Recurrent Neural Networks - Ep. 9 (Deep Learning SIMPLIFIED)
Summary
TLDRRecurrent Neural Networks (RNNs) are deep learning models designed to process time-dependent data, using feedback loops to remember previous inputs. They excel in applications like speech recognition, image captioning, and time series forecasting. Unlike feedforward networks, RNNs handle sequential data, but face challenges like the vanishing gradient problem. Solutions such as GRU and LSTM gating mechanisms help mitigate these issues. RNNs require substantial computational power, and GPUs can accelerate training by up to 250 times. RNNs are ideal for tasks that involve predicting or generating sequences over time.
Takeaways
- 😀 Recurrent Neural Networks (RNNs) are ideal for time-series data and applications where patterns change over time.
- 😀 RNNs were popularized by the work of Juergen Schmidhuber, Sepp Hochreiter, and Alex Graves, and have a broad range of applications, such as speech recognition and driverless cars.
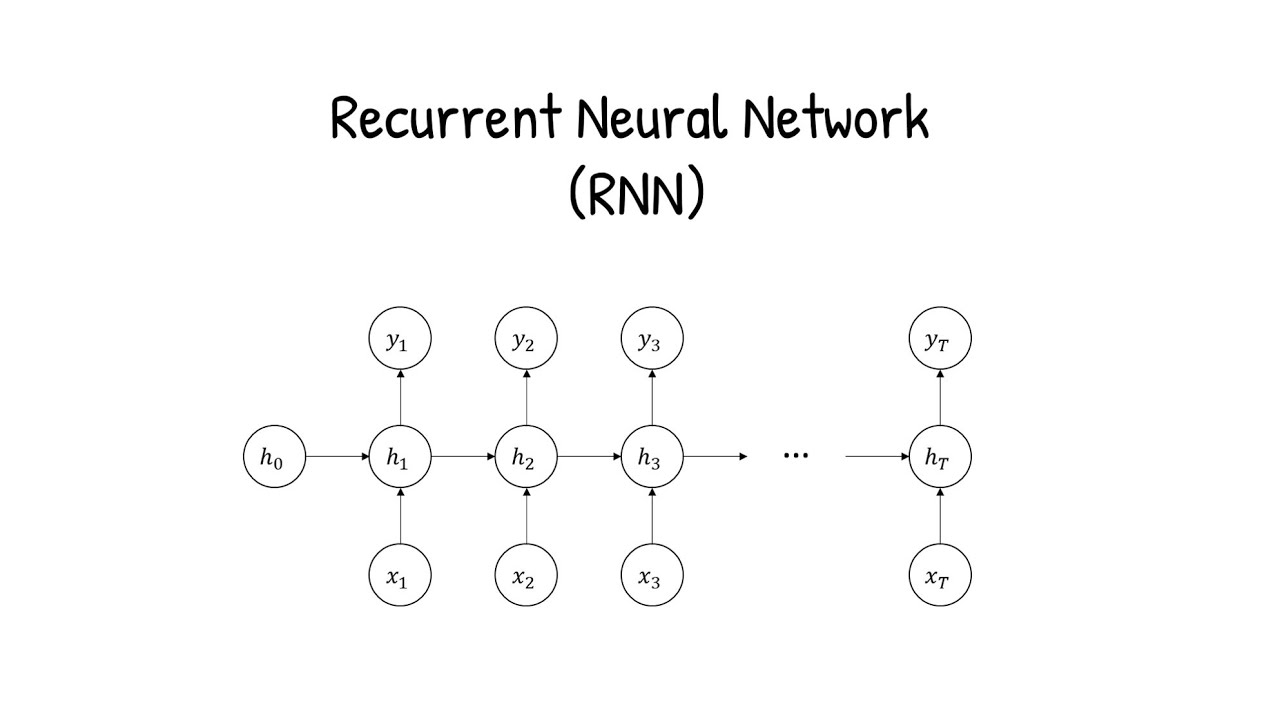
- 😀 Unlike feedforward networks, RNNs have a feedback loop where the output of a layer is fed back into the same layer for future time steps.
- 😀 RNNs can process both sequences of input and output, making them suitable for tasks like image captioning, document classification, video classification, and demand forecasting.
- 😀 When using RNNs, stacking multiple RNN layers can improve the complexity of the model's output, enhancing its capabilities.
- 😀 One major challenge in training RNNs is the vanishing gradient problem, which becomes exponentially worse with the number of time steps, making training a 100-step RNN similar to training a 100-layer feedforward network.
- 😀 The vanishing gradient problem in RNNs can be mitigated with techniques like gating, which helps the network decide when to forget or remember past inputs. Popular gating mechanisms include GRU (Gated Recurrent Unit) and LSTM (Long Short-Term Memory).
- 😀 Other methods to address training challenges in RNNs include gradient clipping, steeper gates, and the use of better optimizers.
- 😀 GPUs are significantly faster than CPUs when it comes to training RNNs, as demonstrated by a team at Indico who found GPUs to train RNNs 250 times faster than CPUs for tasks like sentiment analysis.
- 😀 RNNs are more suitable for time series tasks, classification, regression, and forecasting, whereas feedforward networks are often better suited for tasks that require a single output (e.g., class prediction).
Q & A
What is the main advantage of using recurrent neural networks (RNNs) for time-dependent data?
-The main advantage of RNNs is their ability to model time-dependent data, as they include a built-in feedback loop that allows them to retain information across time steps, making them ideal for tasks like forecasting and sequential data analysis.
What historical figures contributed to the popularity of RNNs in recent times?
-RNNs gained significant popularity due to the works of Juergen Schmidhuber, Sepp Hochreiter, and Alex Graves.
How do recurrent neural networks (RNNs) differ from feedforward neural networks?
