Google's Tech Stack (6 internal tools revealed)
Summary
TLDRThis video script delves into Google's revolutionary in-house technologies, starting with the Google File System for managing petabytes of data and moving to MapReduce for efficient data processing. It covers the evolution of RPCs and gRPC, influenced by Google's Stubby, and touches on Borg, Google's precursor to Kubernetes for job scheduling. The script also explores databases like Bigtable and Spanner, and wraps up with Google's Pub/Sub messaging system, providing a comprehensive look at the tools that power Google's massive infrastructure.
Takeaways
- 😎 Google was once renowned for its innovation in distributed computing rather than data collection.
- 🗂️ The Google File System (GFS) was designed to handle petabytes of data with high throughput and replication across multiple servers.
- 🔄 GFS inspired the creation of Hadoop Distributed File System, which was open-sourced and widely adopted.
- 📈 MapReduce was Google's initial big data processing framework, simplifying distributed programming with map and reduce functions.
- 🚀 The simplicity of MapReduce allowed non-experts to process large datasets without deep knowledge of distributed systems.
- 🔧 Google's internal RPC system, Stubby, is similar to gRPC but with more focus on internal Google operations.
- 🤖 Borg, Google's internal job scheduler, influenced the development of Kubernetes, an open-source container orchestration system.
- 💾 Bigtable was created to overcome the limitations of relational databases, supporting high scalability and millions of requests per second.
- 🌳 Bigtable uses an LSM tree for data storage, providing efficient writes and reads with time as a third dimension.
- 📚 The technologies developed by Google, such as Bigtable, have inspired other NoSQL databases like Cassandra and DynamoDB.
- 📨 Pub/Sub is Google's message queuing system, offering a way to decouple services and handle high throughput in distributed architectures.
Q & A
What is the Google File System (GFS) and why was it created?
-The Google File System (GFS) is a proprietary distributed file system developed by Google in 2003 to handle large amounts of data generated by their search engine's web crawlers. It was designed to store petabytes of data and allow concurrent read and write access by multiple machines, with high throughput, consistent data, and replicated files.
How does the Google File System store data differently from traditional file systems?
-GFS stores data by splitting files into 64-megabyte chunks, each assigned a unique ID and stored on at least three servers for redundancy. It also uses a single Master server to maintain the directory structure and map files to their corresponding chunks, similar to the super block in a Linux file system but with distributed file chunks.
What inspired the development of the Hadoop Distributed File System (HDFS)?
-The Hadoop Distributed File System (HDFS) was inspired by Google's GFS. After Google published a paper on GFS, engineers at Yahoo developed HDFS, which was later open-sourced.
What is MapReduce and how does it simplify big data processing?
-MapReduce is a programming model and an associated implementation for processing and generating large datasets. It simplifies big data processing by allowing programmers to focus on implementing two functions: the map function that processes input data and produces intermediate key-value pairs, and the reduce function that aggregates these pairs by key.
Why did Google develop their own version of RPC called gRPC?
-Google developed gRPC to improve efficiency in data serialization by using binary format instead of human-readable JSON. It also provides type safety through the use of protocol buffers and is more suitable for environments where type safety and performance are critical.
What is the relationship between Borg and Kubernetes?
-Borg is Google's internal system for scheduling and managing jobs and tasks across thousands of machines. Kubernetes, an open-source tool created by Google, was influenced by Borg's design, with Borg jobs being similar to Kubernetes pods and Borg tasks being similar to Kubernetes containers.
What is Bigtable and how does it differ from traditional relational databases?
-Bigtable is a distributed storage system for managing structured data that is designed to scale and support millions of requests per second. Unlike traditional relational databases, Bigtable uses a sparsely populated, three-dimensional table structure with columns, rows, and multiple versions of a value at each row-column intersection.
How does the LSM tree in Bigtable work?
-The LSM tree in Bigtable is an acronym for Log-Structured Merge-tree. It stores writes in a memtable, which is kept in memory and sorted. Once the memtable reaches a certain size, it is flushed to an SSTable (Sorted String Table) on disk, where the data becomes immutable.
What is the significance of the CAP theorem in the context of Spanner?
-Spanner is a database system developed by Google that aims to break the CAP theorem, which states that it is impossible for a distributed system to simultaneously provide all three of the following guarantees: Consistency, Availability, and Partition tolerance. Spanner uses GPS and atomic clocks to synchronize time across data centers, enabling it to provide strong consistency and availability.
What is Cloud Pub/Sub and how does it function in Google's architecture?
-Cloud Pub/Sub is a message queuing service that allows for asynchronous communication between services. It is similar to other message queuing systems like RabbitMQ and Kafka. In Google's architecture, it helps to decouple services, handle high throughput, and ensure data durability.
What are some of the tools and technologies that have been influenced by Google's internal systems?
-Several tools and technologies have been influenced by Google's internal systems, including Hadoop's MapReduce and HDFS, which were inspired by Google's GFS and MapReduce. Kubernetes was influenced by Borg, and databases like DynamoDB, Cassandra, and Bigtable have also been influenced by Google's technologies.
Outlines

