Vector Databases simply explained! (Embeddings & Indexes)
Summary
TLDRThis video script delves into the rising popularity of vector databases, which are gaining traction in the AI era for their ability to index and store vector embeddings for efficient similarity searches. It explains the concept of vector embeddings created by machine learning models and the necessity of indexing for fast retrieval. The script covers use cases like equipping large language models with memory, semantic search, and recommendation systems. It briefly mentions various vector database options like Pinecone, Weaviate, and Chroma, inviting viewers to explore more in-depth comparisons.
Takeaways
- 🚀 Vector databases are gaining popularity due to their ability to handle large amounts of unstructured data efficiently.
- 💡 They are particularly relevant in the AI era, where companies are investing heavily in their development for applications like enhancing large language models with long-term memory.
- 🔍 Traditional databases and numpy arrays might suffice for many projects, but vector databases offer unique capabilities for specific use cases.
- 📚 The primary challenge with unstructured data like images, videos, and audio is that they don't fit neatly into relational databases without manual tagging or attributes.
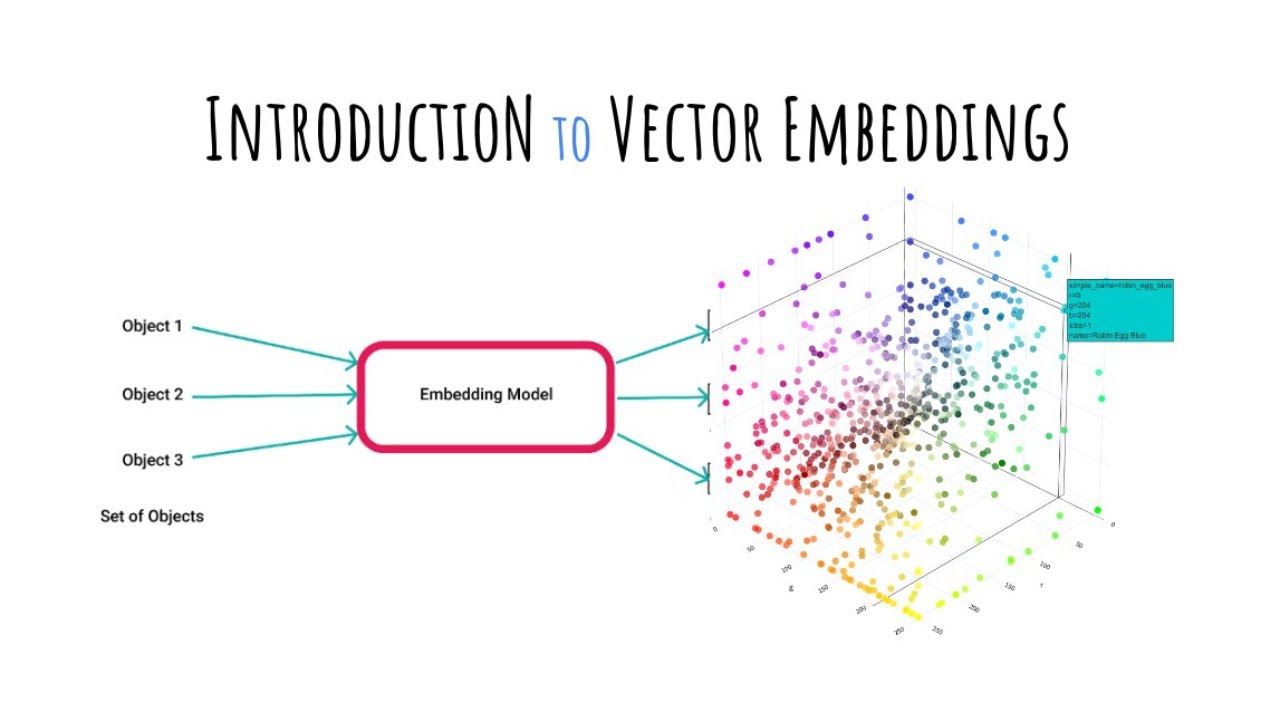
- 📈 Vector embeddings are lists of numbers derived from machine learning models that represent data in a way computers can understand and compare.
- 🔎 Vector databases index these embeddings to enable fast retrieval and similarity searches, which would be slow without proper indexing.
- 🌐 Use cases for vector databases include equipping AI models with memory, semantic search, similarity search in multimedia, and recommendation engines for e-commerce.
- 🛠️ The indexing process is crucial and involves mapping vectors to a data structure that facilitates efficient searching, a field of research in itself.
- 🏢 Several vector database options are available, such as Pinecone, Weaviate, Chroma, Redis, and Vespa, each with its own features and capabilities.
- 📝 The script suggests that while vector databases are fascinating, they may be an overkill for some projects, and simpler solutions might be more appropriate.
- 📈 The script concludes by inviting viewers to subscribe for more AI tutorials and explainer videos, indicating a focus on educational content.
Q & A
What is the primary reason for the recent fame of vector databases?
-Vector databases have gained fame due to companies raising significant investment to build them and the recognition of their potential as a new kind of database suitable for the AI era.
Why might using a traditional database or a numpy ND array be sufficient for some projects?
-For many projects, the complexity and capabilities of vector databases might be overkill, and simpler solutions like traditional databases or numpy ND arrays might work just fine for their needs.
What is the main challenge with storing unstructured data like images, videos, or audio in a relational database?
-The main challenge is that unstructured data cannot be easily fit into a relational database without manually assigning keywords or tags, as the database cannot search based on pixel values or similar metrics alone.
What are vector embeddings in the context of vector databases?
-Vector embeddings are lists of numbers that represent data in a numerical form that computers can understand, calculated by machine learning models to facilitate tasks like similarity search.
How do vector databases enable fast retrieval and similarity search?
-Vector databases enable fast retrieval and similarity search by indexing and storing vector embeddings, which allows for efficient querying and nearest neighbor searches based on distance metrics.
What is the significance of indexing in vector databases?
-Indexing is crucial in vector databases as it maps the vectors to a new data structure that enables faster searching, which would otherwise be extremely slow with thousands of vectors.
What are some use cases for vector databases?
-Use cases for vector databases include equipping large language models with long-term memory, semantic search, similarity search for images, audio, or video data, and as a ranking and recommendation engine for online retailers.
How can vector databases be used to enhance the capabilities of large language models?
-Vector databases can be used to give large language models like GPT-4 long-term memory by storing and retrieving vector embeddings that represent the context and meaning of data.
What is semantic search, and how can vector databases facilitate it?
-Semantic search is the process of finding information based on the meaning or context of a query rather than exact string matches. Vector databases facilitate this by using vector embeddings to understand and match the semantic similarity of data.
Can you name a few vector databases available for use?
-Some available vector databases include Pinecone, Weaviate, Chroma, Redis (with its vector module), Milvus, and Vespa AI.
What is the main takeaway from the video script regarding vector databases?
-The main takeaway is that vector databases are a specialized tool for handling unstructured data and enabling advanced search capabilities, particularly useful in AI applications but potentially overkill for simpler projects.
Outlines

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنMindmap

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنKeywords

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنHighlights

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنTranscripts

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنتصفح المزيد من مقاطع الفيديو ذات الصلة

What is a Vector Database? Powering Semantic Search & AI Applications

OpenAI Embeddings and Vector Databases Crash Course

Movie Recommender System in Python with LLMs
A Beginner's Guide to Vector Embeddings

LangChain Explained in 13 Minutes | QuickStart Tutorial for Beginners

Book Recommendation System in Python with LLMs
5.0 / 5 (0 votes)
