Web Scraper App with Firecrawl
Summary
TLDREn este video, se presenta Firecrow, una herramienta poderosa para el web scraping, utilizada con fines educativos. El presentador detalla cómo configurar el entorno y los módulos necesarios, como OS, JSON y Pandas, para recopilar datos de criptomonedas del sitio Coin Market Cap. Se explica la creación de una función de scraping que optimiza la recolección de datos, incrementando el límite de contenido y verificando el formato de los datos. Al final, se muestran los resultados en formatos JSON y Excel, destacando la importancia de la fuente original del código y animando a los espectadores a explorar más sobre el scraping web.
Takeaways
- 😀 La sesión introduce una herramienta de web scraping llamada **FireCrow**.
- 🔍 El propósito de esta herramienta es educativo y no comercial.
- 📚 Se utilizan bibliotecas estándar como `os`, `json` y `pandas` para manejar datos y guardarlos en formatos legibles.
- 🛠️ Se define una función que permite obtener datos de cualquier URL, utilizando claves API de OpenAI y FireCrow.
- 📈 Se incrementa el límite de contenido principal a más de 100,000 para obtener más datos en comparación con el límite predeterminado de 10 filas.
- 💻 Se desea scrapear datos de criptomonedas, específicamente de **CoinMarketCap**, y se buscan campos como nombre, precio, capitalización de mercado y volumen.
- 🤖 Se recomienda usar el modelo GPT-4 o cualquier modelo preferido como Llama para el procesamiento.
- 📂 Los datos se guardan en una carpeta llamada **output**, y se generan archivos en formatos JSON y Excel.
- 🔗 Se alienta a los espectadores a explorar un repositorio de GitHub para obtener el código original y más detalles sobre la instalación y dependencias.
- 🌟 Se destaca la importancia de prácticas de codificación adecuadas y el uso ético de herramientas de web scraping.
Q & A
¿Cuál es el propósito principal del tutorial?
-El propósito principal del tutorial es enseñar a los espectadores cómo utilizar un scraper web llamado Firecrow para extraer datos de páginas web, específicamente de CoinMarketCap.
¿Qué herramientas se mencionan para llevar a cabo el scraping?
-Se mencionan varias herramientas, como Crow, OpenAI, y bibliotecas de Python como OS, JSON y Pandas para guardar los archivos en formatos Excel o CSV.
¿Por qué se necesita una clave de OpenAI y una clave de Firecrow?
-La clave de OpenAI es necesaria para acceder a los modelos de GPT y realizar solicitudes, mientras que la clave de Firecrow permite utilizar la API de este scraper para obtener datos.
¿Qué tipos de datos se pueden extraer de CoinMarketCap?
-Se pueden extraer datos como el nombre de la criptomoneda, su precio, capitalización de mercado y volumen de transacciones.
¿Cómo se maneja la salida de datos en el código?
-Los datos extraídos se guardan en un array, y luego se formatean para ser guardados en archivos JSON y Excel en una carpeta llamada 'output'.
¿Qué se debe hacer si el formato del código no es correcto?
-Si el formato del código no está en markdown, se debe mostrar un mensaje de error para alertar sobre el problema.
¿Cuáles son algunas de las funciones clave que se definen en el código?
-Una de las funciones clave es 'scrap_data', que se encarga de obtener la URL y leer las variables ambientales necesarias para el scraping.
¿Qué significa aumentar el límite de contenido principal a más de 100,000?
-Aumentar el límite de contenido principal permite obtener más filas de datos en comparación con el límite predeterminado de solo 10 filas, lo que mejora la cantidad de información extraída.
¿Por qué es importante tener un archivo requirements.txt?
-El archivo requirements.txt es importante porque lista todas las dependencias necesarias para ejecutar el proyecto, facilitando la instalación y el mantenimiento del entorno de desarrollo.
¿Qué información adicional se proporciona en el repositorio de GitHub mencionado?
-El repositorio de GitHub proporciona información sobre cómo instalar el scraper, su uso, dependencias, licencia y un archivo README útil para guiar a los usuarios.
Outlines

