Karpathy's Obsidian RAG + Claude Code = CHEAT CODE
Summary
TLDRAndre Carpathy demonstrates a lightweight, Obsidian-powered knowledge system that mimics traditional RAG setups without complex databases or embeddings. By organizing information in a simple markdown-based vault, users can ingest documents, generate wikis, and query data using LLMs like Claude Code. The system leverages a structured file hierarchy with raw data, wiki folders, and a master index, allowing both humans and AI to navigate content efficiently. Ideal for solo developers or small teams, this approach offers transparency, cost-effectiveness, and ease of setup, while scaling considerations determine if traditional RAG systems are needed for larger datasets.
Takeaways
- 😀 Andre Carpathy demonstrates how to use Obsidian as a lightweight alternative to traditional RAG systems for managing large amounts of documents.
- 😀 Obsidian requires no vector databases, embeddings, or complex retrieval processes to handle document queries efficiently.
- 😀 The system works by organizing data into a clear file structure: a raw folder for incoming data, a wiki folder for processed content, and a master index for easy navigation.
- 😀 Users can ingest articles, PDFs, web pages, and repositories into the raw folder, which serves as a staging area before turning content into wikis.
- 😀 Cloud Code or LLMs like Claude Code can automate the creation of wikis from raw data, reducing manual effort and token usage.
- 😀 The Obsidian Web Clipper and community plugins like Local Images Plus allow seamless ingestion of web content, including images, into Markdown format.
- 😀 This approach allows solo operators or small teams to maintain full visibility of their data, unlike traditional RAG systems that often obscure content in a black box.
- 😀 The master index and wiki indexes provide structured navigation paths, enabling efficient queries and clear relationships between articles.
- 😀 While Obsidian is ideal for small to moderate-scale projects, traditional RAG systems may still be necessary for managing millions of documents efficiently.
- 😀 Starting with Obsidian is low-cost and experimental-friendly, letting users scale up to a full RAG setup only when needed.
Q & A
What is the main advantage of using Obsidian as a knowledge management system compared to traditional RAG systems?
-Obsidian offers a lightweight, simple setup for knowledge management without the complexity of vector databases, embeddings, or complicated retrieval processes, making it ideal for solo operators or small teams. It’s a more accessible solution for handling large amounts of documents with minimal overhead.
How does Andre Karpathy’s Obsidian-powered system solve the same problem as traditional RAG systems?
-Karpathy's Obsidian system solves the problem of handling large documents and querying them accurately by using a structured file system and data ingestion methods, combined with cloud code for querying, rather than relying on complex retrieval-augmented generation setups.
What are the key components of the Obsidian knowledge management system?
-The key components include the Obsidian vault, a raw folder (for raw data), a wiki folder (for generated wikis), and a master index markdown file that organizes the wikis. The raw data is ingested manually or through cloud code, and the wikis are dynamically created from this data.
How does the process of data ingestion work in the Obsidian system?
-Data ingestion involves collecting articles, papers, and repositories and storing them in a raw folder within the Obsidian vault. This folder acts as a staging area before the data is turned into organized wikis using cloud code.
What role does the master index markdown file play in the Obsidian system?
-The master index markdown file serves as a central directory, listing all the wikis created. It helps the querying process by directing cloud code to the relevant wikis when specific questions are asked.
How can users bring in external data into the Obsidian system?
-Users can bring external data into Obsidian through the Obsidian Web Clipper, which allows for turning web pages into markdown files and saving them in the raw folder. Images can also be included using the Local Images Plus plugin to ensure that images from the web pages are properly stored within the vault.
What is the function of cloud code in this setup?
-Cloud code is used to automate the process of creating wikis from the data stored in the raw folder. It can also be tasked with researching additional content to build more comprehensive wikis based on existing information.
Why is Obsidian considered a better choice for smaller teams or solo operators?
-Obsidian is simple to set up and requires minimal resources, making it ideal for smaller teams or solo operators. Unlike traditional RAG systems, it doesn't require complex infrastructure or advanced tools, which makes it cost-effective and efficient for handling a manageable amount of data.
What is the potential downside of using Obsidian for larger-scale knowledge management?
-For very large-scale operations dealing with millions of documents, Obsidian may become less efficient. In such cases, a full RAG system would likely be more suitable due to its ability to scale and handle massive datasets more effectively.
How does the simple structure of the Obsidian system improve the querying process?
-The simple, clear file structure of Obsidian ensures that documents are well-organized and easily navigable. This makes it easier for cloud code to query the data and for users to manually search for and access the information they need, without complex tool calls or systems.
Outlines

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنMindmap

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنKeywords

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنHighlights

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنTranscripts

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنتصفح المزيد من مقاطع الفيديو ذات الصلة

