RAG Explained
Summary
TLDRThe video script explores the concept of Retrieval Augmented Generation (RAG), drawing an analogy between a journalist seeking information from a librarian and a large language model (LLM) querying a vector database for relevant data. It discusses the importance of clean, governed data and transparent LLMs to ensure accurate and reliable outputs, especially in business-critical applications. The conversation highlights the need for trust in data, akin to a journalist's trust in a librarian's expertise, to mitigate concerns about inaccuracies and biases in AI-generated responses.
Takeaways
- 📚 The analogy of a journalist and a librarian is used to explain the concept of Retrieval Augmented Generation (RAG), where a large language model (LLM) retrieves relevant data from a vector database to answer specific questions.
- 🤖 The user, in this case a business analyst, poses a question that requires specific and up-to-date information, which an LLM alone might not have.
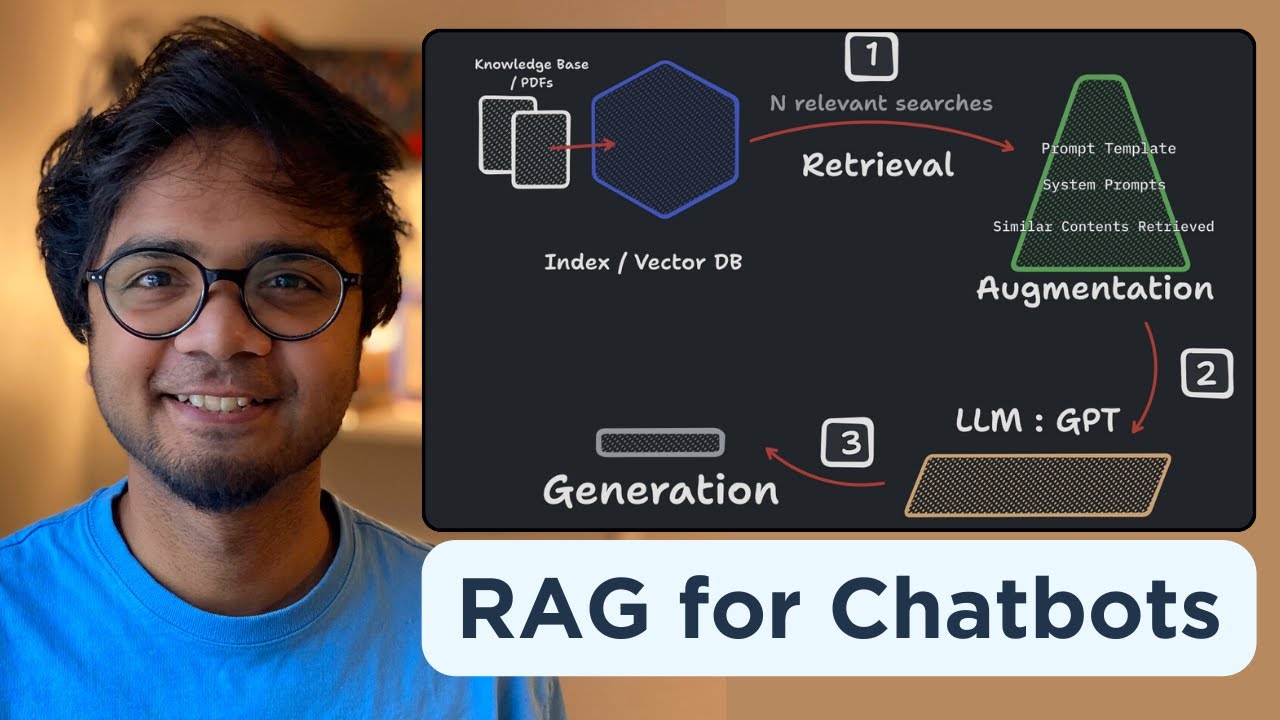
- 🔍 To answer specific and dynamic questions, multiple data sources may be needed, which are then aggregated into a vector database for the LLM to access.
- 📊 A vector database represents structured and unstructured data in a mathematical form, making it easier for machine learning models to understand and use.
- 🔗 The data retrieved from the vector database is embedded into the original prompt, which is then processed by the LLM to generate an accurate and data-backed response.
- 🆕 As new data is added to the vector database, the embeddings are updated, ensuring that subsequent queries are answered with the most current information.
- 🚫 Enterprises are concerned about deploying RAG in customer-facing applications due to the risk of hallucinations, inaccuracies, or perpetuation of biases.
- 🧹 Ensuring data cleanliness, governance, and management is crucial to mitigate concerns about the quality and reliability of the data fed into the vector database.
- 🔍 Transparency in how LLMs are trained is important for businesses to trust the technology and ensure that there are no inaccuracies or biases in the training data.
- 🏢 For businesses, it's critical to maintain brand reputation by ensuring that the LLMs used provide accurate and reliable answers to their specific questions.
Q & A
What is the role of a librarian in the context of the journalist's research?
-In the context of the journalist's research, the librarian acts as an expert who helps the journalist find relevant books on specific topics by querying the library's collection.
How does the librarian's role relate to Retrieval Augmented Generation (RAG) in AI?
-The librarian's role in providing relevant books to the journalist is analogous to RAG, where large language models use vector databases to retrieve key sources of data and information to answer a question.
What is the significance of the business analyst's question about revenue in Q1 from the northeast region?
-The business analyst's question is significant as it represents a specific and time-sensitive query that requires up-to-date and accurate data, highlighting the need for a reliable data retrieval system.