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraMindmap

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraKeywords

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraHighlights

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraTranscripts

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraVer Más Videos Relacionados

عملت 100 فيديو تعليمي في 100 ثانية فقط بالذكاء الاصطناعي مجانا

Tutorial SYMBALOO 2020 | Español | GUÍA para ORGANIZAR, CLASIFICAR y ALMACENAR MARCADORES y WEBS
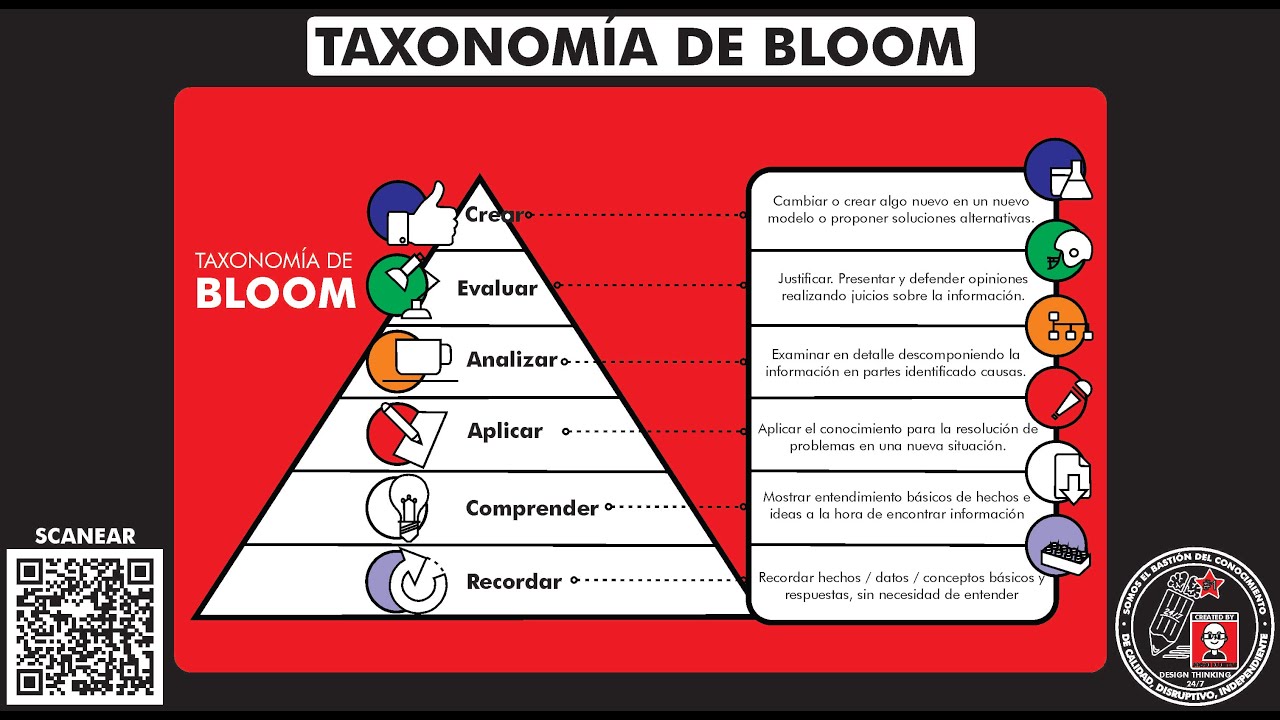
Que es y como usar la "TAXONOMÍA DE BLOOM" Temp 27 - Ep 1

Resolución Práctica de Problemas | PPS

5 Hábitos para comunicar mejor (cómo hablar mejor en público)
Taller 02 IA Aplicación Web Scraping
5.0 / 5 (0 votes)