Why Neural Networks can learn (almost) anything
Summary
TLDRThis script introduces the concept of neural networks as universal function approximators. It begins by explaining functions as a system of inputs and outputs, then explores how neural networks can be trained to reverse-engineer and approximate functions from data. The video demonstrates the mechanics of a neural network, showing how simple building blocks like neurons can be combined to construct complex functions. It emphasizes the importance of non-linearities in allowing neural networks to learn and highlights their ability to approximate any function given enough data and neurons. The script discusses the potential of neural networks to learn and emulate intelligent behavior, while acknowledging practical limitations and the necessity of sufficient training data. It concludes by emphasizing the transformative impact of neural networks in fields like computer vision and natural language processing.
Takeaways
- 🤖 Neural networks are a form of function approximators that can learn to represent complex patterns and relationships in data.
- 🧩 Neural networks are composed of interconnected neurons, which are simple linear functions that can be combined to create more complex non-linear functions.
- 🚀 Neural networks can be trained using algorithms like backpropagation to automatically adjust their parameters and improve their approximation of a target function.
- 🌀 Neural networks can learn to approximate any function to any desired degree of precision, making them universal function approximators.
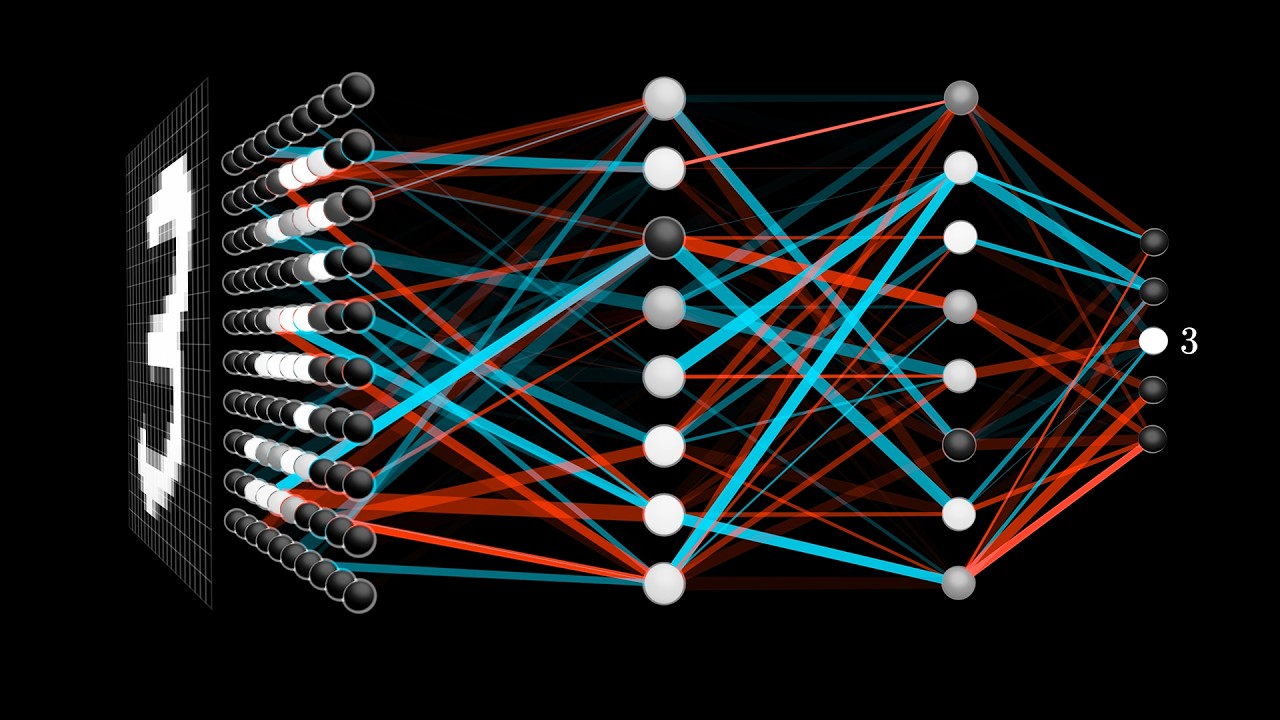
- 🖼️ Neural networks can learn to approximate functions that represent various tasks, such as image classification, language translation, and more, by encoding inputs and outputs as numerical data.
- 💻 Neural networks are theoretically Turing-complete, meaning they can solve any computable problem, given enough data and resources.
- 🔮 The success of neural networks in approximating functions depends on the availability of sufficient data that accurately represents the underlying function.
- 🚧 Neural networks have practical limitations, such as finite resources and challenges in the learning process, that constrain their ability to approximate certain functions.
- 🤯 Neural networks have revolutionized fields like computer vision and natural language processing by providing a way to solve problems that require intuition and fuzzy logic, which are difficult to manually program.
