How RAG Turns AI Chatbots Into Something Practical
Summary
TLDRThe video explains the concept of Retrieval-Augmented Generation (RAG), a method that improves AI performance by retrieving accurate information from external documents instead of relying solely on pre-trained neural networks. It outlines the stages of RAG, including indexing, retrieval, and generation, and discusses its practical applications in tools like ThinkBuddy. RAG boosts AI's accuracy and cost-effectiveness without needing expensive fine-tuning. While considered a short-term workaround, its evolving complexity positions it as a significant field in AI research. The video also highlights tools and resources to implement RAG effectively.
Takeaways
- 🤖 Current AI chatbots are powerful but can be impractical in work settings due to hallucinations and inconsistencies.
- 📈 A short-term workaround called Retrieval-Augmented Generation (RAG) significantly improves chatbot accuracy and performance.
- 📚 RAG retrieves accurate information from external documents, allowing more cost-effective and reliable outputs without expensive AI training.
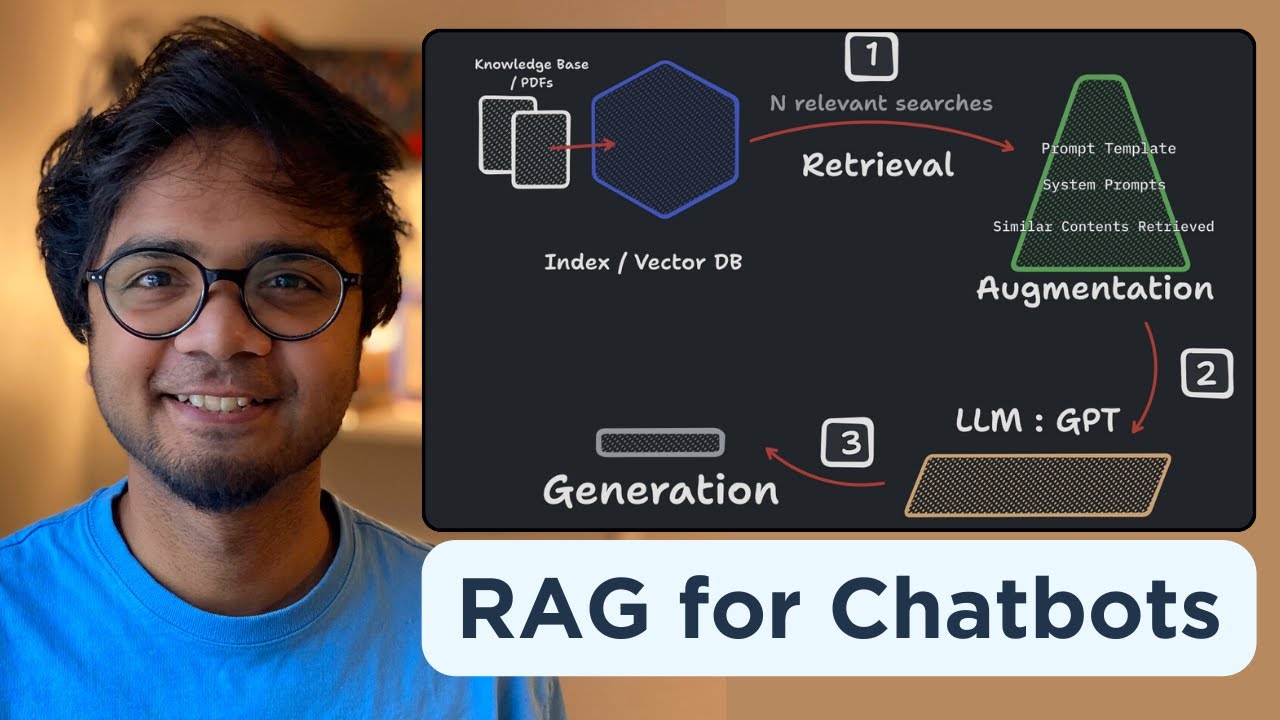
- 🧩 RAG is broken down into three stages: indexing documents, retrieving relevant data, and generating responses.
- 🧠 Vector databases and transformer models are used in RAG to encode and retrieve the most semantically relevant information.
- 🔍 Graph RAG is a promising new method that organizes information into knowledge graphs for better explainability and traceability.
- ⚙️ Hybrid search and input query rewriting help refine the retrieval process by improving accuracy and reducing irrelevant results.
- 💡 RAG pipelines can include re-ranking models and autocut functions to prioritize the most relevant responses and prevent hallucinations.
- 🚀 Think Buddy, an AI tool for Mac OS, leverages RAG principles to improve workflow with local storage and access to multiple models.
- 🛠️ Think Buddy offers deep integrations for screen capture, PDF processing, and code analysis, with voice input powered by Whisper.
Q & A
What is the main limitation of current AI chatbots according to the transcript?
-The main limitation of current AI chatbots is that they can hallucinate or generate incorrect information, making them unreliable for consistent use in professional settings.
What is RAG and how does it help mitigate the limitations of current AI models?
-RAG stands for Retrieval Augmented Generation. It improves AI performance by retrieving accurate information from external sources, such as a collection of documents, instead of relying solely on the AI's neural network. This reduces hallucination and enhances the usability of AI in tasks requiring specific and accurate data.
What are the three main stages of a naive RAG pipeline?
-The three main stages of a naive RAG pipeline are: 1) Indexing, where documents are divided into chunks and stored in a searchable vector database; 2) Retrieval, where relevant information is retrieved based on a query; and 3) Generation, where the AI generates a response using the retrieved content.
Why is RAG considered a 'short-term solution'?
-RAG is considered a short-term solution because it introduces additional moving parts like indexing, retrieval, and blending of data, which can introduce points of failure. It is seen as a workaround to the limitations of current AI models, rather than a long-term architectural solution.
What are some challenges associated with the RAG pipeline?
-Some challenges of the RAG pipeline include managing multiple components like document indexing, retrieval accuracy, and the AI's ability to blend and generate relevant responses. Any issue in these components can lead to poor output quality.
What is a 'knowledge graph' and how does it improve RAG?
-A knowledge graph is a structured representation of entities, relationships, and key claims extracted from documents. In RAG, it helps organize data more effectively, making retrieval more accurate and context-aware, and it improves the traceability and auditability of the AI's responses.
What role does 'reranking' play in the RAG pipeline?
-Reranking involves retrieving multiple top results and then passing them through a model to determine which results are the most relevant. This ensures that the most contextually appropriate response is used, reducing the chance of inaccurate results.
How can RAG help prevent AI hallucination?
-RAG can prevent hallucination by using a reranking model and auto-cut functions to remove unrelated retrieved results. If the AI cannot find a relevant match, it can be forced to admit that it does not know the answer, instead of generating an incorrect response.
What are some tools and libraries mentioned for building RAG systems?
-The transcript mentions several tools and libraries for building RAG systems, including Llama Index for general frameworks, Hugging Face for embedding models, Microsoft's GitHub for graph RAG implementation, and RAG-assess for evaluating RAG pipelines.
What is Think Buddy, and how does it enhance productivity for developers?
-Think Buddy is a macOS AI lab designed for developers. It combines strengths from multiple AI models like GPT-4, Claude, and Gemini Pro to generate responses by remixing the best parts of each. It integrates deeply with macOS, supports hotkeys for instant AI help, and handles various file formats like PDF and docx, making it a powerful tool for enhancing workflow.
Outlines

