Generative Adversarial Networks (GANs) - Computerphile
Summary
TLDRThis script delves into the fascinating world of Generative Adversarial Networks (GANs), exploring their potential for creating realistic images from random noise. It explains the adversarial training process where two networks, a discriminator and a generator, compete to improve each other's capabilities. The script also touches on the concept of latent space, where the generator's internal mapping of input to output can lead to meaningful manipulations of images, such as adding sunglasses to a portrait, showcasing GANs' remarkable ability to understand and generate complex visual data.
Takeaways
- 🧠 Generative Adversarial Networks (GANs) are powerful models used for creating new, realistic images by learning from existing data.
- 🎨 GANs have been applied to generate images of objects like shoes or handbags from simple sketches, although the resolution is currently limited.
- 🔍 The process involves training a neural network to classify images, such as distinguishing between pictures of cats and dogs, by adjusting internal models based on feedback.
- 🤖 The challenge with generative models is to not only classify but also create new samples from a given distribution, which requires understanding the underlying structure of the data.
- 📈 GANs use a two-part system: a generator that creates new images from random noise and a discriminator that evaluates the authenticity of the images.
- 🤝 The adversarial training process involves the generator and discriminator competing against each other, with the generator trying to fool the discriminator and the discriminator improving to detect fakes.
- 🏋️♂️ Adversarial training focuses on the system's weaknesses, similar to how a teacher might focus on a student's difficulties to improve their understanding.
- 🎲 The generator in GANs is rewarded inversely to the discriminator's judgment, encouraging it to produce images that are increasingly indistinguishable from real ones.
- 📊 The training involves a cycle where the discriminator is given real and fake images to learn the difference, while the generator uses this feedback to improve its outputs.
- 🛰️ The latent space of the generator, where random noise is input, is structured in a way that reflects meaningful characteristics of the images it produces, such as size, color, or features like wearing sunglasses.
- 🔑 The structured latent space allows for intuitive manipulation, where basic arithmetic operations on the latent vectors can result in meaningful changes in the generated images, reflecting an understanding of the image features.
Q & A
What are generative adversarial networks (GANs)?
-Generative adversarial networks are a class of artificial intelligence algorithms used in unsupervised machine learning, consisting of two parts: the generator, which creates new data instances, and the discriminator, which evaluates them as real or fake. They are known for their ability to generate realistic images and have various applications.
How do GANs generate new images?
-GANs generate new images by using a generator network that takes random noise as input and produces an image that should resemble the data it was trained on, such as a cat or a handbag.
What is the purpose of the discriminator in a GAN?
-The discriminator's role is to classify images as real or fake. It is trained to correctly identify images from the original dataset as real and those generated by the generator as fake.
How does adversarial training differ from traditional machine learning training?
-Adversarial training focuses on the system's weaknesses, similar to how a teacher might focus on a student's areas of difficulty. It involves an adversarial process where one part of the system tries to fool another, forcing both to improve.
What is the significance of the latent space in GANs?
-The latent space is a multi-dimensional space from which the generator draws random noise to create new images. It has the property that nearby points in this space produce similar images, which means it captures some of the structure of the images it can generate.
How does the generator improve over time in a GAN setup?
-The generator improves by receiving feedback from the discriminator. If the discriminator identifies a generated image as fake, the generator adjusts its parameters to produce more realistic images that can fool the discriminator.
What is the concept of a min/max game in the context of GANs?
-The min/max game refers to the competitive dynamic between the generator and discriminator. The generator aims to maximize the discriminator's error rate (by creating convincing fakes), while the discriminator aims to minimize its error rate (by correctly identifying real and fake images).
How can the training of a GAN be compared to teaching a child?
-In GANs, the training process can be compared to teaching a child by focusing on the areas where the learner is struggling. Just as a teacher might focus on a child's difficulty in distinguishing between certain numbers, the GAN focuses training on the generator's weaknesses as identified by the discriminator.
What is the role of randomness in the generator's process?
-Randomness is crucial in the generator's process as it provides the source of variability needed to create diverse and unique images. The generator uses this randomness to produce images that should ideally be indistinguishable from real images in the dataset.
Can the discriminator's feedback be used to directly improve the generator in a GAN?
-Yes, the discriminator's feedback can be used to directly improve the generator by employing gradient descent. The generator can use the gradient of the discriminator's error to adjust its weights and produce images that are more likely to be classified as real.
What is the potential outcome when a GAN has been trained for a sufficient amount of time?
-The ideal outcome of a well-trained GAN is that the generator produces images that are indistinguishable from real images, and the discriminator is unable to differentiate between real and fake images, outputting a 0.5 probability for both.
Outlines