Why is it important to separate general language understanding from specific business knowledge in LLMs?
-It is important to separate general language understanding from specific business knowledge in LLMs because the latter is unique to each business and changes over time, necessitating tailored data sources for accurate responses.
What is a vector database and how does it relate to answering specific questions?
-A vector database is a mathematical representation of structured and unstructured data that can be queried to retrieve relevant data for answering specific questions, enhancing the capabilities of LLMs.
How does the inclusion of vector embeddings in prompts affect the output of LLMs?
-Including vector embeddings in prompts provides LLMs with the relevant, up-to-date data they need to generate accurate and informed responses to specific questions.
Why is it crucial for the data in the vector database to be updated as new information becomes available?
-Updating the data in the vector database as new information becomes available ensures that the LLMs have access to the most current data, which is essential for providing accurate and relevant answers to questions.
What are some concerns enterprises have about deploying AI technologies in business-critical applications?
-Enterprises are concerned about the potential for AI technologies to produce hallucinations, inaccuracies, or perpetuate bias in customer-facing, business-critical applications.
How can enterprises mitigate concerns about the accuracy and bias of AI-generated outputs?
-Enterprises can mitigate concerns by ensuring good data governance, proper data management, and using transparent LLMs with clear training data to avoid inaccuracies and biases.
Why is transparency in the training of LLMs important for businesses?
-Transparency in the training of LLMs is important for businesses to ensure that the models do not contain inaccuracies, intellectual property issues, or data that could lead to biased outputs, thus protecting the brand's reputation.
How does the analogy of the journalist and librarian relate to the trust in data for AI use cases in business?
-The analogy of the journalist and librarian highlights the importance of trust in data for AI use cases in business, emphasizing the need for confidence in the accuracy and reliability of the data used by LLMs.
Outlines

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレードMindmap

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレードKeywords

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレードHighlights

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレードTranscripts

このセクションは有料ユーザー限定です。 アクセスするには、アップグレードをお願いします。
今すぐアップグレード関連動画をさらに表示

Retrieval Augmented Generation - Neural NebulAI Episode 9

Introduction to Generative AI (Day 7/20) #largelanguagemodels #genai
Build your own RAG (retrieval augmented generation) AI Chatbot using Python | Simple walkthrough

Introduction to Generative AI (Day 10/20) What are vector databases?

[RAG Series #1] Hanya 10 menit paham bagaimana konsep dibalik Retrieval Augmented Generation (RAG)

Realtime Powerful RAG Pipeline using Neo4j(Knowledge Graph Db) and Langchain #rag
5.0 / 5 (0 votes)
