K-means Clustering dengan Excel
Summary
TLDRIn this video, the K-means clustering method is explained in detail, showing how to classify data into clusters. The process begins with selecting initial centers, followed by calculating distances using the Euclidean formula. Data points are then assigned to the nearest center, and the centers are updated by calculating the averages of points in each cluster. The iteration continues until the class assignments stabilize. The video demonstrates this process step by step using Excel formulas, offering a clear guide to implementing the K-means algorithm for data classification.
Takeaways
- 😀 Initialize cluster centers with given values to start the k-means clustering process.
- 😀 🧮 Use the Euclidean distance formula to calculate the distance between each data point and the cluster centers.
- 😀 🧑🏫 Assign each data point to the nearest cluster center based on the calculated distances.
- 😀 🔄 Recalculate the cluster centers by finding the average of all points in each cluster after assignment.
- 😀 🛑 Check if the clusters have stabilized by comparing the class assignments from the current iteration to the previous one.
- 😀 🔁 Repeat the steps of calculating distances, assigning clusters, and updating centers until convergence is reached.
- 😀 💻 Excel functions such as `IF` and `MIN` can be used to automate class assignment and identify the nearest cluster center.
- 😀 📊 Visualize the clusters by color-coding them for better distinction (e.g., red for Class 1, orange for Class 2).
- 😀 🧑💼 K-means clustering is useful for grouping data based on similarity, helping with data analysis and pattern recognition.
- 😀 📏 Ensure that the Euclidean distance formula is applied accurately for proper clustering results.
- 😀 🎯 Convergence occurs when there are no further changes in the cluster assignments, signaling the algorithm has completed.
Q & A
What is the purpose of K-means clustering?
-K-means clustering is a machine learning algorithm used to classify data points into groups or clusters based on similarity. It helps in organizing data into distinct categories.
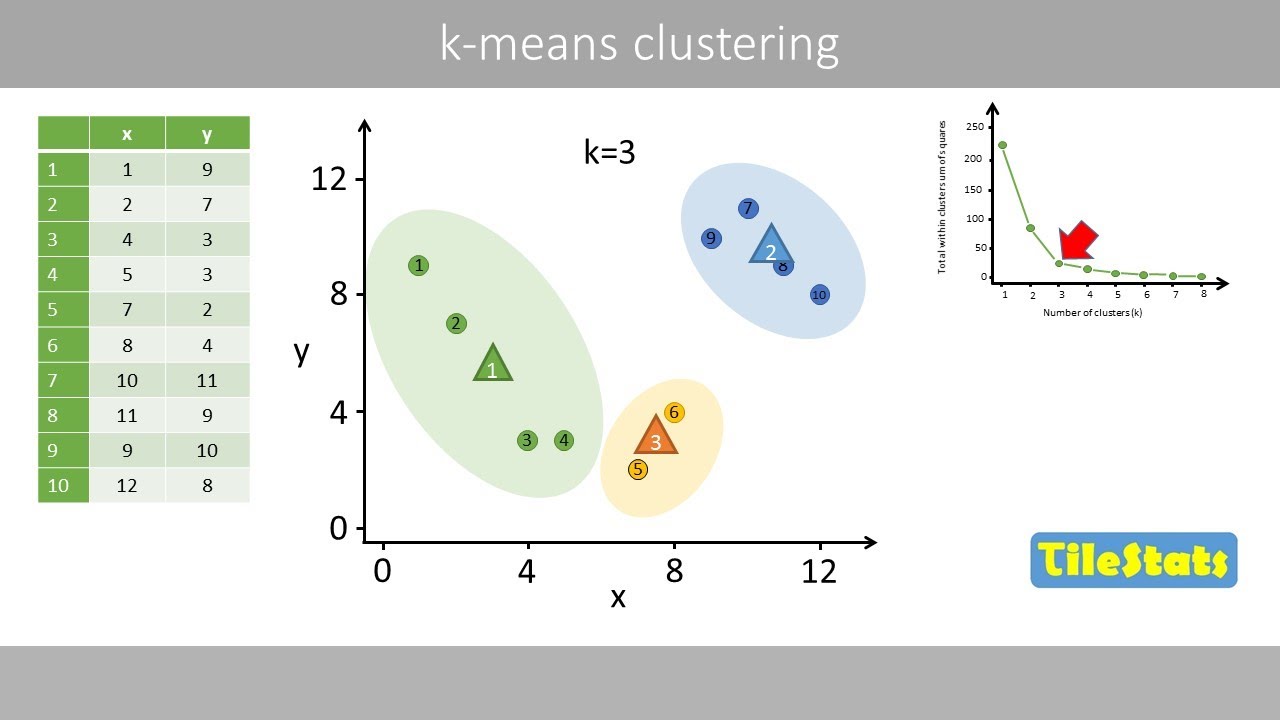
What are the initial centroids in this example, and why are they important?
-In this example, the initial centroids are (10.9, 12.6), (3.4, 11.3), and (3.2, 3.4). These centroids serve as starting points for the algorithm, and they influence the formation of clusters. The algorithm will iterate and adjust these values to better fit the data.
How is the Euclidean distance used in K-means clustering?
-The Euclidean distance formula is used to calculate the distance between each data point and the centroids. The formula is: √((x_i - x_center)^2 + (y_i - y_center)^2). This helps to assign data points to the closest centroid.
Why do we need to calculate the distance between points and centroids?
-Calculating the distance between points and centroids allows the algorithm to classify each data point by assigning it to the nearest centroid, which helps in forming clusters based on similarity.
How does the algorithm assign points to clusters?
-The algorithm assigns each data point to the cluster of the centroid with the shortest distance. This ensures that points that are closer to a particular centroid are grouped together.
What happens after the points are assigned to clusters?
-Once the points are assigned to clusters, the centroids are recalculated as the average of all points in each cluster. This is done to refine the centroids and improve the clustering accuracy.
How is the new centroid calculated?
-The new centroid is calculated by finding the average of all data points assigned to a cluster. This involves averaging the x and y coordinates of the points in each group.
What is the stopping criterion for the K-means algorithm?
-The K-means algorithm stops when the centroids no longer change significantly between iterations, meaning the cluster assignments remain the same. A comparison of the current and previous class assignments helps determine if the algorithm should continue.
How does Excel help in implementing the K-means algorithm?
-In Excel, formulas such as the Euclidean distance formula, IF statements, and ABS functions are used to calculate distances, assign points to clusters, and check for changes in assignments. Excel's functionality makes it easy to implement and visualize the steps of K-means clustering.
What role does the ABS function play in the stopping condition?
-The ABS function helps calculate the absolute difference between the current and previous class assignments. If the difference is zero, the algorithm stops; otherwise, it continues until the class assignments stabilize.
Outlines

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraMindmap

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraKeywords

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraHighlights

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraTranscripts

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahora



5.0 / 5 (0 votes)
