Advanced Retrieval - Multi-Vector ("More Vectors Are Better Than One")
Summary
TLDRThe video discusses the multi-vector retrieval method, which enhances document search by using embeddings from summaries instead of the original documents. This approach suggests that summaries can provide denser, more relevant information for embedding, potentially improving search results. The speaker details the process of transforming original documents into summaries, generating embeddings from these summaries, and retrieving the original documents for context in responses. The method is versatile, encouraging experimentation with different document transformations tailored to specific needs, and sets the stage for future explorations into related retrieval techniques.
Takeaways
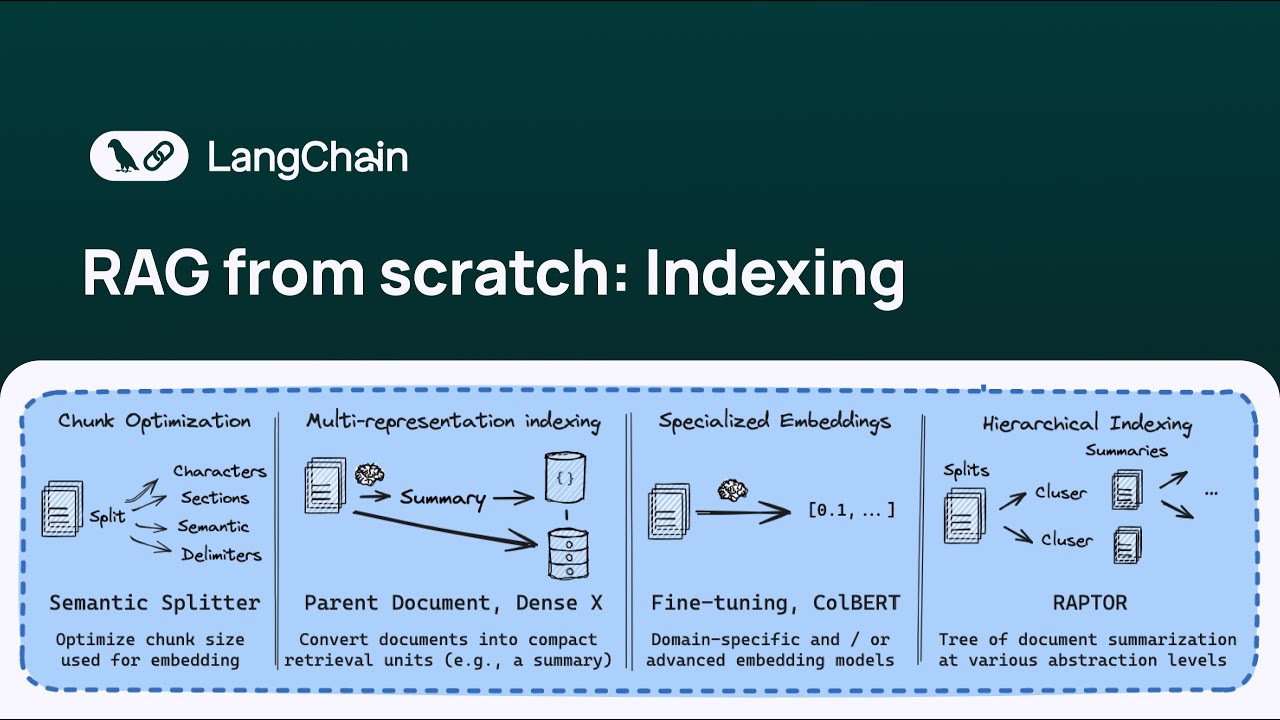
- 😀 Multi-vector retrieval enhances traditional document search by utilizing embeddings from summaries instead of original documents.
- 😀 The standard retrieval method creates one embedding per document, but multi-vector retrieval suggests alternative embeddings may yield better results.
- 😀 Summaries can be more information-dense, making them advantageous for generating embeddings that improve search accuracy.
- 😀 The process involves summarizing documents, embedding those summaries, and using them to perform similarity searches against queries.
- 😀 Original documents are retrieved based on their association with the most relevant summaries, providing context for responses.
- 😀 Beyond summaries, hypothetical questions can also be embedded for improved retrieval accuracy.
- 😀 The parent-child document retriever technique breaks larger documents into smaller chunks for more precise information retrieval.
- 😀 The setup for multi-vector retrieval requires both a vector store (for embeddings) and a document store (for original documents).
- 😀 Each summary and original document should be linked using a unique ID to facilitate accurate retrieval.
- 😀 Users are encouraged to experiment with different transformations to optimize the retrieval process for their specific needs.
Q & A
What is the main idea behind multi-vector retrieval?
-Multi-vector retrieval suggests using alternative embeddings, like summaries of documents, instead of relying solely on original document embeddings to enhance the search process.
How does traditional retrieval differ from multi-vector retrieval?
-Traditional retrieval uses embeddings that are directly tied to original documents, whereas multi-vector retrieval allows for the use of embeddings from transformed versions of the documents, such as summaries.
What are the benefits of using summaries for embeddings?
-Summaries can be denser with relevant information, which may improve the quality of the embeddings and lead to better retrieval results.
How are the embeddings generated in the multi-vector retrieval method?
-Embeddings are generated from summaries of original documents rather than from the documents themselves, allowing for a more focused representation of the content.
What role does the retriever play in multi-vector retrieval?
-The retriever matches queries with the most relevant summaries and retrieves the corresponding original documents to provide accurate context for responses.
Can you explain the significance of unique IDs in this method?
-Unique IDs link summaries with their original documents, ensuring that when a summary is retrieved, the correct original document can be accessed for context.
What type of data source was used in the code example?
-The code example used a Paul Graham essay, specifically the 'super linear' essay, as the data source for demonstrating the multi-vector retrieval method.
How does the code handle document splitting?
-The code splits the original document into smaller chunks to facilitate the summarization process and subsequent embedding generation.
What does the term 'Vector store' refer to in the context of this retrieval method?
-The Vector store holds the embeddings of the summaries, allowing for efficient similarity searches based on those embeddings.
What is the output when a similarity search is performed?
-The output includes the most similar documents based on the embeddings from the summaries, along with their associated metadata, such as unique IDs.
Outlines

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraMindmap

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraKeywords

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraHighlights

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraTranscripts

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraVer Más Videos Relacionados

RAG From Scratch: Part 3 (Retrieval)
RAG from scratch: Part 12 (Multi-Representation Indexing)

n8n RAG system done right!

Realtime Multimodal RAG Usecase Part 2 | MultiModal Summrizer | RAG Application #rag #multimodal #ai
Vector Databases simply explained! (Embeddings & Indexes)

How to chat with your PDFs using local Large Language Models [Ollama RAG]
5.0 / 5 (0 votes)
