Data Lakehouse: An Introduction
Summary
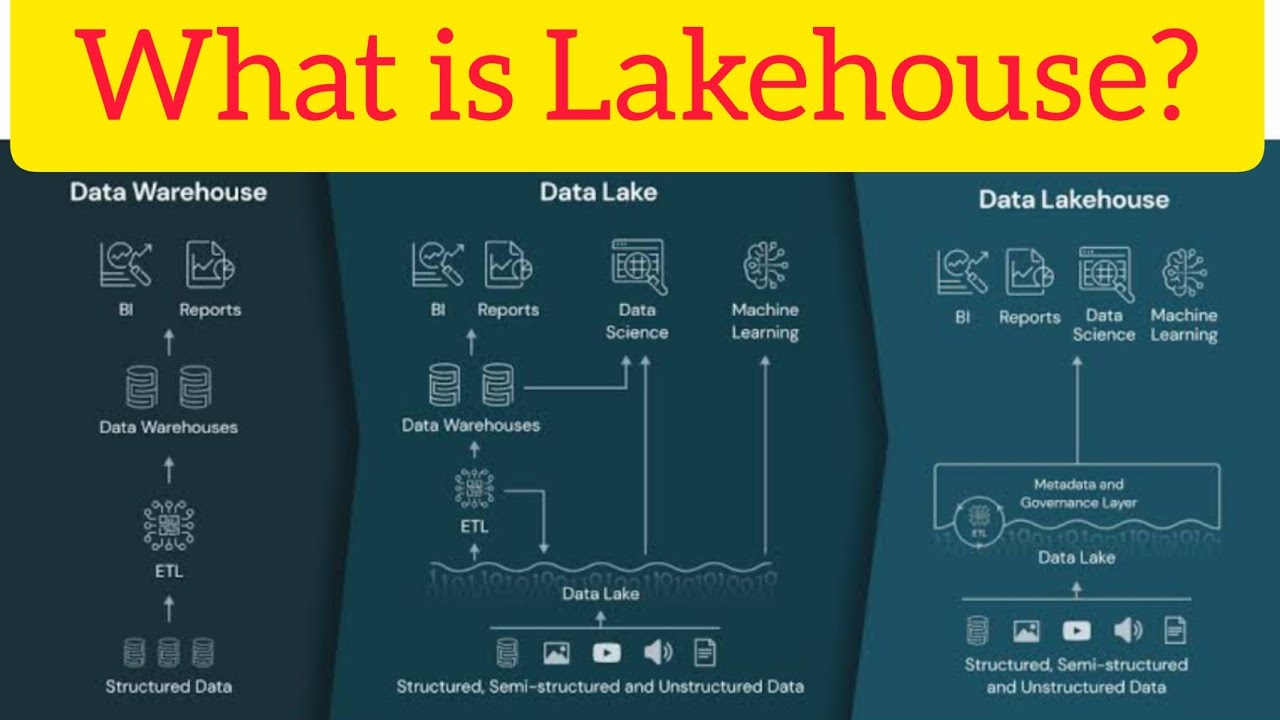
TLDRIn this video, Brian introduces the concept of the Data Lakehouse, a convergence of data lakes and data warehouses. He discusses the evolution from the data lake, which became a data swamp due to lack of governance, to the structured environment of traditional data warehouses. Brian explores the challenges of implementing data warehouse features in a distributed data platform, highlighting the advancements in technologies like Delta Lake that offer transactional support and ACID properties. The summary also touches on the architectural differences between relational databases and data lakes, and the importance of features like schema evolution and metadata governance in the Data Lakehouse.
Takeaways
- 📚 The Data Lakehouse is an emerging concept that combines the best of data lakes and data warehouses, aiming to provide a unified platform for data storage and analytics.
- 🔄 The Data Lakehouse introduces transactional support to data lakes with technologies like Delta Lake, which adds transaction logs to Parquet files, enabling ACID properties.
- 🚀 The evolution from data lake to data swamp highlighted the lack of data governance, leading to the need for a more structured approach to handle big data effectively.
- 🛠 Relational databases offer robust features like structured query language (SQL), ACID transactions, and various constraints that ensure data integrity and security.
- 🔑 Traditional data warehouses are built on top of relational databases and are optimized for reporting and decision-making through data aggregation and fast querying.
- 🔍 The architectural differences between data lakes and relational databases present challenges in implementing data warehouse features on a distributed data platform.
- 🔄 Schema evolution is a feature of the Data Lakehouse that allows for dynamic changes to the data schema without disrupting existing systems, accommodating the fast pace of data changes.
- 🔒 Security in the Data Lakehouse context relies on cloud platform security measures, as opposed to the encapsulated security features of traditional relational databases.
- 🔄 The Data Lakehouse aims to support a wide range of data types beyond structured data, including images, videos, and other multimedia formats, which is essential for modern data analytics.
- 🤖 Support for machine learning and AI is a significant aspect of the Data Lakehouse, expanding its capabilities beyond traditional data warehousing to include advanced analytics.
- 🔗 The Data Lakehouse concept is continuously evolving, with features like referential integrity and other constraints still in development to enhance data management and governance.
Q & A
What is the main topic of the video?
-The main topic of the video is the concept of the data lake house, its introduction, and how it combines elements of data lakes and traditional data warehouses.
What was the initial problem with data lakes?
-The initial problem with data lakes was the lack of data governance, which led to a situation where a lot of data was stored without any structure or thought about how it should be used, eventually turning into a 'data swamp'.
What are the core features of relational databases that support a data warehouse?
-The core features of relational databases that support a data warehouse include support for structured query language (SQL), built on set theory, ACID transactions for data integrity, constraints for data validity, and transaction logs for recoverability.
