When to Use Kafka or RabbitMQ | System Design
Summary
TLDRThis video explores the key differences between Kafka and RabbitMQ, highlighting their distinct purposes in distributed systems. Kafka is a stream processing system optimized for high throughput, retaining messages for replay and allowing fan-out messaging to multiple consumers. In contrast, RabbitMQ serves as a traditional message queuing system, routing messages to single consumers and managing complex routing tasks. The video discusses consumer patterns, message routing, acknowledgments, and practical use cases, providing insights into when to use each system effectively for tasks like real-time data analysis and job processing.
Takeaways
- 😀 Kafka is a stream processing system designed for high throughput and event streaming.
- 📬 RabbitMQ is a traditional message queue optimized for routing messages between producers and consumers.
- 🔄 Kafka retains all messages until their time-to-live expires, allowing for message replay even after consumption.
- 🔀 Kafka uses a fan-out model, meaning multiple consumers can receive copies of each message.
- ⚙️ RabbitMQ routes messages to a single consumer, making it ideal for processing tasks that require a one-to-one message handling.
- 📊 Kafka producers control message routing to topics and partitions, enhancing throughput but limiting post-production control.
- 🔗 RabbitMQ utilizes exchanges to dynamically route messages to queues based on defined criteria.
- ✅ Kafka employs offsets to track consumed messages, allowing consumers to fetch data from their last position.
- 📝 RabbitMQ requires consumers to send acknowledgments after processing messages, enabling message re-routing if not confirmed.
- 🚀 Kafka is suited for use cases involving stream data analysis, real-time communication, and event-driven architectures.
- 🔧 RabbitMQ excels in job queuing, microservice decoupling, and handling long-running tasks that need acknowledgment.
Q & A
What are the primary differences between Kafka and RabbitMQ?
-Kafka is designed as a stream processing system, capable of high throughput and retaining messages until their time-to-live expires, while RabbitMQ functions as a traditional message queue, focusing on message queuing and complex routing for moderate data volumes.
How do consumer patterns differ between Kafka and RabbitMQ?
-Kafka uses a fan-out model where multiple consumers receive all messages, while RabbitMQ ensures that each message is routed to exactly one consumer, allowing for better load balancing across processors.
What is the significance of message routing in Kafka?
-In Kafka, message routing is managed by the producer, which can send messages to multiple queues based on message properties, thus reducing the routing workload on the Kafka cluster and enabling better scaling.
How does RabbitMQ handle message routing?
-RabbitMQ uses exchanges that accept messages and route them to different queues based on defined rules, allowing for complex routing and load balancing among consumers.
What types of use cases are best suited for Kafka?
-Kafka is ideal for stream data analysis, event bus models, logging systems, and real-time communication, where high throughput and multiple data sinks are required.
In which scenarios is RabbitMQ more advantageous?
-RabbitMQ is better for long-running tasks, complex message routing, and systems with sporadic or bursty data flow, where message acknowledgment and processing reliability are crucial.
What approach does Kafka take for message acknowledgment?
-Kafka uses offsets instead of traditional acknowledgments. Each consumer keeps track of how many messages it has processed and commits offsets to indicate successful processing.
How does RabbitMQ handle message acknowledgment?
-RabbitMQ requires consumers to send acknowledgments after processing messages. If an acknowledgment is not received within a certain timeframe, RabbitMQ will reassign the message to another consumer.
What is the impact of data flow consistency on Kafka and RabbitMQ?
-Kafka is designed for consistent data flow, making it suitable for continuous streams of data, whereas RabbitMQ works well in scenarios with irregular data flow, focusing on individual message processing.
Can Kafka and RabbitMQ be used interchangeably?
-No, they solve different problems; using one in place of the other can lead to inefficiencies and complications due to their distinct designs and intended use cases.
Outlines

