Queueing theory (simple)
Summary
TLDRIn this video, Liz Thompson introduces queuing theory, a fundamental concept in industrial engineering and operations research. She explains the basics of queuing theory, focusing on a single server, single line system with a first-in, first-out approach. Key terms like arrival rate (lambda) and service rate (mu) are defined, along with their exponential distribution. Thompson demonstrates how to calculate capacity utilization, the number of items in the system, and waiting time using simple equations derived from complex mathematical models. She concludes with a practical example of applying queuing theory to a milling machine scenario, showing how to determine the machine's capacity utilization and the space needed for a waiting area.
Takeaways
- 📚 Queuing theory is a mathematical approach used in industrial engineering and operations research to model and analyze the management of queues.
- 🔄 It involves the study of items, people, or parts that need to be processed by a server, which performs work that takes time.
- 📈 The theory includes concepts like arrival rates (lambda) and service rates (mu), which are used to describe the flow and processing of items in a queue.
- 📉 Queuing systems can be configured in various ways, such as single-server, multiple-server, first-in-first-out (FIFO), or last-in-first-out (LIFO).
- 📊 Queuing theory uses equations to describe system performance, including capacity utilization, number of items in the system, and time in the system.
- 🔢 The capacity utilization (ρ) is calculated as the arrival rate (λ) divided by the service rate (μ), indicating how busy the server is.
- 📏 The number of items in the system is determined by the formula (λ / μ) / (1 - λ / μ), which accounts for both waiting and processing items.
- ⏱ The waiting time in the system is calculated as the number of items in the system divided by the arrival rate (λ), providing insight into the efficiency of the process.
- 🏭 An example provided in the script involves parts arriving at a milling machine, with calculations demonstrating how queuing theory can be applied to real-world industrial scenarios.
- 📐 The script also discusses the practical application of queuing theory in facilities design, such as determining the necessary waiting area size based on the number of items and their footprint.
Q & A
What is queuing theory?
-Queuing theory is a branch of mathematics that deals with the study of waiting lines, or queues, and is used in industrial engineering and operations research to analyze and optimize service systems.
What is the basic concept of queuing theory?
-The basic concept of queuing theory involves items, people, or parts that need to be processed by a server, which performs work that takes time. These items form a line, or queue, and are served by the server one at a time.
What is the difference between arrival rate (lambda) and service rate (mu) in queuing theory?
-The arrival rate (lambda) is the expected number of arrivals per unit of time, while the service rate (mu) is the average number of items that can be served per unit of time. Lambda is associated with the input rate to the system, and mu with the output rate.
What does a 'first in, first out' (FIFO) queue mean?
-A 'first in, first out' (FIFO) queue means that the order in which items arrive is the same order in which they are served, ensuring that the first item to arrive is the first to be processed.
What is the significance of the capacity utilization (rho) in a queuing system?
-Capacity utilization (rho) is the ratio of the arrival rate (lambda) to the service rate (mu), indicating the proportion of time the server is busy. It helps to understand how efficiently the system is being used.
How is the number of items in a queuing system calculated?
-The number of items in a queuing system is calculated using the formula L = (lambda / (1 - rho)), where L is the average number of items in the system, lambda is the arrival rate, and rho is the capacity utilization.
What does the waiting time in a queuing system represent?
-The waiting time in a queuing system represents the average time an item spends in the queue before being served, which can be calculated as W = L / lambda, where W is the waiting time, L is the number of items in the system, and lambda is the arrival rate.
Why is it important to understand the distribution of arrival and service times in queuing theory?
-Understanding the distribution of arrival and service times is important because it allows for more accurate predictions of system performance, such as queue length and waiting times, and helps in making informed decisions about system design and resource allocation.
How can queuing theory be applied in an industrial setting?
-Queuing theory can be applied in industrial settings to optimize production lines, manage customer service queues, and improve the efficiency of resource allocation, leading to better utilization of machinery and personnel.
What is an example of how queuing theory can be used to calculate space requirements for a waiting area?
-In the provided example, queuing theory is used to calculate the space needed for a waiting area by determining the average number of items waiting and multiplying it by the space required per item, which in this case was 4.9 items times 2 square feet per item, resulting in a 10 square feet area.
Outlines

