YOLO11 Architecture - Detailed Explanation
Summary
TLDRIn this video, the YOLO 11 architecture is explored in-depth, offering an overview of its key components: the backbone, neck, and head. Viewers will learn how YOLO 11 improves object detection through new features like the SPF and C2 PSA blocks. The video explains the model's variants (Nano, Small, Medium, Large, Extra Large), their parameters, and how the architecture processes images for accurate predictions. With detailed breakdowns of layers like convolution blocks, upsampling, and detection, this video provides a comprehensive yet accessible guide to understanding YOLO 11’s advancements in object detection.
Takeaways
- 😀 YOLO 11 is the latest version of the YOLO architecture, setting new standards for object detection.
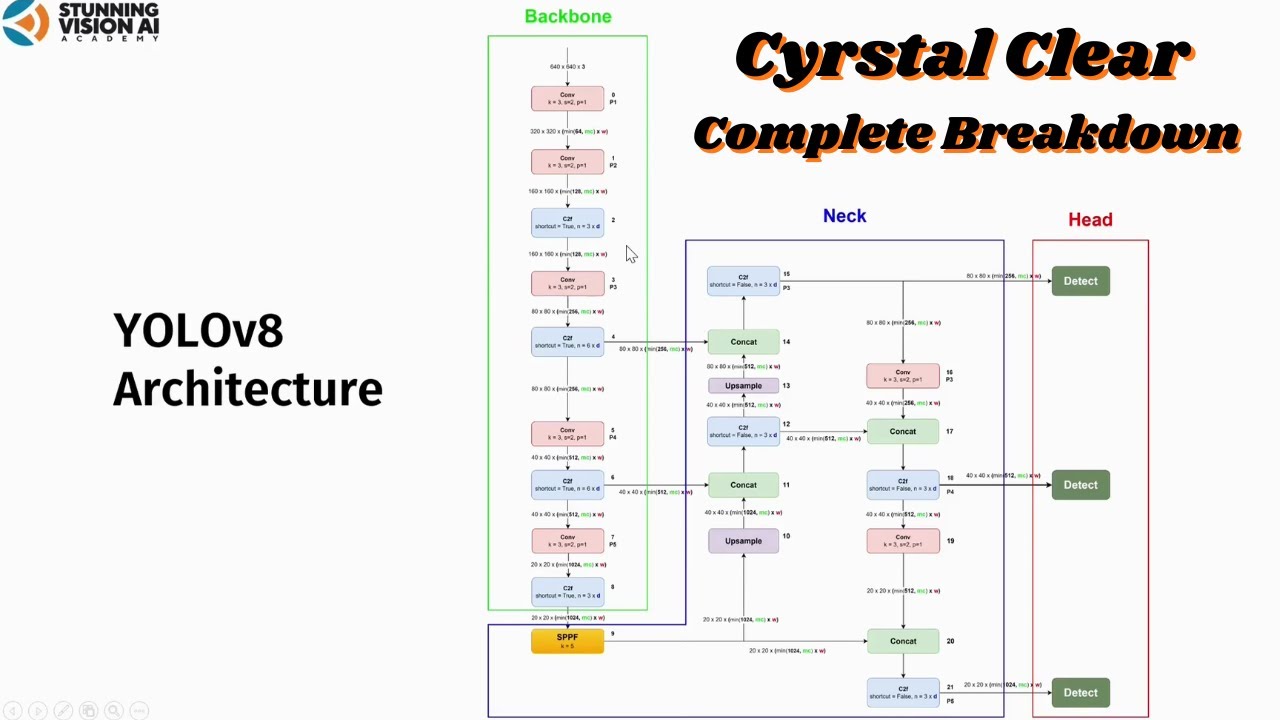
- 😀 The architecture is divided into three main parts: the Backbone (feature extractor), the Neck (feature combiner), and the Head (final output layer).
- 😀 YOLO 11 comes in five variants based on depth, width, and max channels, allowing for flexible model scaling.
- 😀 The Backbone is made up of several convolutional blocks that reduce the image resolution and extract features at various levels.
- 😀 The Neck uses blocks like C3 K2 and SPF to combine features from the Backbone and handle different object sizes.
- 😀 The C2 PSA block in YOLO 11 enhances the model’s ability to learn relationships between features at different positions.
- 😀 YOLO 11 introduces the upsampling technique to increase feature map resolution without losing information.
- 😀 Concatenation layers are used to merge feature maps from different blocks, improving the model’s ability to detect objects at multiple scales.
- 😀 The Head consists of Detect blocks that specialize in detecting small, medium, and large objects, using combined feature maps from the Backbone and Neck.
- 😀 Depth and width multiples in YOLO 11 provide a way to adjust the complexity of the model depending on the use case or hardware limitations.
Q & A
What is YOLO 11, and how does it compare to previous versions?
-YOLO 11 is an advanced version of the YOLO (You Only Look Once) object detection model. It improves upon previous versions like YOLO 10 by enhancing the object detection capabilities, but since no official paper has been released, its exact features and architecture are derived from source code analysis.
What are the three main parts of the YOLO 11 architecture?
-The three main parts of YOLO 11's architecture are the backbone, the neck, and the head. The backbone extracts features, the neck combines them, and the head predicts classes and bounding box regions.
How are the YOLO 11 variants determined?
-The YOLO 11 variants are determined by three parameters: depth multiple, width multiple, and max channels. These parameters influence the number of blocks and channels in the architecture, with variants like Nano, Small, Medium, Large, and Extra Large.
