AQA A’Level Hash tables - Part 1
Summary
TLDRThis video script introduces hash tables as a data structure that combines the benefits of arrays and linked lists for efficient data retrieval. It explains the concept of hashing, hash functions, and how they map keys to fixed indices in a hash table. The script also addresses collisions and their resolution through rehashing and linked lists, preventing clustering and ensuring fast access to data.
Takeaways
- 📚 **Hash Tables Overview**: The script introduces hash tables as a data structure that combines the best features of arrays and linked lists for efficient data retrieval.
- 🔑 **Key Concept**: A hash table uses a hash function to map a key to a fixed index in an array, allowing for quick data access.
- 🔄 **Collision Handling**: Collisions occur when different keys map to the same index; they are handled by techniques like rehashing.
- 📈 **Advantages of Arrays**: Arrays provide quick and easy random access to elements due to their fixed nature and direct indexing.
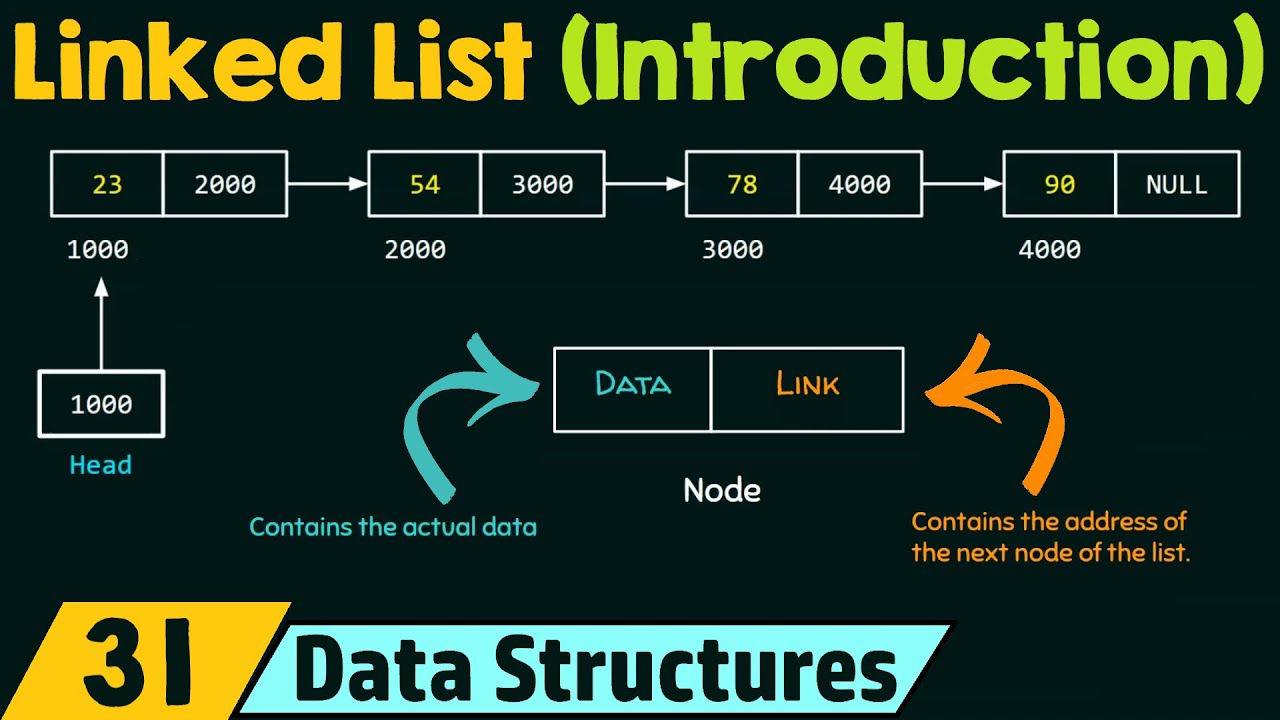
- 🔗 **Dynamic Nature of Linked Lists**: Linked lists can grow dynamically as they store data with pointers to the next element, but lack random access efficiency.
- 🚫 **Limitations of Arrays**: Arrays are static data structures with a fixed size, making them unsuitable for situations where data size is unpredictable.
- 🔍 **Inefficiency in Linked Lists**: Searching for an item in a linked list requires traversing from the start, which can be slow for large lists.
- 🔐 **Hash Function Role**: The hash function is crucial as it consistently generates the same hash value for a given key, facilitating data retrieval.
- 🔄 **Simple Hash Function Example**: The script demonstrates a simple hash function using modulo operation to convert keys into hash values.
- 🔄 **Collision Resolution**: When a collision occurs, the next available space in the hash table is used, which can lead to clustering if not managed properly.
- 🔗 **Use of Linked Lists in Hash Tables**: Linked lists are used in hash tables to resolve collisions, allowing for efficient storage even when multiple keys hash to the same index.
Q & A
What are the main topics covered in the upcoming videos on data structures?
-The upcoming videos will cover hash tables, including their concept, uses, simple hashing algorithms, collision handling through rehashing, and a comparison with arrays and linked lists.
What is the primary advantage of using arrays as a data structure?
-Arrays allow for quick and easy random access to all elements due to each element being associated with its own index.
What is a limitation of the array data structure mentioned in the script?
-A limitation of arrays is that they are fixed in size, making them static data structures that cannot easily grow.
How does a linked list differ from an array in terms of memory storage?
-In a linked list, each element is not stored continuously in memory; instead, each element contains data and a pointer to the next element's memory address.
What is the trade-off when using a linked list compared to an array?
-While linked lists are dynamic and can grow during program use, they do not allow for random access to elements and require sequential searching, which can be inefficient for large lists.
How does a hash table combine the best features of arrays and linked lists?
-A hash table combines the fast access of arrays with the dynamic nature of linked lists, making it ideal for scenarios where quick lookup, deletion, or insertion is a priority.
What is a hash function and how does it relate to a hash table?
-A hash function is a piece of code that takes a key and produces a hash value, which maps the key to a fixed index in the hash table. It's used to determine the storage location for data associated with a given key.
What is a collision in the context of hash tables?
-A collision occurs when two keys produce the same hash value, leading to a conflict over the same index in the hash table.
How is the collision handled in the example provided in the script?
-In the example, when a collision occurs, the next available space in the hash table is checked, and if that is also occupied, the data is stored in a linked list at the overflow for that index.
What is clustering, and how can it be a problem in hash tables?
-Clustering is the problem that arises when multiple items are stored in the same overflow list, increasing the likelihood of further collisions and slowing down the search process.
What is the solution proposed in the script to avoid clustering?
-The script suggests using linked lists to handle overflow, which helps maintain fast access times and avoids clustering by distributing colliding items across different overflow lists.
Outlines