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنMindmap

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنKeywords

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنHighlights

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنTranscripts

هذا القسم متوفر فقط للمشتركين. يرجى الترقية للوصول إلى هذه الميزة.
قم بالترقية الآنتصفح المزيد من مقاطع الفيديو ذات الصلة

(Part 1/4) Operations Research: Science and Technology for Informed Decision Making

Exploring COFF[IE]: Dunkin Donuts vs. Starbucks, an Industrial Engineering Analysis

RISET OPERASI atau OPERATION RESEARCH part #1 || JURUSAN MANAJEMEN - Albert Steinado
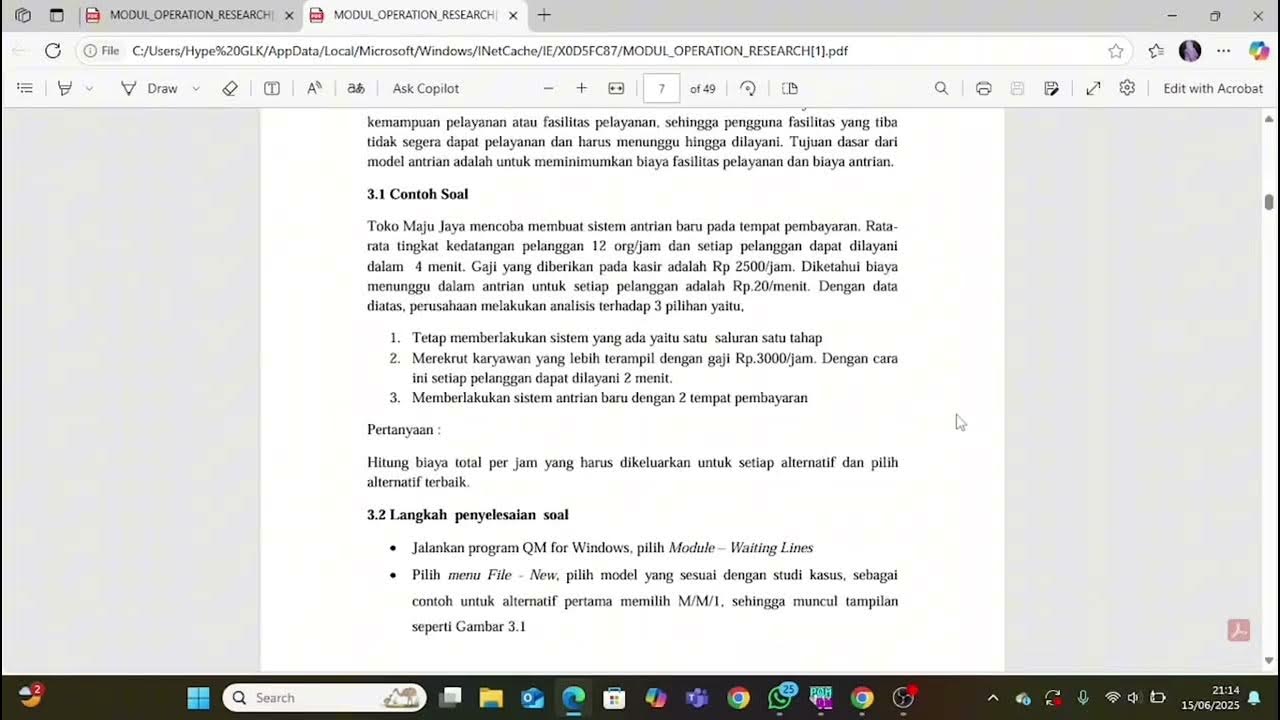
Tugas Riset Operasi Kelompok 2: Metode Waiting Lines Menggunakan Aplikasi POM-QM
What is Industrial Engineering by PIIE- NSC

Introduction to Industrial Engineering
5.0 / 5 (0 votes)
