Optimizers - EXPLAINED!
Summary
TLDRThis video delves into the various optimizers used in machine learning to help neural networks learn more effectively. It explains the basics of gradient descent and its variants, including stochastic gradient descent, mini-batch gradient descent, and momentum-based optimizers. The script explores adaptive learning rate optimizers like AdaGrad, AdaDelta, and Adam, each designed to improve the efficiency of training by adjusting parameters intelligently. The video highlights how choosing the right optimizer depends on the specific problem being solved, whether for image generation, machine translation, or other tasks. The key takeaway is the importance of experimenting with different optimizers for optimal performance.
Takeaways
- 😀 Optimizers help neural networks learn by adjusting parameters (weights) to minimize the loss function.
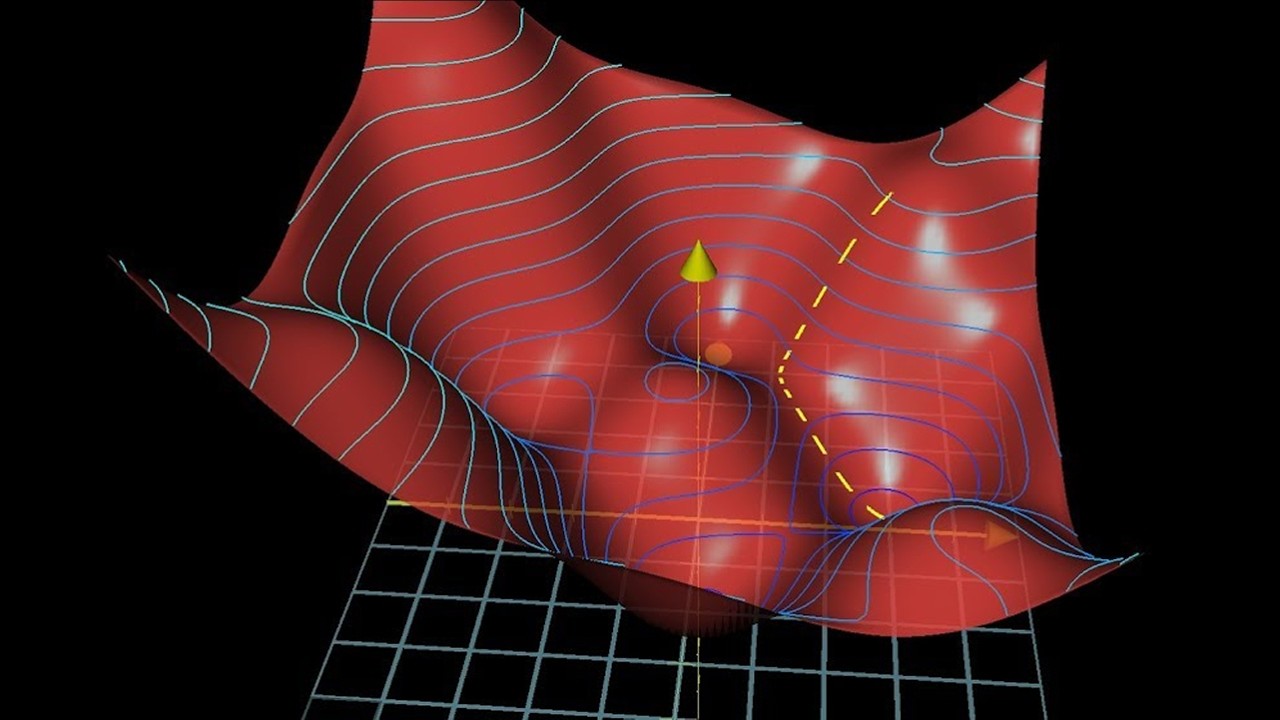
- 😀 Gradient Descent (GD) updates weights after processing the entire dataset, but large updates can prevent reaching optimal values.
- 😀 Stochastic Gradient Descent (SGD) updates weights after each data point, making it faster but introducing noise.
- 😀 Mini-batch Gradient Descent strikes a balance by updating weights after a subset of samples, reducing noise while maintaining efficiency.
- 😀 Momentum helps accelerate learning by considering the direction of previous updates, improving convergence speed.
- 😀 A potential issue with momentum is ignoring atypical samples, which may affect model accuracy.
- 😀 Adaptive learning rates allow optimizers to adjust the rate of learning along different directions of the loss function.
- 😀 Adadelta introduces a weight decay factor to prevent the learning rate from decaying too quickly and stagnating.
- 😀 Adam combines momentum and adaptive learning rates to achieve faster convergence and more accurate training.
- 😀 Advanced optimizers like Adamax and Nadam further improve performance with additional features like acceleration terms.
- 😀 The choice of optimizer depends on the specific problem being solved, such as image generation, segmentation, or machine translation.
Q & A
What is the role of optimizers in neural networks?
-Optimizers define how neural networks learn by adjusting the parameters (weights) to minimize the loss function, finding the optimal values for the weights that lead to the lowest loss.
What is the main issue with the traditional gradient descent algorithm?
-The main issue with gradient descent is that it updates the weights only after seeing the entire dataset, which can result in large steps that may cause the optimizer to overshoot the optimal value or get stuck near it without reaching it.
How does stochastic gradient descent (SGD) address the issues of gradient descent?
