Aditya Riaddy - Apa itu Apache Spark dan Penggunaanya untuk Big Data Analytics | BukaTalks
Summary
TLDRIn this presentation, Aditya Iftikar Riaddy, a Data Scientist at Bukalapak, introduces Apache Spark and its role in Big Data analytics. He explains how Spark, a powerful engine for large-scale data processing, enables fast, parallel, and distributed computing. The session covers Spark’s key libraries, including Spark SQL, Spark Streaming, MLlib, and GraphX, and highlights how they can be used for various data processing tasks like machine learning and real-time analytics. Additionally, the integration of Zeppelin, a web-based notebook tool, enhances data analysis and collaboration. Finally, real-world applications of Spark at Bukalapak are shared, focusing on user journey analytics and recommender systems.
Takeaways
- 😀 Apache Spark is a powerful engine for large-scale data processing, capable of handling data from hundreds of gigabytes to petabytes.
- 😀 Spark supports parallel processing across multiple cores and machines, enabling horizontal scaling for better performance.
- 😀 Apache Spark is a general-purpose tool that can be used for data processing, transformation, and machine learning.
- 😀 Spark provides high-level APIs in multiple programming languages including Scala, Java, Python, and R.
- 😀 Spark has several key libraries such as Spark SQL for data transformations, Spark Streaming for real-time analytics, MLlib for machine learning, and GraphX for graph processing.
- 😀 Spark Streaming enables real-time analytics using tools like Kafka and Flume.
- 😀 Zeppelin is a web-based notebook that integrates with Spark, making it easier to work with Spark without additional configuration.
- 😀 Unlike Jupyter Notebook, Zeppelin comes with built-in support for Spark, and offers features like collaboration and visualization tools.
- 😀 In Bukalapak, Spark is used for big data analytics like User Journey Analytics, which tracks buyer behavior to determine the influence of various pages on transactions.
- 😀 Zeppelin is also used in Bukalapak for prototyping recommender systems, enabling quick validation and adjustments of algorithms using smaller datasets before scaling up.
Q & A
What is Apache Spark and why is it suitable for big data analytics?
-Apache Spark is an engine for large-scale data processing. It is highly efficient in handling hundreds of gigabytes to petabytes of data and can be used for a variety of tasks, including data processing, transformation, and machine learning. Spark excels at parallel computing, which allows it to distribute tasks across multiple machines, enabling horizontal scaling and faster processing.
What are some of the main features of Apache Spark?
-Some key features of Apache Spark include its ability to run in parallel across multiple cores and machines, its high-level API for ease of use, and its support for multiple programming languages, including Scala, Java, Python, and R. Spark also supports a variety of libraries such as Spark SQL, Spark Streaming, MLlib, and GraphX for data analytics and machine learning tasks.
How does Spark differ from other parallel processing libraries?
-Spark differentiates itself by not only running in parallel at the core level but also enabling horizontal scaling. This means that it can distribute processing tasks across multiple machines, making it more scalable and faster than other parallel processing tools that might only leverage the cores of a single machine.
What are the primary libraries in Apache Spark and their functions?
-Apache Spark includes several important libraries: Spark SQL for data transformation (similar to data frames in Python), Spark Streaming for real-time analytics, MLlib for machine learning tasks, and GraphX for graph-based processing like PageRank and other algorithms.
What is Zeppelin and how does it enhance Spark's capabilities?
-Zeppelin is a web-based notebook tool that integrates directly with Spark, providing an easy-to-use interface for data analysis, coding, visualization, and collaboration. Unlike Jupyter Notebook, Zeppelin is pre-configured to work with Spark, making it easier to prototype and visualize big data analytics without complex setup.
How does Zeppelin differ from Jupyter Notebook in terms of Spark integration?
-The key difference is that Zeppelin is pre-integrated with Spark, while Jupyter Notebook requires additional configuration for Spark integration. Zeppelin also supports built-in visualization and can handle collaboration more efficiently, allowing multiple users to work on the same analysis simultaneously.
How is Apache Spark used for User Journey Analytics at Bukalapak?
-At Bukalapak, Apache Spark is used to process traffic data and track user interactions on the platform. By analyzing data from the homepage, product pages, and transactions, Spark helps to identify patterns and contributions of different pages to the user's journey and final purchase decisions.
What is the role of Spark in the recommender system at Bukalapak?
-Spark is used in the prototyping phase of Bukalapak's recommender system. It processes small datasets first to test and debug algorithms quickly before scaling up to process larger datasets for production. This allows for fast iteration and error correction in the development of personalized recommendations.
What are the benefits of using Spark for machine learning tasks?
-Spark’s MLlib library provides a comprehensive set of machine learning algorithms for tasks like classification, regression, and collaborative filtering. It allows for large-scale machine learning tasks to be performed much faster than traditional methods, thanks to its parallel processing capabilities.
Why is horizontal scaling important for big data processing in Spark?
-Horizontal scaling allows Spark to distribute data processing across multiple machines, significantly increasing its ability to handle very large datasets. This scalability is crucial for big data analytics, as it enables processing of data volumes that far exceed the capacity of a single machine.
Outlines