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنMindmap

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنKeywords

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنHighlights

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنTranscripts

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنتصفح المزيد من مقاطع الفيديو ذات الصلة
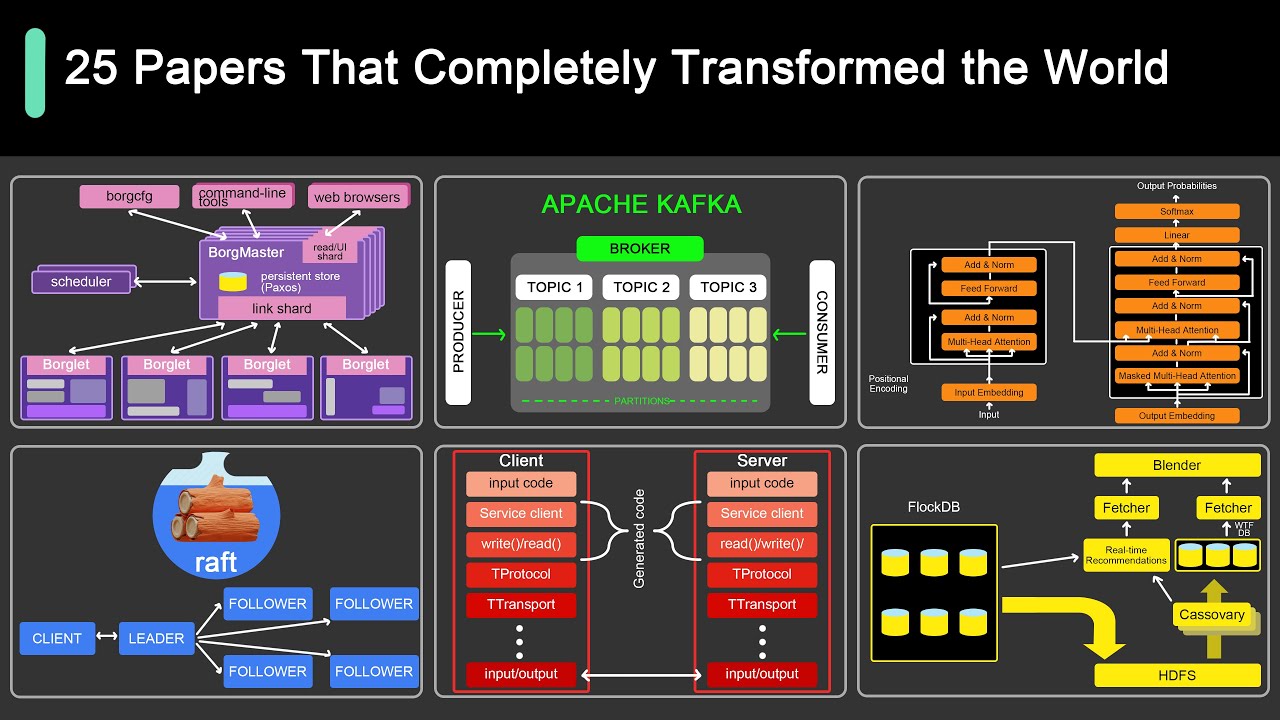
25 Computer Papers You Should Read!

Kafka vs. RabbitMQ vs. Messaging Middleware vs. Pulsar
COLONIALISMO X IMPERIALISMO #DicionárioDeHistória | E agora?

2. Motivations and Customer Use Cases | Apache Kafka Fundamentals
Konsep Dasar Sistem Operasi
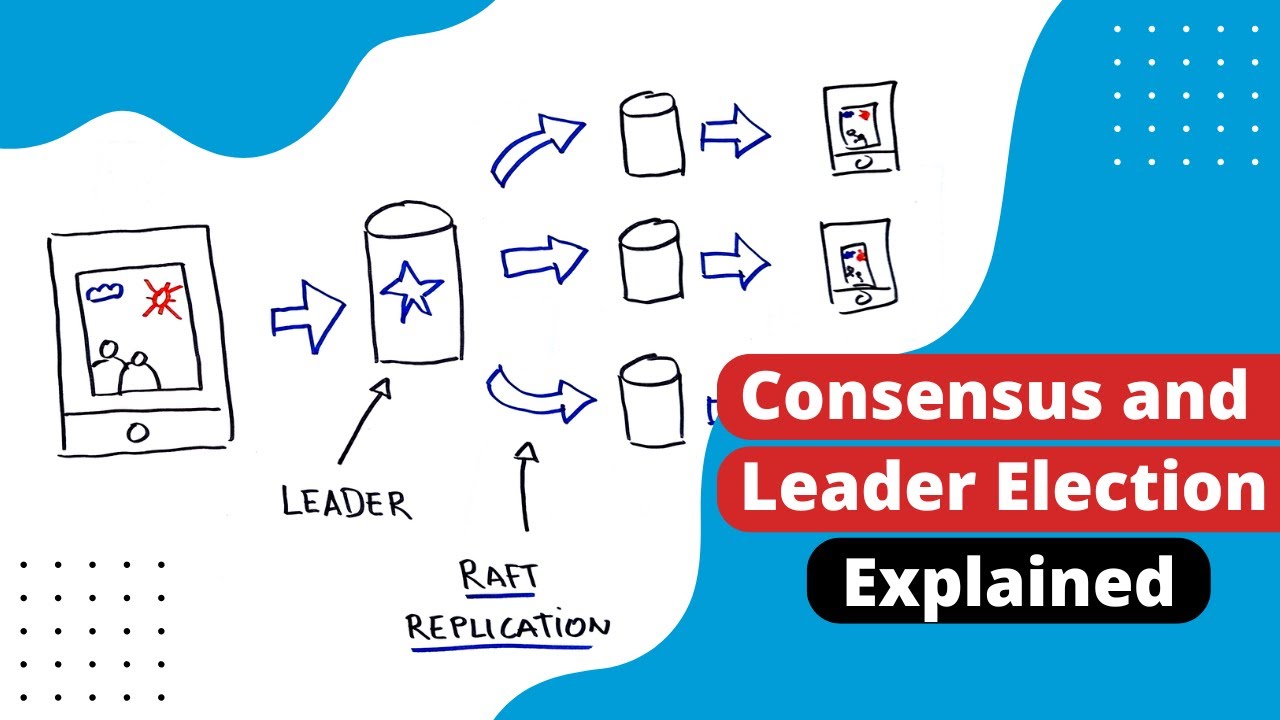
How do computers elect leaders? | Consensus and Leader Election Explained
5.0 / 5 (0 votes)