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantMindmap

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantKeywords

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantHighlights

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenantTranscripts

Cette section est réservée aux utilisateurs payants. Améliorez votre compte pour accéder à cette section.
Améliorer maintenant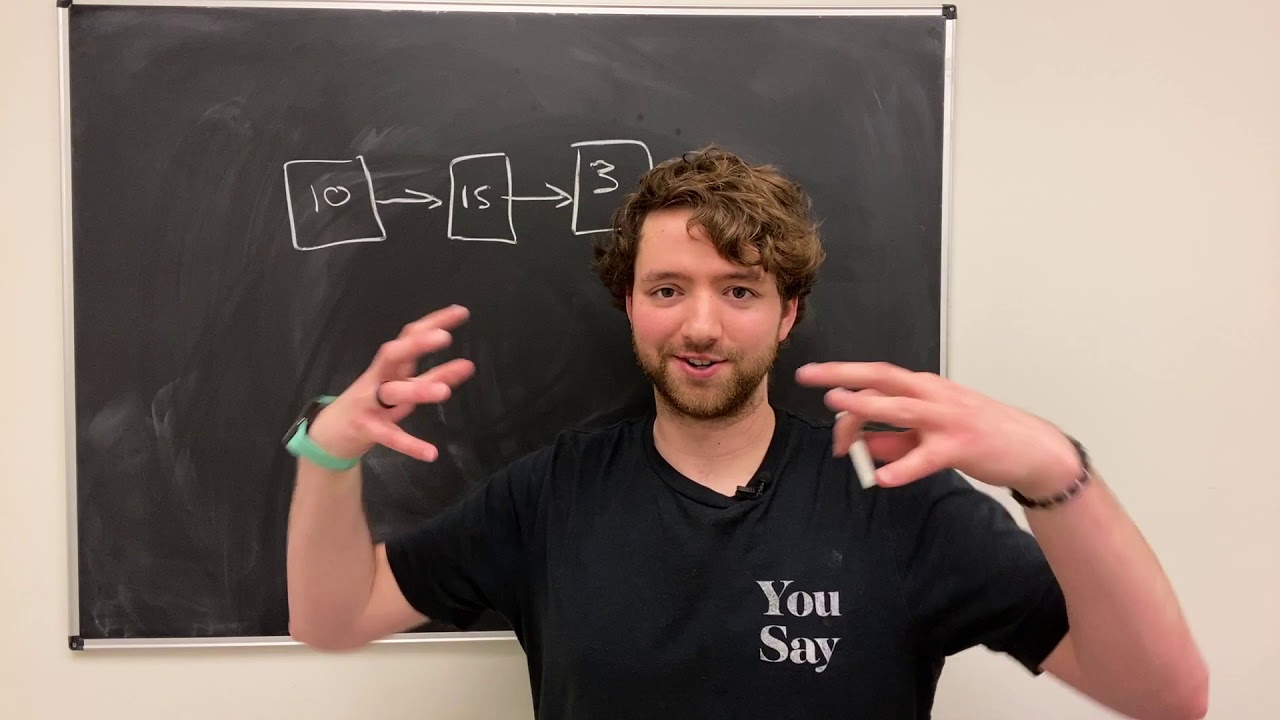




5.0 / 5 (0 votes)
