What is RAG? (Retrieval Augmented Generation)
Summary
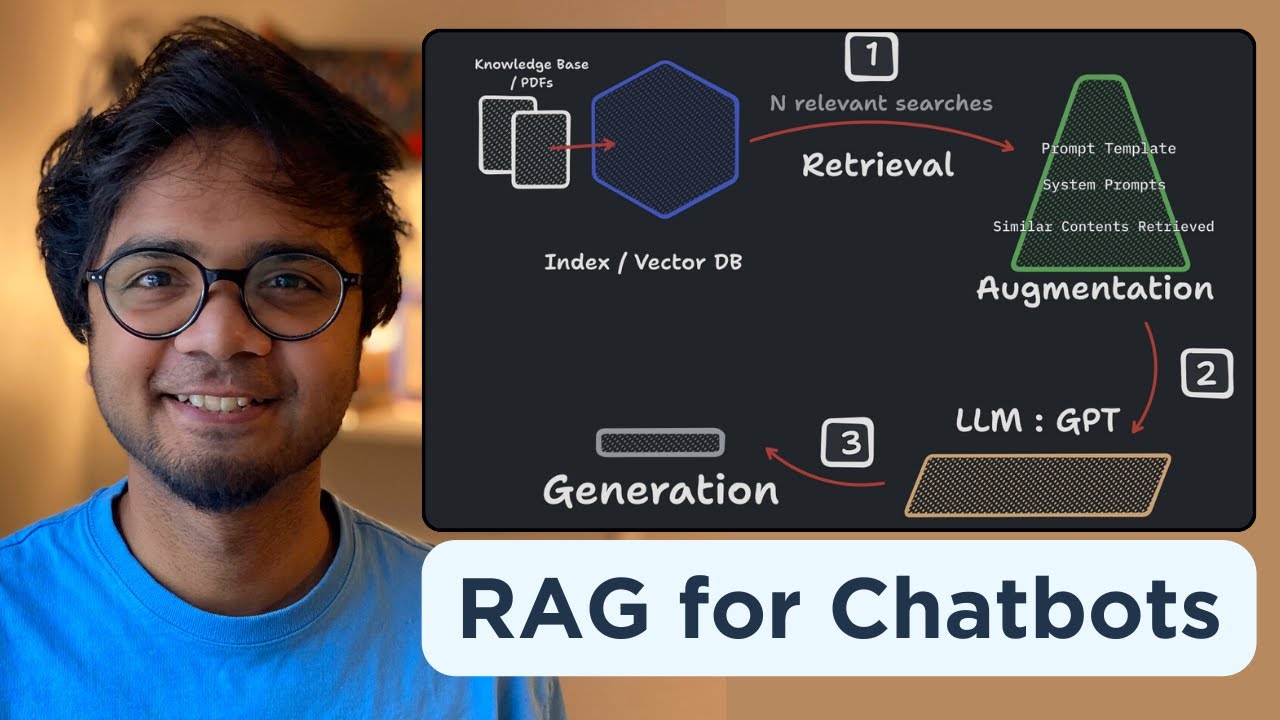
TLDRThe video explains retrieval augmented generation (RAG), a popular AI architecture that allows large language models to answer questions using an organization's proprietary content. It works by breaking down an organization's content into chunks, vectorizing those chunks to enable finding the most relevant passages, and packaging those passages with the user's question into a prompt that is fed to the language model to generate an answer. RAG leverages the power of language models while tailoring their responses to an organization's unique content. The video aims to clarify this increasingly common AI pattern that creates chatbot-like experiences for employees and customers.
Takeaways
- 😀 RAG stands for Retrieval Augmented Generation and is a popular AI solution pattern
- 📚 RAG leverages large language models to create chatbot-like experiences using your own content
- 🤔 RAG works by retrieving the most relevant content from your documents/website to augment the language model's generation
- 🔎 Your content is broken into chunks which are vectorized - this allows finding content relevant to the user's question
- ⚙️ The relevant content chunks are added to the prompt sent to the language model to provide context for answering the question
- 🔢 Vector similarities between the user question and content chunks allow retrieving the most relevant information
- 🗣 A prompt with instructions, relevant content chunks, and the user question is sent to the language model to generate an answer
- 💡 RAG provides a better experience than just listing relevant documents - it creates a new tailored answer
- ✨ Most large language model projects leverage some form of RAG architecture to work with custom content
- 📝 Prompt engineering is important for providing good instructions and content to the language model
Q & A
What is the key benefit of using a rag architecture?
-A rag architecture allows you to leverage the power of large language models to answer questions and generate content, but using your own proprietary content rather than just what's available on the public internet.
What are some common use cases for a rag system?
-Common use cases include customer chatbots, internal company FAQs, documentation search, and automated ticket resolution by searching past tickets and solutions.
How does the system know which content is relevant to the user's question?
-The system vectorizes all the content, giving each chunk a vector of numbers representing its essence. The user's question is also vectorized. Then the vectors are compared to find the chunks most similar to the question vector.
What is a prompt in this context and why is it important?
-A prompt provides instructions and context to the language model. Careful prompt engineering, especially the content before the actual question, helps the model generate better, more tailored responses.
What types of content can I use in a rag system?
-You can use any text content - website pages, PDF documents, internal databases, past tickets or cases, etc. The system will index and vectorize the content for easy retrieval.
Does the rag system replace search engines and knowledge bases?
-No, rag systems complement search and knowledge bases by taking content, aggregating it, and generating tailored responses. So they enhance rather than replace existing systems.
What are vectors in this context and how are they created?
-Vectors are numeric representations of chunks of text, encoding their semantic meaning. They are generated by passing content through a language model encoder which outputs the vector.
What components make up a rag system?
-The main components are the content indexer, vector database, retriever, language model (encoder and decoder), and prompt generator.
Is a separate language model required for encoding versus decoding?
-No, the same language model can be used for both encoding content to vectors and decoding prompts to generate responses. But separate models can be used as well.
How much content is needed to create an effective rag system?
-There's no fixed amount - start with whatever content you have. The more high-quality, relevant content you can provide, the better the generated responses will be.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowBrowse More Related Video

Retrieval Augmented Generation - Neural NebulAI Episode 9
Build your own RAG (retrieval augmented generation) AI Chatbot using Python | Simple walkthrough

Fine Tuning, RAG e Prompt Engineering: Qual é melhor? e Quando Usar?

Why Everyone is Freaking Out About RAG

Introduction to Generative AI (Day 7/20) #largelanguagemodels #genai

Turn ANY Website into LLM Knowledge in SECONDS
5.0 / 5 (0 votes)