Dieser Bereich ist nur für Premium-Benutzer verfügbar. Bitte führen Sie ein Upgrade durch, um auf diesen Abschnitt zuzugreifen.
Upgrade durchführenMindmap

Dieser Bereich ist nur für Premium-Benutzer verfügbar. Bitte führen Sie ein Upgrade durch, um auf diesen Abschnitt zuzugreifen.
Upgrade durchführenKeywords

Dieser Bereich ist nur für Premium-Benutzer verfügbar. Bitte führen Sie ein Upgrade durch, um auf diesen Abschnitt zuzugreifen.
Upgrade durchführenHighlights

Dieser Bereich ist nur für Premium-Benutzer verfügbar. Bitte führen Sie ein Upgrade durch, um auf diesen Abschnitt zuzugreifen.
Upgrade durchführenTranscripts

Dieser Bereich ist nur für Premium-Benutzer verfügbar. Bitte führen Sie ein Upgrade durch, um auf diesen Abschnitt zuzugreifen.
Upgrade durchführenWeitere ähnliche Videos ansehen

W2 5 Retrieval Augmented Generation RAG
Build your own RAG (retrieval augmented generation) AI Chatbot using Python | Simple walkthrough

Retrieval Augmented Generation - Neural NebulAI Episode 9

Cosa sono i RAG, spiegato semplice (retrieval augmented generation)

Advanced RAG: Auto-Retrieval (with LlamaCloud)

[RAG Series #1] Hanya 10 menit paham bagaimana konsep dibalik Retrieval Augmented Generation (RAG)
5.0 / 5 (0 votes)