- 🚀 The humble function is a powerful concept that allows neural networks to construct complex representations and approximate a wide range of intelligent behaviors.
Q & A
What is a neural network learning in this video?
-The neural network is learning the shape of the infinitely complex fractal known as the Mandelbrot set.
What is the fundamental mathematical concept that needs to be understood in order to grasp how a neural network can learn?
-The fundamental mathematical concept that needs to be understood is the concept of a function, which is informally defined as a system of inputs and outputs.
How can a function be approximated if the actual function itself is unknown?
-A function approximator can be used to construct a function that captures the overall pattern of the data, even if there is some noise or randomness present.
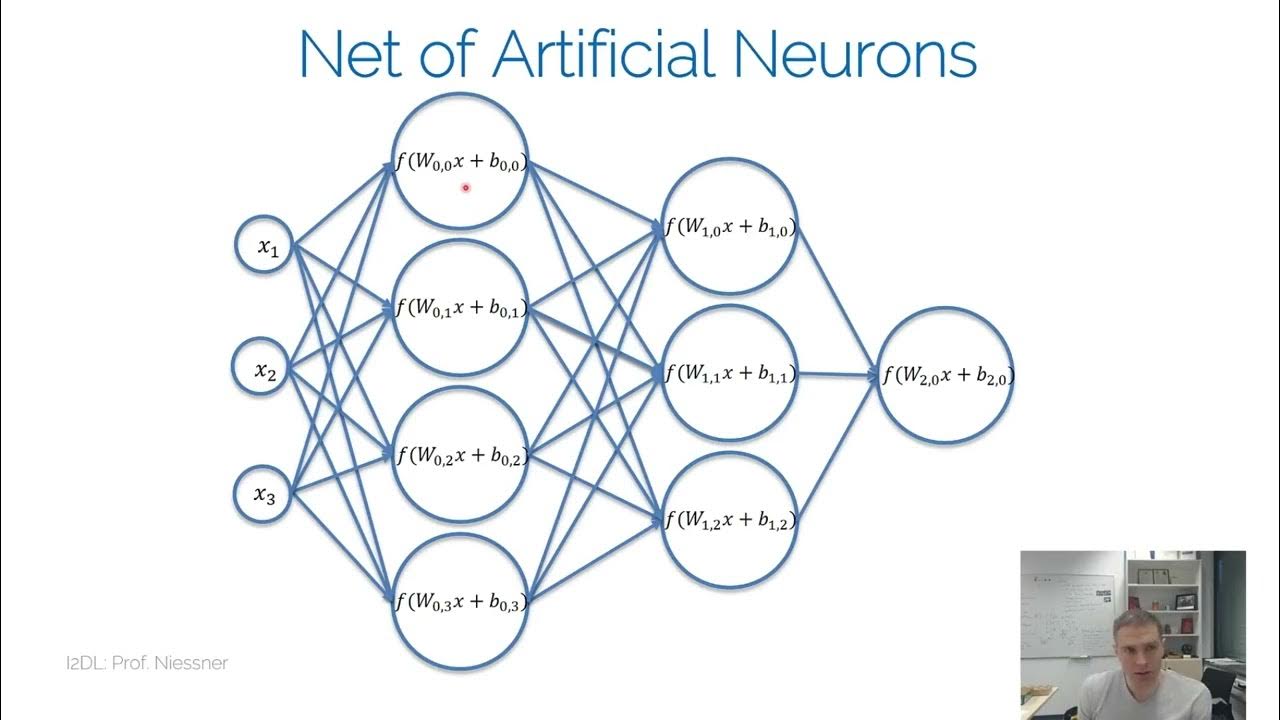
What is a neural network in the context of function approximation?
-A neural network is a function approximator that can learn to approximate any function by combining simple computations.
What is the basic building block of a neural network?
-The basic building block of a neural network is a neuron, which is a simple linear function that takes in inputs, multiplies them by weights, adds a bias, and produces an output.
Why is a non-linearity needed in a neural network?
-A non-linearity, such as the rectified linear unit (ReLU), is needed to prevent the neural network from simplifying down to a single linear function, which would limit its ability to learn more complex patterns.
What algorithm is commonly used to automatically tune the parameters of a neural network?
-The most common algorithm for automatically tuning the parameters of a neural network is called backpropagation.
Can neural networks learn any function?
-Neural networks have been rigorously proven to be universal function approximators, meaning they can approximate any function to any degree of precision, as long as there is enough data to describe the function.
What are some practical limitations of neural networks?
-Practical limitations of neural networks include finite network size, constraints introduced by the learning process, and the requirement for sufficient data to accurately approximate the target function.
What are some areas where neural networks have been particularly successful?
-Neural networks have been indispensable in fields like computer vision, natural language processing, and other areas of machine learning, where they have been able to learn intuitions and fuzzy logic that are difficult for humans to manually program.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowBrowse More Related Video



5.0 / 5 (0 votes)