What role does the backbone play in YOLO 11?
-The backbone in YOLO 11 is responsible for feature extraction. It is composed of several convolution layers that extract distinct features at various resolution levels, which are crucial for the object detection task.
How does the YOLO 11 backbone process images?
-The YOLO 11 backbone processes images by using convolutional blocks with a kernel size of 3 and a stride size of 2, which reduces the spatial resolution of the input image at each layer. For example, a 640x640 image becomes 320x320 after the first convolutional block.
What is the function of the neck in YOLO 11?
-The neck in YOLO 11 combines the features extracted by the backbone using various blocks like C3 K2 and C2 PSA. It helps refine the feature map and prepares it for detection by the head.
What is the C3 K2 block in YOLO 11?
-The C3 K2 block is a critical component of the YOLO 11 architecture. It uses parameters like 'n', 'c3k', and 'e' to control the depth and complexity of feature extraction. It is used multiple times in the model and adjusts its behavior based on the variant (N, S, M, L, XL).
What is the purpose of the C2 PSA block in YOLO 11?
-The C2 PSA block, or Cross-Stage Partial with Position Sensitive Attention, helps YOLO 11 learn global relationships between features at different positions. This enhances spatial representation and improves detection accuracy, especially for objects of varying sizes.
How does the upsample layer work in YOLO 11?
-The upsample layer in YOLO 11 increases the resolution of feature maps using a nearest neighbor upsampling method. It repeats the values of neighboring pixels to fill in new pixels, allowing for better feature resolution matching between different parts of the network.
What is the detect block in YOLO 11, and what does it specialize in?
-The detect block in YOLO 11 is responsible for detecting objects in the image. It specializes in detecting small, medium, and large objects, with different blocks targeting different object sizes. The outputs from these blocks are processed to generate the final bounding boxes and class predictions.
Outlines

Dieser Bereich ist nur für Premium-Benutzer verfügbar. Bitte führen Sie ein Upgrade durch, um auf diesen Abschnitt zuzugreifen.
Upgrade durchführenMindmap

Dieser Bereich ist nur für Premium-Benutzer verfügbar. Bitte führen Sie ein Upgrade durch, um auf diesen Abschnitt zuzugreifen.
Upgrade durchführenKeywords

Dieser Bereich ist nur für Premium-Benutzer verfügbar. Bitte führen Sie ein Upgrade durch, um auf diesen Abschnitt zuzugreifen.
Upgrade durchführenHighlights

Dieser Bereich ist nur für Premium-Benutzer verfügbar. Bitte führen Sie ein Upgrade durch, um auf diesen Abschnitt zuzugreifen.
Upgrade durchführenTranscripts

Dieser Bereich ist nur für Premium-Benutzer verfügbar. Bitte führen Sie ein Upgrade durch, um auf diesen Abschnitt zuzugreifen.
Upgrade durchführen




5.0 / 5 (0 votes)
