Chat With Documents Using ChainLit, LangChain, Ollama & Mistral 🧠
Summary
TLDRThis video tutorial, part of an AMA series, guides viewers on creating a simple Retrieval-Augmented Generation (RAG) application using open-source models. The host demonstrates how to embed PDF documents into a knowledge base with the help of Langchain and AMA, and then interact with them through a user-friendly chat interface. The video covers setting up the environment, installing necessary packages, and deploying the application, which allows users to ask questions and receive answers based on the embedded documents. It also emphasizes the importance of tweaking parameters for optimal results and suggests referring to official repositories for updates and troubleshooting.
Takeaways
- 😀 The video is part of an AMA series, focused on creating a simple Retrieval-Augmented Generation (RAG) application using open-source models.
- 📚 The presenter has previously created videos on using AMA for chat UI and integrating it with Langchain.
- 🔗 The video introduces using Langchain for deploying applications and utilizing Langsmith for application tracing.
- 📝 The GitHub repository mentioned in the video contains the code for the RAG application and instructions for setting it up.
- 💻 Viewers are guided to clone the repository, set up a virtual environment, and install necessary packages using a `requirements.txt` file.
- 🔍 The video covers two examples: ingesting documents from a data folder and creating a chain lead application for uploading PDFs directly through a UI.
- 📈 It demonstrates how to use the `ama` embeddings for creating a vector database with the help of the `mistol` model from the Langchain Hub.
- 🔧 The video provides troubleshooting tips for issues with code or functions, suggesting checking the official GitHub repository for updates or creating an issue.
- 🗣️ The presenter shows how to interact with the chat UI, asking questions related to the PDF content and receiving answers based on the embedded knowledge base.
- 🛠️ The video emphasizes the flexibility of using different models with AMA and the importance of precise prompts for better question-answering results.
- 🔄 The process includes creating a vector database, using a RAG prompt, and deploying a chat application that can answer questions based on uploaded PDFs.
Q & A
What is the purpose of the video?
-The video aims to guide viewers on how to create a simple Retrieval-Augmented Generation (RAG) application using open-source models and tools like AMA, Lang chain, and Chain lead.
What is AMA in the context of this video?
-AMA refers to a simple chat UI interface that uses models to interact with users, similar to Chat GPT, and is utilized to create the RAG application.
What is Lang chain used for in this tutorial?
-Lang chain is used for deploying the RAG application and also for managing the traces of the application.
What is the significance of using the 'rag prompt mistol' in the video?
-The 'rag prompt mistol' is a pre-existing template available in the Lang chain Hub that simplifies the process of creating the RAG application by providing a structured format for prompts.
How many different ways are shown in the video to create a RAG application?
-Two different methods are demonstrated: one where documents are ingested from a data folder and another where PDFs are uploaded through a UI for conversation.
What is the role of the 'create Vector database' function in the script?
-The 'create Vector database' function initializes the loaders for different file formats, in this case, PDFs, and is responsible for embedding the documents into a vector database for retrieval purposes.
What is the importance of splitting documents into chunks in the script?
-Splitting documents into chunks is necessary for the Recursive Character Splitter to process the text effectively, allowing the model to handle large documents and maintain context with an overlap.
Why is it recommended to use a virtual environment in the video?
-A virtual environment is recommended to isolate the project's packages from existing ones on the system, preventing conflicts and ensuring the correct versions of dependencies are used.
What is the process of running the RAG application as described in the video?
-The process involves installing necessary packages, creating a vector database with embedded documents, using the 'main.py' file to set up the chat interface, and finally running the application using Chain lead with the 'run main.py' command.
How can viewers get help if they encounter issues with the code in the video?
-Viewers are advised to go to the official GitHub repository of Lang chain or Chain lead and create an issue, where they can seek assistance from the community or the creators of the tools.
What is the purpose of the 'on_message' function in the 'main.py' file?
-The 'on_message' function handles user input in the chat interface, processes it through the RAG application, and retrieves information from the knowledge base to provide answers.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowBrowse More Related Video

Step-by-Step Guide to Building a RAG LLM App with LLamA2 and LLaMAindex

Easy 100% Local RAG Tutorial (Ollama) + Full Code
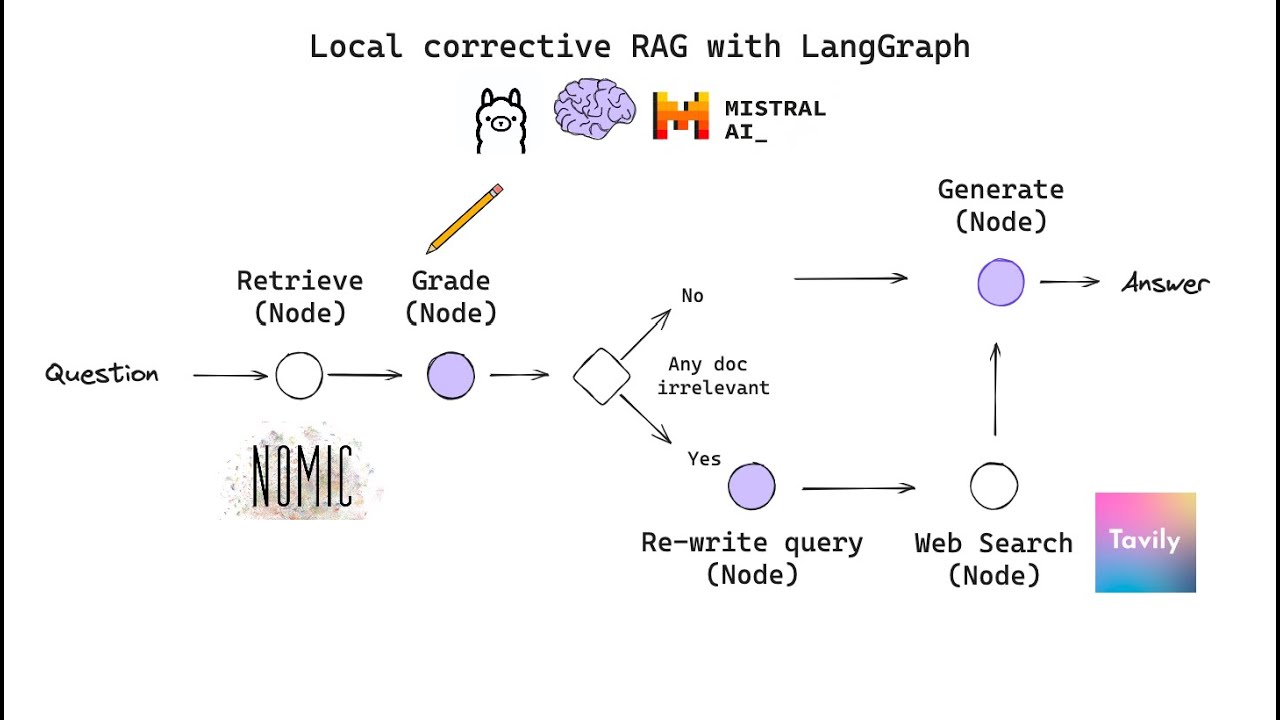
Building Corrective RAG from scratch with open-source, local LLMs

Llama-index for beginners tutorial

Unstructured” Open-Source ETL for LLMs

RAG + Langchain Python Project: Easy AI/Chat For Your Docs
5.0 / 5 (0 votes)