What is the difference between OLTP and data warehouse workloads in relational databases?
-OLTP (Online Transaction Processing) workloads focus on transactional processing systems for daily operations, while data warehouse workloads focus on reporting and decision-making with an emphasis on querying large datasets for aggregation.
What is the significance of ACID in relational databases?
-ACID in relational databases stands for Atomicity, Consistency, Isolation, and Durability. It ensures that database transactions are processed reliably, maintaining data integrity and allowing for complete or no changes at all.
What is the Delta Lake and how does it relate to data lake houses?
-Delta Lake is a technology that adds transactional support to data lakes, providing ACID properties. It is based on the Parquet file format and includes transaction logging, which is crucial for the development of data lake houses.
What challenges arise when trying to implement relational database features in a data lake house environment?
-Challenges include the distributed nature of data storage in a data lake house, which requires additional overhead and network traffic to perform operations like checking for unique keys or referential integrity across multiple nodes.
What is schema evolution and why is it important in data lake houses?
-Schema evolution is the ability of a system to adapt to changes in the schema, such as adding new columns, without breaking existing processes. It is important in data lake houses to accommodate the fast-paced and dynamic nature of data storage and analysis.
How does the data lake house approach differ from traditional data warehouses in terms of security?
-In data lake houses, security is often managed through the cloud platform's architecture rather than being encapsulated within the database service itself. This means that security measures need to be implemented at the infrastructure level, where the data is stored.
What are the new capabilities that data lake houses bring to the table compared to traditional data warehouses?
-Data lake houses bring capabilities such as support for a variety of file structures, not just structured data, and the ability to handle unstructured data like images, videos, and sounds. They also support machine learning and AI, which are not traditionally part of data warehouse functionalities.
What is the final message or conclusion of the video?
-The final message of the video is that while data lake houses have made significant progress in emulating the functionality of traditional data warehouses, they still face unique challenges due to their architectural differences. However, they offer new capabilities that are essential for modern data processing and analysis.
Outlines

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantMindmap

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantKeywords

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantHighlights

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantTranscripts

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantVoir Plus de Vidéos Connexes

02 What is Data Lakehouse & Databricks Data Intelligence Platform | Benefits of Databricks Lakehouse
What is Lakehouse Architecture? Databricks Lakehouse architecture. #databricks #lakehouse #pyspark

Data Lakehouses Explained

Intro to Databricks Lakehouse Platform

Intro To Databricks - What Is Databricks

watsonx.data in 10 minutes!
5.0 / 5 (0 votes)