What is a Vector Database? Powering Semantic Search & AI Applications

Here Is How I Use Tags 🏷️ And Links 🔗️ In Obsidian To Manage My Zettelkasten 📝️
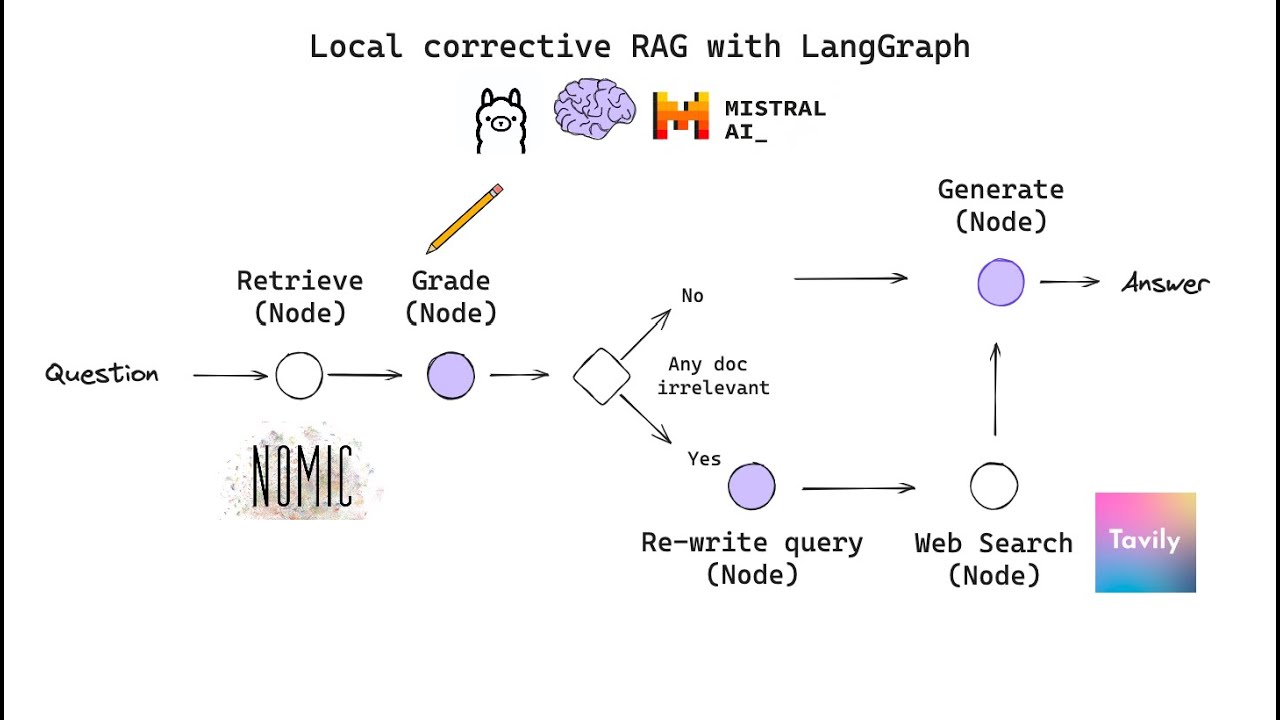
Building Corrective RAG from scratch with open-source, local LLMs

RAG From Scratch: Part 1 (Overview)
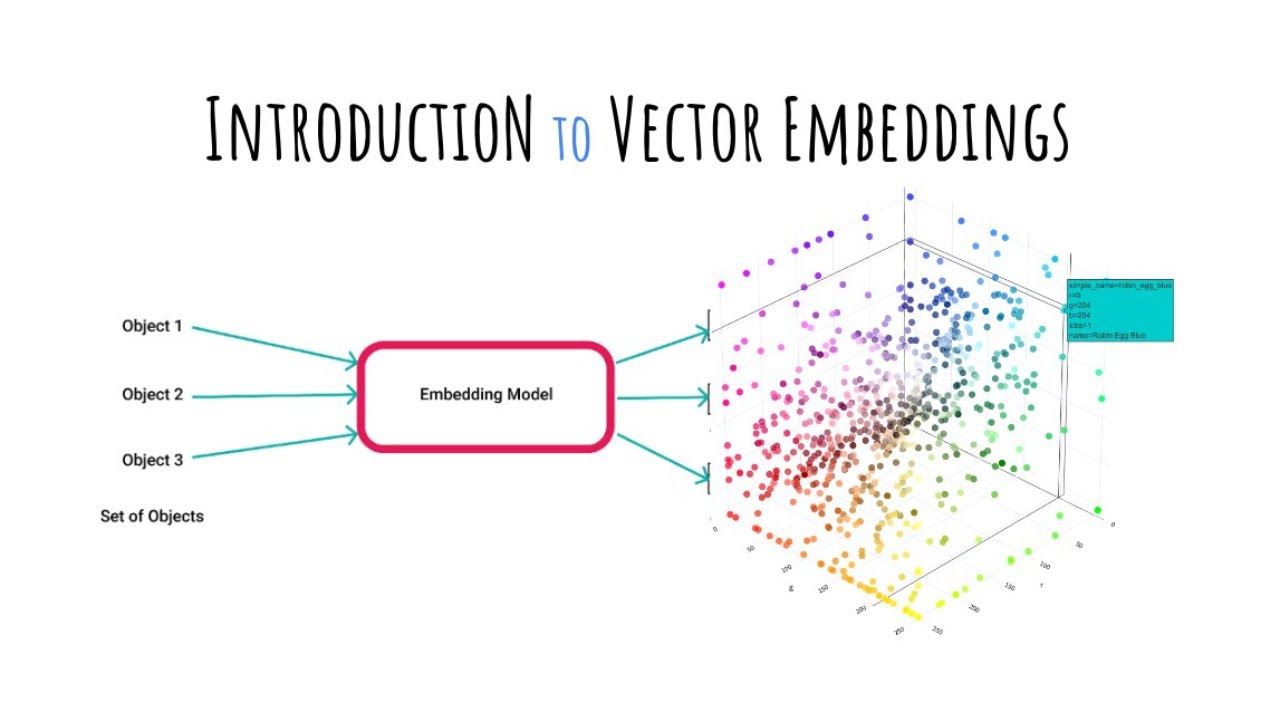
A Beginner's Guide to Vector Embeddings

Advanced RAG: Auto-Retrieval (with LlamaCloud)
5.0 / 5 (0 votes)