此内容仅限付费用户访问。 请升级后访问。
立即升级Mindmap

此内容仅限付费用户访问。 请升级后访问。
立即升级Keywords

此内容仅限付费用户访问。 请升级后访问。
立即升级Highlights

此内容仅限付费用户访问。 请升级后访问。
立即升级Transcripts

此内容仅限付费用户访问。 请升级后访问。
立即升级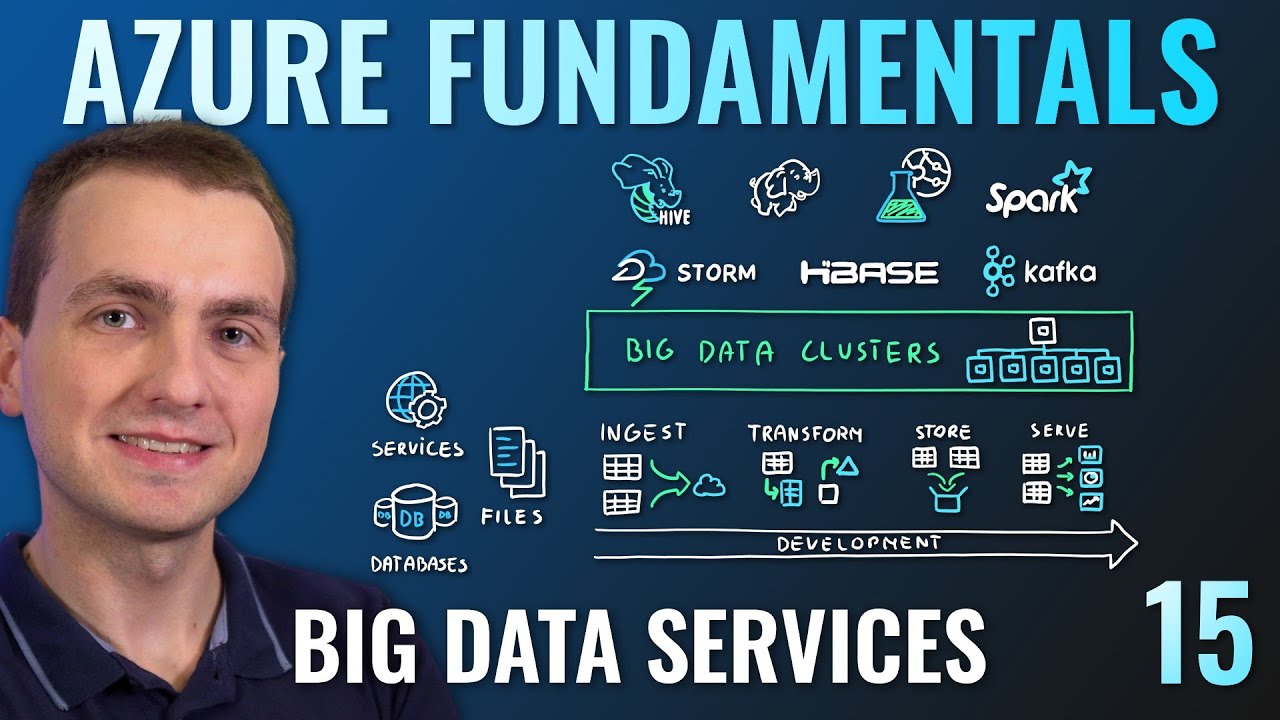




5.0 / 5 (0 votes)
