Activation Functions In Neural Networks Explained | Deep Learning Tutorial
Summary
TLDRThis video from the 'Deep Learning Explained' series by Assembly AI explores the importance and types of activation functions in neural networks. It explains how activation functions introduce non-linearity, enabling networks to handle complex problems. The video covers various functions like step, sigmoid, hyperbolic tangent, ReLU, leaky ReLU, and softmax, discussing their applications and advantages. It also demonstrates how to implement these functions in TensorFlow and PyTorch, simplifying the process for viewers.
Takeaways
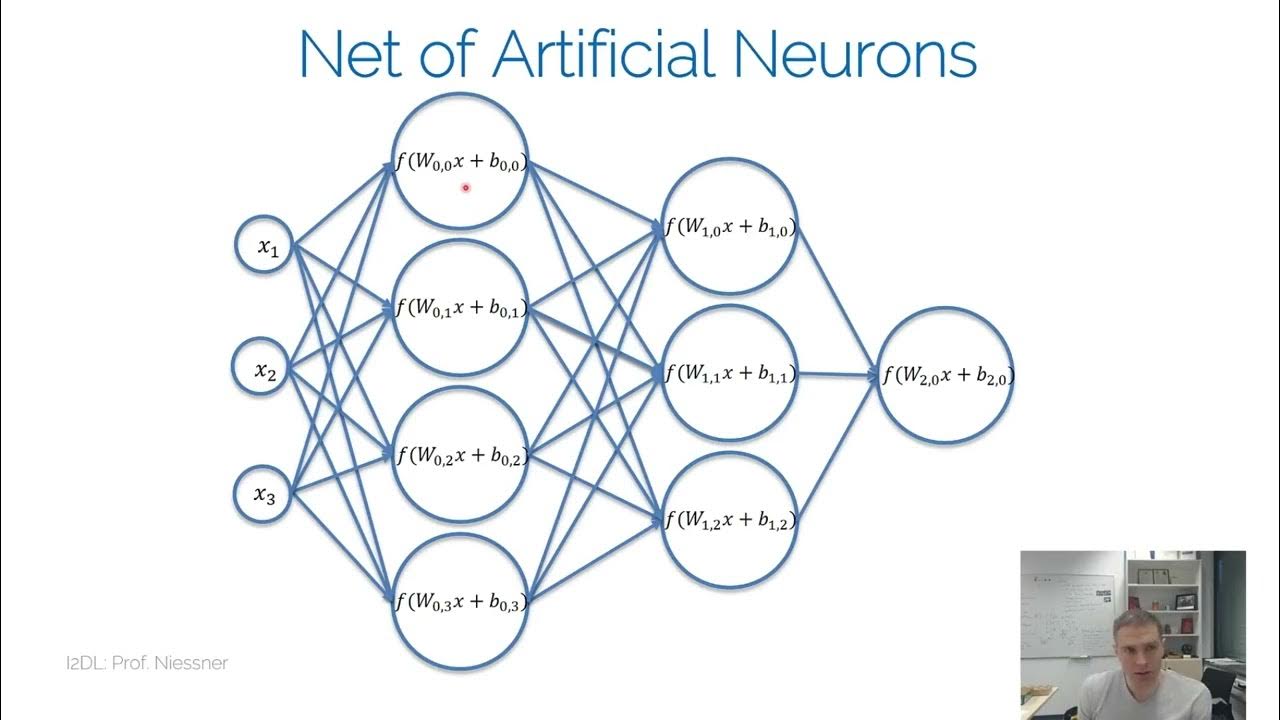
- 🧠 Activation functions introduce non-linearity into neural networks, allowing them to learn complex patterns.
- 🔄 Without activation functions, neural networks would only perform linear transformations, limiting their ability to model complex data.
- 📶 The step function is a basic activation function that outputs 1 if the input is above a threshold, otherwise 0, but is too simplistic for practical use.
- 📉 The sigmoid function outputs a probability between 0 and 1, useful for binary classification, but has limitations in deeper networks.
- 🔽 The hyperbolic tangent function, or tanh, outputs values between -1 and 1, making it a common choice for hidden layers.
- 🚀 The ReLU (Rectified Linear Unit) function is widely used in hidden layers due to its simplicity and effectiveness in avoiding the vanishing gradient problem.
- 💧 The leaky ReLU is a variation of ReLU that allows a small, non-zero output for negative inputs, helping to mitigate the dying ReLU problem.
- 🔮 The softmax function is used in the output layer of multi-class classification problems to output probabilities for each class.
- 🛠️ Deep learning frameworks like TensorFlow and PyTorch provide easy-to-use implementations of activation functions, either as layers or functions.
- 🔗 Assembly AI offers a state-of-the-art speech-to-text API, and the video provides a link to obtain a free API token for use.
Q & A
What is the primary purpose of activation functions in neural networks?
-The primary purpose of activation functions in neural networks is to introduce non-linearity, which allows the network to learn complex patterns and make decisions on whether a neuron should be activated or not.
Why are activation functions necessary for neural networks?
-Without activation functions, a neural network would only perform linear transformations, which would limit it to solving linearly separable problems. Activation functions enable the network to model non-linear relationships, which are crucial for complex tasks.
What is the step function in the context of activation functions?
-The step function is a simple activation function that outputs 1 if the input is greater than a threshold and 0 otherwise, demonstrating the concept of whether a neuron should be activated based on the input.
What does the sigmoid function do and where is it commonly used?
-The sigmoid function outputs a probability between 0 and 1 based on the input value. It is commonly used in hidden layers and particularly in the last layer for binary classification problems.
How does the hyperbolic tangent function differ from the sigmoid function?
-The hyperbolic tangent function is similar to the sigmoid but outputs values between -1 and 1, making it a scaled and shifted version of the sigmoid function, and it is commonly used in hidden layers.
What is the ReLU (Rectified Linear Unit) function and why is it popular?
-The ReLU function outputs the input value if it is positive and 0 if it is negative. It is popular because it can improve the learning speed and performance of neural networks, and it is often the default choice for hidden layers.
What is the dying ReLU problem and how can it be addressed?
-The dying ReLU problem refers to a situation where a neuron only outputs 0 for any input after many training iterations, halting further weight updates. This can be addressed by using the leaky ReLU, which allows a small, non-zero output for negative inputs to prevent the neuron from becoming completely inactive.
What is the softmax function and where is it typically used?
-The softmax function is used to squash the input values to probabilities between 0 and 1, with the highest input value corresponding to the highest probability. It is typically used in the last layer of a neural network for multi-class classification problems.
How can activation functions be implemented in TensorFlow and PyTorch?
-In TensorFlow, activation functions can be specified as an argument in the layer definition or used as layers from `tensorflow.keras.layers`. In PyTorch, they can be used as layers from `torch.nn` or as functions from `torch.nn.functional` in the forward pass of a neural network.
What is the role of Assembly AI in the context of this video?
-Assembly AI is a company that creates state-of-the-art speech-to-text APIs. The video is part of the 'Deep Learning Explained' series by Assembly AI, and they offer a free API token for users to try their services.
Outlines

此内容仅限付费用户访问。 请升级后访问。
立即升级Mindmap

此内容仅限付费用户访问。 请升级后访问。
立即升级Keywords

此内容仅限付费用户访问。 请升级后访问。
立即升级Highlights

此内容仅限付费用户访问。 请升级后访问。
立即升级Transcripts

此内容仅限付费用户访问。 请升级后访问。
立即升级




5.0 / 5 (0 votes)
