W6L1_Union Find Data Structure
Summary
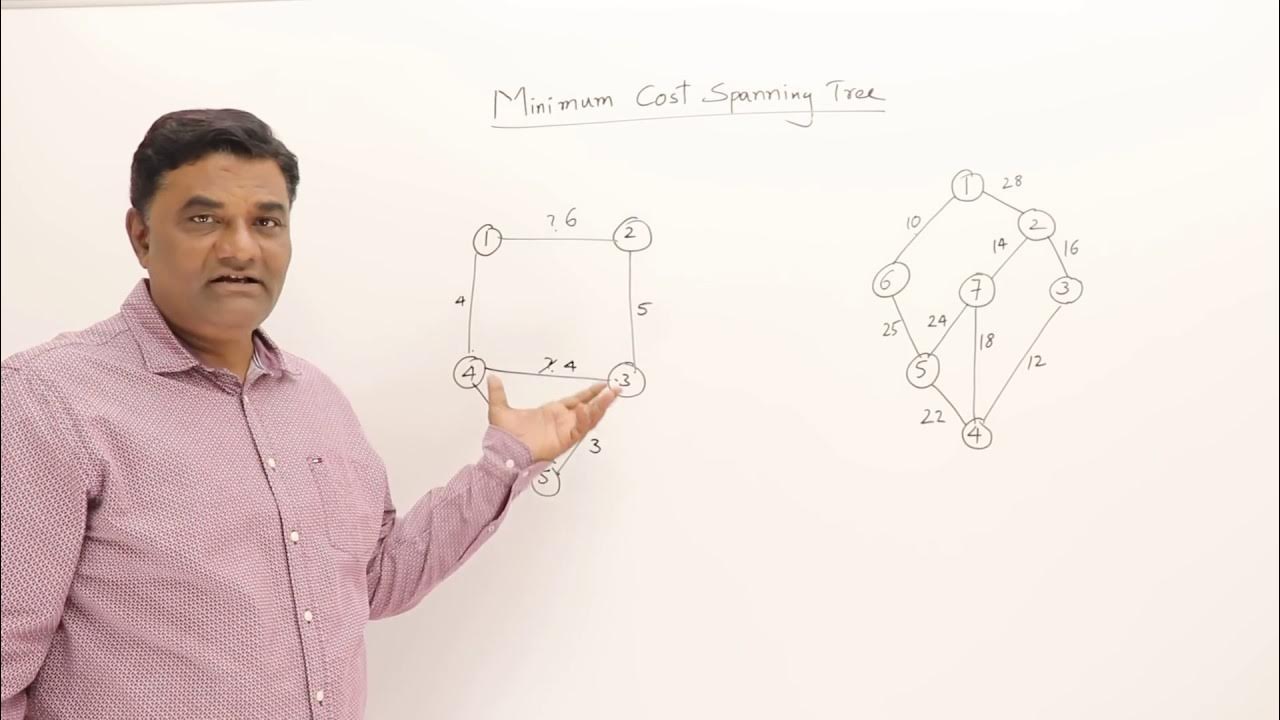
TLDRThe video script delves into the intricacies of Kruskal's algorithm for finding minimum cost spanning trees, emphasizing the role of the Union-Find data structure. It explains the initial naive implementation of Union-Find, where union operations are costly. The script then introduces an optimized approach using two dictionaries to track components and their sizes, allowing unions to be performed more efficiently. The concept of merging smaller components into larger ones to reduce the complexity of union operations is highlighted. The summary also touches on the amortized analysis that proves the improved union operation's efficiency, ultimately enhancing Kruskal's algorithm's performance to near-linear time complexity.
Takeaways
- 🌳 The script discusses two algorithms for finding minimum cost spanning trees: Prim's and Kruskal's algorithms.
- 🔍 Prim's algorithm extends a tree by finding the shortest edge connected to the current tree, similar to Dijkstra's algorithm.
- 🌉 Kruskal's algorithm builds a tree by starting with disconnected nodes and adding the shortest edge possible without forming a cycle.
- 🔢 Kruskal's algorithm involves sorting all edges in ascending order and then processing them to build the minimum cost spanning tree.
- 🔄 A key challenge in Kruskal's algorithm is efficiently tracking the components (sets of connected vertices) as edges are added.
- 🔑 The 'find' operation identifies the component a vertex belongs to, while the 'union' operation merges two components into one.
- 📈 Initially, union operations can be inefficient, taking O(n) time, as they require updating all vertices in the smaller component.
- 📚 The script introduces a data structure to improve union find operations, using dictionaries to track components and their members.
- 🔑 By keeping track of component sizes and merging smaller components into larger ones, the union operation can be optimized.
- 📊 The amortized complexity of the improved union find is O(log m) per operation, leading to significant efficiency gains in Kruskal's algorithm.
- 📈 The overall time complexity of Kruskal's algorithm, with the optimized union find, becomes O(n log n), a substantial improvement from the naive O(n^2).
Q & A
What are the two algorithms mentioned for finding minimum cost spanning trees?
-The two algorithms mentioned for finding minimum cost spanning trees are Prim's algorithm and Kruskal's algorithm.
How does Prim's algorithm extend a tree in the context of minimum cost spanning trees?
-Prim's algorithm extends a tree by finding the shortest edge connected to the current tree.
What is the initial state of nodes in Kruskal's algorithm?
-In Kruskal's algorithm, the initial state of nodes is disconnected.