-SGD updates the weights after each individual data point, leading to more frequent updates and faster learning. However, this can introduce noise, causing the optimizer to make erratic jumps away from the optimal values.
What is mini-batch gradient descent, and how does it improve upon SGD?
-Mini-batch gradient descent updates the weights after processing a subset (mini-batch) of the data, providing a balance between the stability of full batch gradient descent and the speed of stochastic gradient descent.
How does momentum improve the training process in optimization algorithms?
-Momentum helps to smooth out updates by allowing the optimizer to build up speed in the direction of consistent gradients, which helps avoid erratic updates caused by noisy or outlier data.
What problem might arise from using momentum, and how can it be mitigated?
-Momentum may cause the optimizer to blindly ignore outliers, which can be a costly mistake. This can be mitigated by introducing an acceleration term that decelerates the updates as the optimizer approaches the optimal solution, allowing for finer adjustments.
What are adaptive learning rates, and how do they benefit optimization?
-Adaptive learning rates allow the optimizer to adjust the step size dynamically, increasing it in directions with larger gradients and decreasing it where gradients are small. This makes the optimizer more efficient in navigating irregular loss terrains.
What is the key advantage of AdaDelta over standard gradient descent algorithms?
-AdaDelta reduces the impact of old gradients by using a weighted average of past squared gradients, preventing the learning rate from decaying to zero and ensuring continued learning throughout the training process.
How does the Adam optimizer improve upon AdaDelta?
-Adam combines the advantages of AdaDelta and momentum by incorporating both an adaptive learning rate and the momentum of past gradients, allowing for more precise and faster convergence to the optimal solution.
What factors should influence the choice of optimizer for a neural network problem?
-The choice of optimizer depends on the specific task and the type of loss function involved, such as image segmentation, semantic analysis, or machine translation. The optimizer should be able to efficiently traverse the loss landscape for that specific problem.
Outlines

此内容仅限付费用户访问。 请升级后访问。
立即升级Mindmap

此内容仅限付费用户访问。 请升级后访问。
立即升级Keywords

此内容仅限付费用户访问。 请升级后访问。
立即升级Highlights

此内容仅限付费用户访问。 请升级后访问。
立即升级Transcripts

此内容仅限付费用户访问。 请升级后访问。
立即升级浏览更多相关视频

Neural Network (Simplest and easy to make)-Deep Learning

What is a Neural Network?

Complete Road Map To Prepare For Deep Learning🔥🔥🔥🔥

Trailer: Learn how to hack neural networks, so that we don't get stuck in the matrix!
Gradient descent, how neural networks learn | Chapter 2, Deep learning

Backpropagation in Neural Networks | Back Propagation Algorithm with Examples | Simplilearn
5.0 / 5 (0 votes)