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraMindmap

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraKeywords

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraHighlights

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraTranscripts

Esta sección está disponible solo para usuarios con suscripción. Por favor, mejora tu plan para acceder a esta parte.
Mejorar ahoraVer Más Videos Relacionados
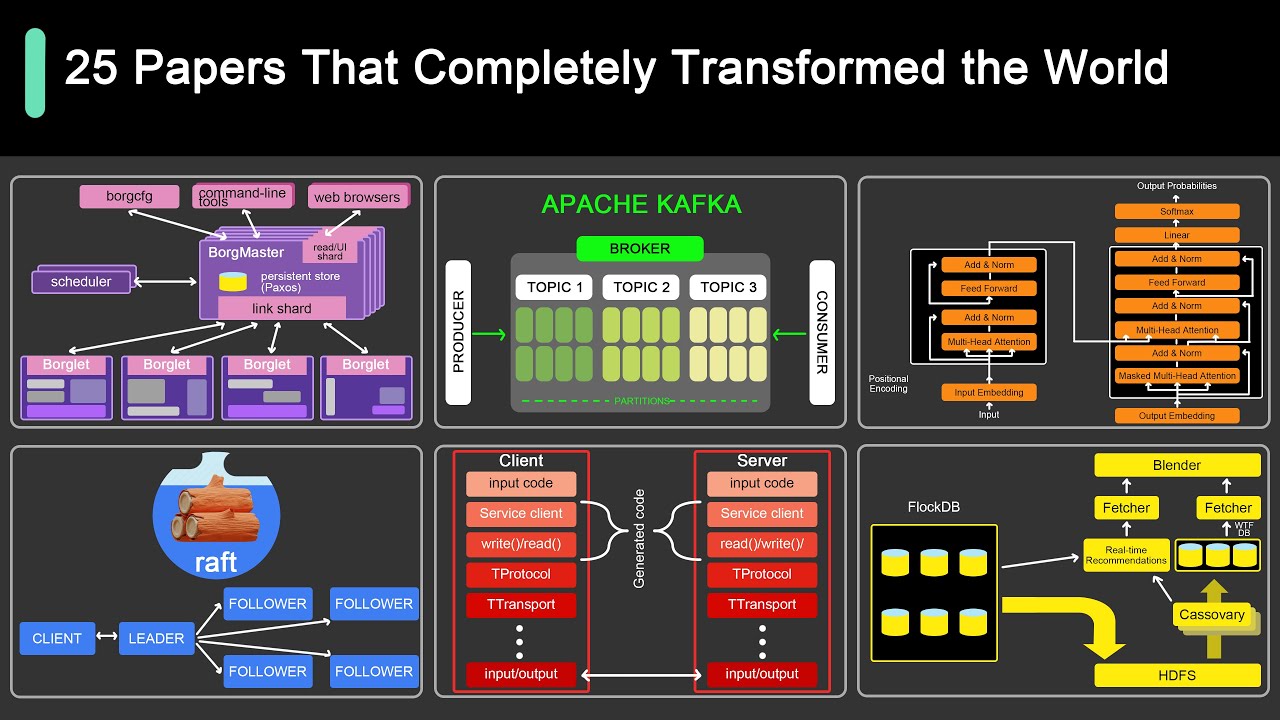
25 Computer Papers You Should Read!

Hadoop Ecosystem Explained | Hadoop Ecosystem Architecture And Components | Hadoop | Simplilearn

What is MapReduce♻️in Hadoop🐘| Apache Hadoop🐘

Map Reduce explained with example | System Design
Tutorial Wordcount Hadoop- Hadoop HDFS, dan MapReduce

Hadoop In 5 Minutes | What Is Hadoop? | Introduction To Hadoop | Hadoop Explained |Simplilearn
5.0 / 5 (0 votes)