How does Kruskal's algorithm build a minimum cost spanning tree?
-Kruskal's algorithm builds a minimum cost spanning tree by starting with disconnected nodes and connecting them by adding the shortest edge possible, processed in ascending order.
What is the main difficulty in implementing Kruskal's algorithm efficiently?
-The main difficulty in implementing Kruskal's algorithm efficiently is keeping track of the components and determining which nodes belong to the same component or different components as edges are added.
What is the purpose of the 'find' operation in the context of Kruskal's algorithm?
-The 'find' operation is used to determine which partition a given vertex belongs to, which is crucial for checking if adding an edge would form a cycle.
What does the 'union' operation in Kruskal's algorithm achieve?
-The 'union' operation in Kruskal's algorithm merges two components into a single partition when an edge connecting them is added to the spanning tree.
Why is the 'union' operation considered time-consuming in the initial implementation of Kruskal's algorithm?
-The 'union' operation is considered time-consuming because it requires finding all other vertices in the same component as a given vertex and updating their partition, which involves a linear scan proportional to the size of the set.
How can the efficiency of the 'union' operation be improved in Kruskal's algorithm?
-The efficiency of the 'union' operation can be improved by keeping track of the size of each component and always merging the smaller component into the larger one, which reduces the number of elements that need to be relabeled in each operation.
What is the amortized complexity of the 'union' operation in the optimized version of Kruskal's algorithm?
-The amortized complexity of the 'union' operation in the optimized version of Kruskal's algorithm is O(log m), where m is the number of union operations.
How does the optimized union-find data structure contribute to the overall efficiency of Kruskal's algorithm?
-The optimized union-find data structure contributes to the overall efficiency of Kruskal's algorithm by reducing the time complexity of the 'union' operation, which in turn brings the overall time complexity of the algorithm down from O(n^2) to O(n log n).
Outlines

此内容仅限付费用户访问。 请升级后访问。
立即升级Mindmap

此内容仅限付费用户访问。 请升级后访问。
立即升级Keywords

此内容仅限付费用户访问。 请升级后访问。
立即升级Highlights

此内容仅限付费用户访问。 请升级后访问。
立即升级Transcripts

此内容仅限付费用户访问。 请升级后访问。
立即升级浏览更多相关视频
3.5 Prims and Kruskals Algorithms - Greedy Method

Dijkstra's algorithm in 3 minutes

Tutorial Algoritma Kruskal | Minimum Spanning Tree

Prim's Algorithm - Implementation in Python

Algorithm Design | Approximation Algorithm | Traveling Salesman Problem with Triangle Inequality
Projeto e Análise de Algoritmos - Aula 09 - Limite inferior para o problema de ordenação
5.0 / 5 (0 votes)