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنMindmap

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنKeywords

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنHighlights

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنTranscripts

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنتصفح المزيد من مقاطع الفيديو ذات الصلة

How AI Image Generators Work (Stable Diffusion / Dall-E) - Computerphile

Generated Adversarial Network

mod04lec22 - Quantum Generative Adversarial Networks (QGANs)

What is Zero-Shot Learning?
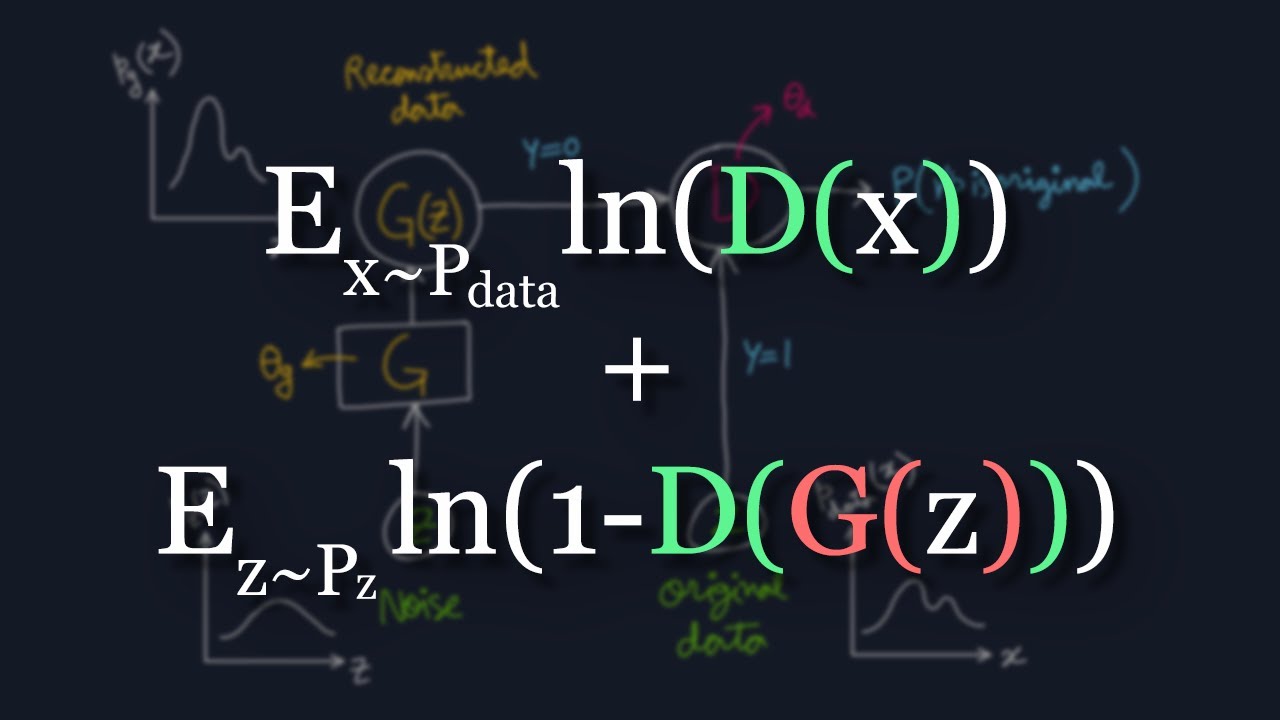
The Math Behind Generative Adversarial Networks Clearly Explained!

Why Does Diffusion Work Better than Auto-Regression?
5.0 / 5 (0 votes)