-Unlike feedforward neural networks, where data flows in one direction from input to output, RNNs have a feedback loop that allows the output of a layer to be sent back as input for the next time step, enabling them to handle sequential data.
What are some common applications of recurrent neural networks (RNNs)?
-RNNs are used in a wide range of applications, including speech recognition, image captioning, driverless cars, document classification, video frame classification, and time series forecasting.
What challenge does training recurrent neural networks typically present?
-Training RNNs can be difficult due to the vanishing gradient problem, where gradients become very small during backpropagation, especially when training over many time steps, leading to the decay of information over time.
How does the vanishing gradient problem affect RNN training?
-The vanishing gradient problem in RNNs occurs because each time step in the network is like a separate layer in a feedforward network. When training over many time steps, the gradients can become exponentially smaller, making it harder for the model to learn long-term dependencies.
What are some techniques used to mitigate the vanishing gradient problem in RNNs?
-To address the vanishing gradient problem, techniques like gating (e.g., GRU and LSTM), gradient clipping, steeper gates, and better optimizers are commonly used.
Why are GPUs preferred over CPUs for training recurrent neural networks?
-GPUs are preferred for training RNNs because they can process data in parallel, leading to significantly faster training times. A study by Indico found that GPUs can train RNNs 250 times faster than CPUs, reducing training time from several months to just one day.
Under what circumstances would you choose a recurrent neural network (RNN) over a feedforward neural network?
-You would choose an RNN over a feedforward network when working with time series data or when the model needs to predict or classify sequences of values, such as in forecasting or sequential data analysis.
What type of data and tasks are best suited for RNNs compared to feedforward nets?
-RNNs are best suited for tasks involving time series data, where the output can be the next value in a sequence or several future values. Feedforward networks, on the other hand, are typically used for classification or regression tasks that involve single inputs and outputs.
Outlines

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantMindmap

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantKeywords

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantHighlights

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantTranscripts

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantVoir Plus de Vidéos Connexes
Pengenalan RNN (Recurrent Neural Network)

Recurrent Neural Networks (RNNs), Clearly Explained!!!

ANN vs CNN vs RNN | Difference Between ANN CNN and RNN | Types of Neural Networks Explained

3 Deep Belief Networks

What is Recurrent Neural Network (RNN)? Deep Learning Tutorial 33 (Tensorflow, Keras & Python)

Attention is all you need
5.0 / 5 (0 votes)
