End to End Project using Spark/Hadoop | Code Walkthrough | Architecture | Part 1 | DM | DataMaking
Summary
TLDRIn this video, the creator introduces a new series on end-to-end project development using Big Data technologies, focusing on components from Apache Spark and Hadoop. The discussion centers on building a real-time streaming system architecture, detailing how data flows from various sources through a distributed messaging system (Kafka) to processing layers. Key components like Spark Streaming, HDFS, and Presto for querying are highlighted, along with visualization tools for reporting. The video sets the stage for a deeper exploration of each component in future episodes, encouraging viewers to subscribe for more technology insights.
Takeaways
- 😀 The channel focuses on technology videos related to Big Data, specifically using Apache Spark and Hadoop.
- 📊 A new series titled 'N2N Project Explanation' will cover end-to-end project development using Big Data technologies.
- 🔗 The reference architecture for the project includes a variety of data sources such as traditional databases and open APIs.
- 📦 Kafka is utilized as the distributed messaging system, allowing data to be streamed to consumers through topics.
- ⚙️ Spark Streaming is employed for processing data, with Zookeeper managing message identifiers.
- 🗄️ Processed data is stored in HDFS, enabling efficient data management and accessibility.
- 🔍 Hive tables are created for querying the data stored in HDFS, facilitating data analysis.
- 🚀 Presto serves as the distributed query engine, providing low latency responses for data retrieval.
- 📊 Visualization tools will be used to create dashboards for reporting purposes.
- 🔄 Future enhancements will include the integration of a job scheduler to improve project management.
Q & A
What is the main focus of the YouTube channel mentioned in the transcript?
-The channel focuses on technology videos related to big data, specifically topics like Apache Spark and the Auto Picker system.
What new series is the creator planning to start?
-The creator is planning to start a new series called 'n2n project explanation' or 'end-to-end project development' using big data technologies.
Which technologies are utilized in the described project?
-The project utilizes components from Apache Spark, Apache Hadoop, and visualization packages from Python libraries.
What is Kafka and what role does it play in the project?
-Kafka is a distributed messaging system that serves as a messaging layer where data from various sources is pushed for consumption by applications.
How does the project process data after it is consumed from Kafka?
-After consuming data from Kafka, the project processes the data using Apache Spark and writes the results to HDFS (Hadoop Distributed File System).
What is the purpose of HDFS in this project?
-HDFS is used to store the processed data, which can then be accessed and queried using other components like Presto.
What visualization tool is mentioned in the transcript?
-The transcript mentions using a Python package called Plotly for data visualization.
What is the function of Presto in the project architecture?
-Presto is a distributed query engine that provides fast querying capabilities on the data stored in HDFS, enabling efficient data access.
What additional layer did the creator add to the architecture?
-The creator added a service class that implements a REST API to read data from HDFS tables using Presto, allowing for quick data retrieval.
What can viewers expect in future videos of the series?
-Viewers can expect demonstrations of the application and detailed explanations of each component of the project in future videos.
Outlines

此内容仅限付费用户访问。 请升级后访问。
立即升级Mindmap

此内容仅限付费用户访问。 请升级后访问。
立即升级Keywords

此内容仅限付费用户访问。 请升级后访问。
立即升级Highlights

此内容仅限付费用户访问。 请升级后访问。
立即升级Transcripts

此内容仅限付费用户访问。 请升级后访问。
立即升级浏览更多相关视频

noc19-cs33-Introduction-Big Data Computing

What is Apache Hadoop?

1. Intro to Big Data
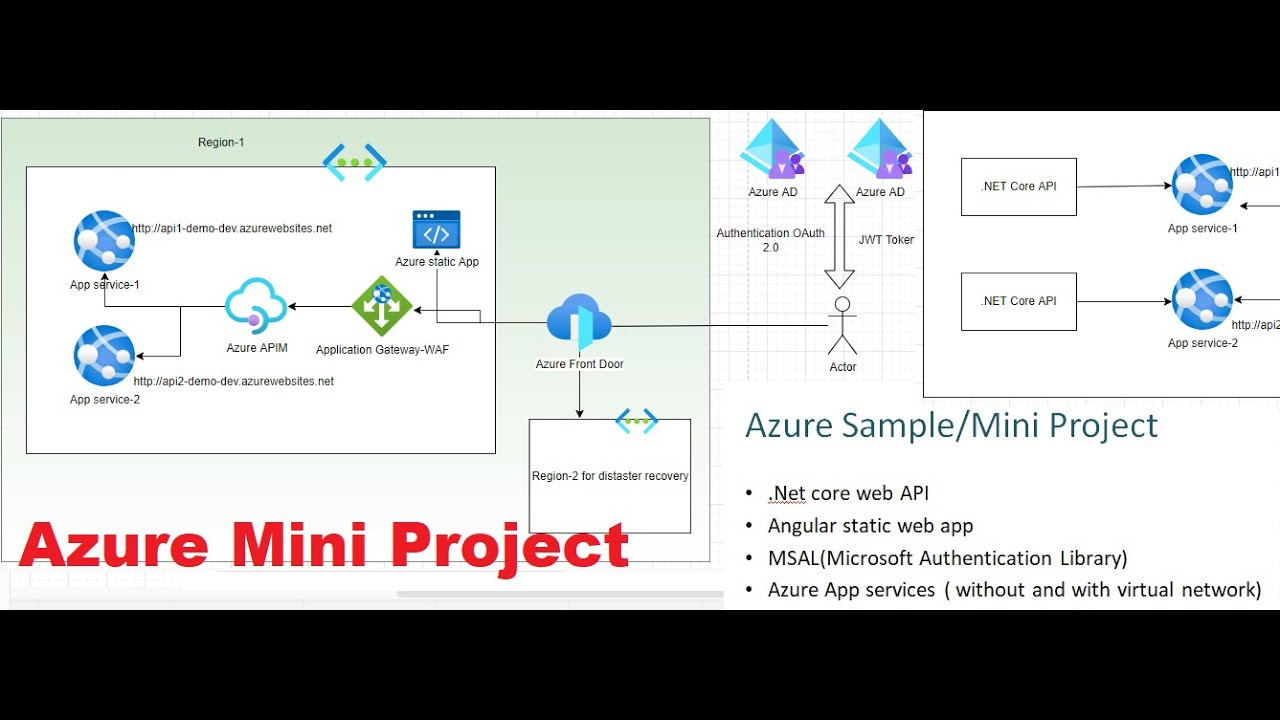
Azure Mini / Sample Project | Development of Azure Project with hands-on experience. Learn in lab.

Hadoop Ecosystem Explained | Hadoop Ecosystem Architecture And Components | Hadoop | Simplilearn
AZ-900 Episode 15 | Azure Big Data & Analytics Services | Synapse, HDInsight, Databricks
5.0 / 5 (0 votes)
