns using the dot notation (e.g., `DataFrame.column_name`) or by bracket notation (e.g., `DataFrame['column_name']`).
- 🔄 The `drop_duplicates` function is used to remove duplicate rows from a DataFrame.
- 🔗 `merge` and `join` functions are used to combine two DataFrames based on a common column.
- 🔄 `sort_values` sorts the DataFrame based on the values of a specified column.
- 🚫 `dropna` removes rows with missing values, which is useful for data cleaning.
- 🔄 `fillna` fills missing values with a specified value, which is another method for data cleaning.
- 🔑 `rename` allows you to change the names of the columns in a DataFrame.
- 👥 `groupby` performs operations on groups of data, similar to SQL group by, and can calculate mean, max, median, count, etc., for each group.
Q & A
What is the primary purpose of using the 'describe' function in a DataFrame?
-The 'describe' function in a DataFrame is used to get a statistical summary of the dataset. It provides information such as the count, mean, standard deviation, minimum, 25th percentile, median, 75th percentile, and maximum for each column.
How can you access specific columns in a DataFrame?
-You can access specific columns in a DataFrame using either the column name as an attribute (e.g., `df['column_name']`) or by using the dot notation if the column name is a valid identifier (e.g., `df.column_name`).
What does the 'value_counts' function do in pandas?
-The 'value_counts' function in pandas is used to get the count of unique values in a column. It returns a Series containing counts of unique values sorted in descending order.
How can you identify and handle missing values in a DataFrame?
-Missing values in a DataFrame can be identified using the `isna()` or `isnull()` functions. To handle missing values, you can use the `fillna()` function to fill them with a specified value or `dropna()` to remove rows or columns containing missing values.
What is the difference between 'merge' and 'join' in pandas?
-Both 'merge' and 'join' are used to combine two DataFrames in pandas. The difference lies in the syntax and the default behavior. 'Merge' is more flexible and allows specifying the type of join (inner, left, right, outer), while 'join' uses the index of one DataFrame to merge with the columns of another by default.
How can you drop duplicates from a DataFrame?
-Duplicates in a DataFrame can be dropped using the `drop_duplicates()` function. You can specify a subset of columns to check for duplicates if needed. By default, it keeps the first occurrence and drops the rest.
What does the 'groupby' function do in pandas?
-The 'groupby' function in pandas is used to group rows that have the same value in specified columns and then apply a specified function to each group. It is useful for performing operations on grouped data, such as calculating aggregates.
How can you rename columns in a DataFrame?
-Columns in a DataFrame can be renamed using the `rename` function. You provide a mapping of old column names to new column names. You can choose to modify the DataFrame in place or create a new DataFrame with the renamed columns.
What is the significance of the 'inplace' parameter in pandas functions?
-The 'inplace' parameter in pandas functions determines whether the operation should modify the original DataFrame or return a new DataFrame with the changes. If set to True, the original DataFrame is modified; if False, a new DataFrame is returned.
How can you sort a DataFrame based on specific column values?
-You can sort a DataFrame based on specific column values using the `sort_values()` function. You specify the column name and the sorting order (ascending or descending). This function can also be used to sort by multiple columns.
What does the 'drop' function do in pandas?
-The 'drop' function in pandas is used to remove specified index or column labels from a DataFrame. It can be used to drop rows or columns based on labels or conditions.
Outlines

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレードMindmap

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレードKeywords

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレードHighlights

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレードTranscripts

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレード関連動画をさらに表示
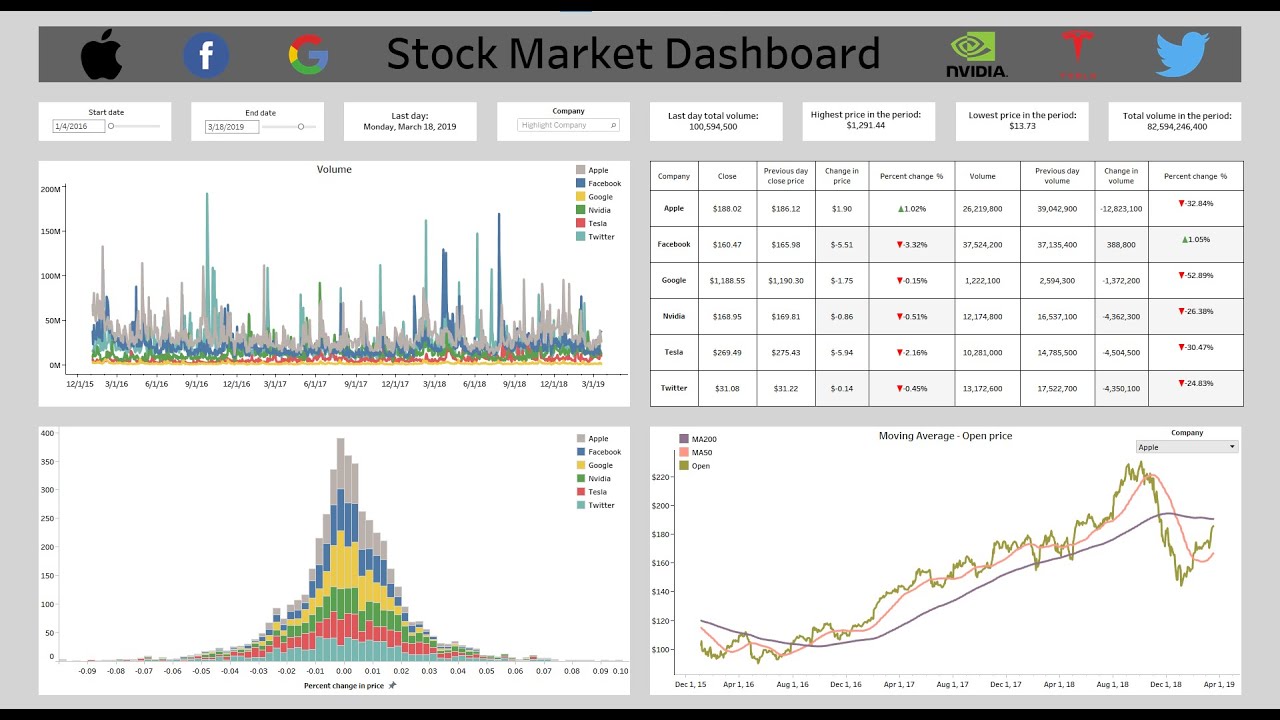
THE ULTIMATE TABLEAU PORTFOLIO PROJECT: From Pandas to an Amazing Interactive Stock Market Dashboard
Pandas Creating Columns - Data Analysis with Python Course

Manipulação de Dados em Python/Pandas - #02 Tipos de Variáveis

Dataframes - Part 01

Python Pandas Tutorial 1. What is Pandas python? Introduction and Installation

Python: Pandas Tutorial | Intro to DataFrames
5.0 / 5 (0 votes)
