IF3140 Query Processing - Bagian 1. Pengantar
Summary
TLDRThis lecture, presented by Fazar Azizah, covers query processing in database management. It explains how DBMS translates user queries into an internal form for efficient processing, using relational algebra. Key steps include parsing, optimizing with query execution plans, and evaluating queries with minimal cost. The focus is on optimizing queries by reducing disk access and computational effort. The lecture also discusses the importance of buffer availability in memory for efficient query processing and how to measure query costs in terms of block transfers and seek operations.
Takeaways
- 📊 Query processing involves a series of activities to extract data from a database based on a user's query.
- 🔄 The first step in query processing is parsing and translating the query into an internal form that can be efficiently processed by the DBMS.
- 🧮 The internal form of the query is typically close to relational algebra, which allows it to be optimized and executed.
- ⚙️ Query optimization aims to select the most efficient execution plan by evaluating multiple equivalent relational algebra expressions.
- 📉 The goal of query optimization is to minimize the query cost, which is largely influenced by disk access times.
- 📂 Disk access cost is the dominant factor in overall query processing time, and optimizing it is critical for performance.
- 🔍 Cost measurement includes factors like the number of disk block transfers and seeks, with writing generally being more expensive than reading.
- 💾 The availability of memory buffers can significantly affect query efficiency by reducing the number of disk transfers needed.
- 🔄 Different execution plans may be chosen depending on whether indexes are used, impacting the overall query cost.
- 📈 In practice, measuring query cost considers disk access time and processing time, but focusing on disk access provides a simpler and more dominant estimation.
Q & A
What is query processing in database management?
-Query processing is a series of activities to extract data from a database based on a query given by the user. It involves translating the query into an internal form that can be efficiently processed by the DBMS, leading to the evaluation and generation of the expected output.
What is the first step in query processing?
-The first step in query processing is parsing and translating the user query, typically written in a human-readable language like SQL, into an internal form that can be processed by the DBMS. This internal form is often close to relational algebra.
What is the role of the query optimizer?
-The query optimizer generates an execution plan by using statistics related to the data. It selects the most efficient way to execute the query by considering multiple equivalent relational algebra expressions and choosing the one with the lowest cost.
How does query optimization reduce query costs?
-Query optimization reduces query costs by selecting an execution plan that minimizes factors like disk access time, which is considered the dominant cost in query processing. The optimizer evaluates various plans to find the one that incurs the least resource usage.
What is an execution plan in query processing?
-An execution plan is a detailed roadmap created by the query optimizer, outlining how the DBMS will execute the query to retrieve the desired results. It is based on the internal representation of the query and aims to minimize execution costs.
What factors contribute to the cost of a query?
-Several factors contribute to the cost of a query, such as disk access time, CPU processing time, and data transfer time. The most dominant factor is typically disk access time, as it takes the longest to read or write data blocks to and from the disk.
How is the cost of disk access measured?
-The cost of disk access is usually measured in terms of the number of block transfers (disk I/O operations) and the number of disk seeks required. Each block transfer and seek has an associated time cost, which is multiplied by the total number of blocks or seeks to estimate the total cost.
Why is the time required to write data usually higher than reading?
-Writing data to disk generally takes more time than reading because after writing, the system often reads the data again to verify that the write operation was successful. This additional read operation increases the total time and cost.
What is the impact of buffer availability on query cost?
-The availability of buffer space in memory significantly impacts query cost. If sufficient buffer space is available, fewer disk transfers are needed, making the query more efficient. In the worst-case scenario, where buffer space is limited, more disk transfers are required, increasing the query cost.
What is the role of memory buffers in query processing?
-Memory buffers temporarily store data during query processing. If the buffer can hold all the data being processed, fewer disk I/O operations are required, improving efficiency. The more memory available for buffering, the fewer block transfers are needed, reducing query costs.
Outlines

此内容仅限付费用户访问。 请升级后访问。
立即升级Mindmap

此内容仅限付费用户访问。 请升级后访问。
立即升级Keywords

此内容仅限付费用户访问。 请升级后访问。
立即升级Highlights

此内容仅限付费用户访问。 请升级后访问。
立即升级Transcripts

此内容仅限付费用户访问。 请升级后访问。
立即升级浏览更多相关视频

How do Databases work? Understand the internal architecture in simplest way possible!
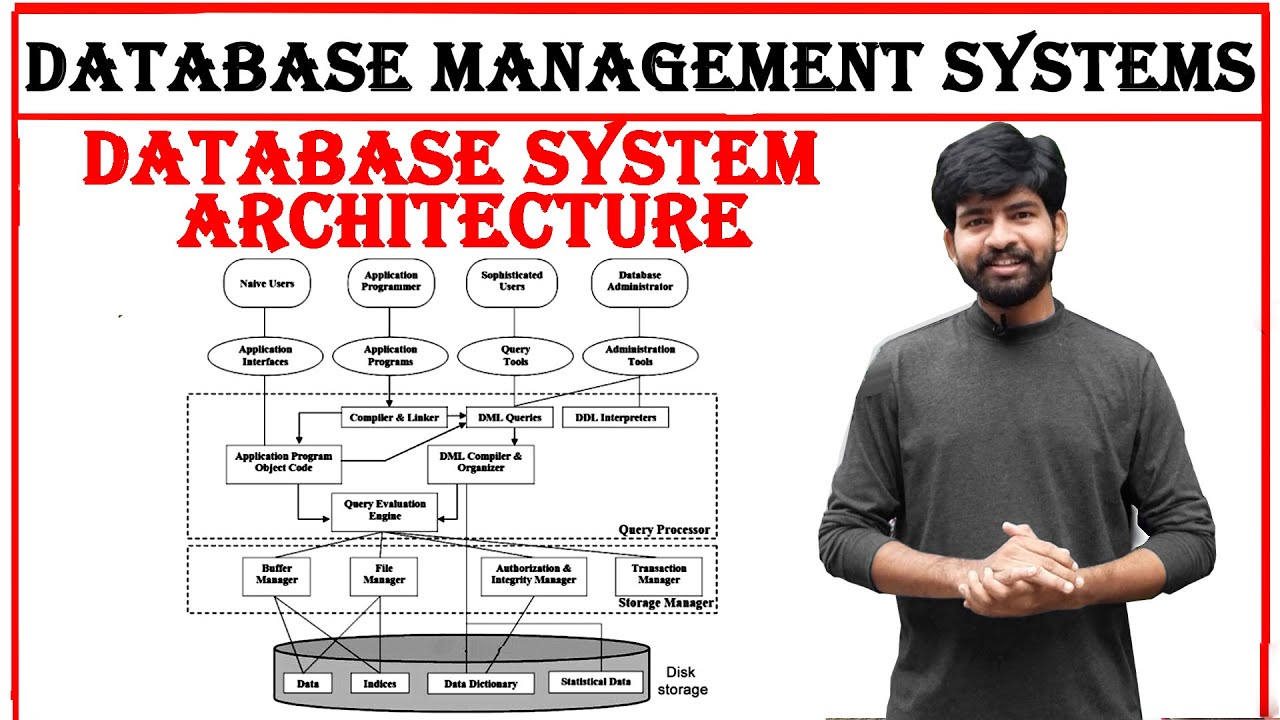
database system architecture in dbms | database management system | Architecture | DBMS | btech

Pemrograman Basis Data : Introduction

Introduction to SQL/1

Pertemuan 4 - Pemrograman Basis Data : Query Lanjutan (Aggregates)

Sistem Manajemen Database Ke 2
5.0 / 5 (0 votes)
