How to choose an embedding model
Summary
TLDRVector embeddings are at the core of modern machine learning applications, enabling the encoding of text, images, audio, and video into high-dimensional vector spaces to assess similarities. Key considerations for selecting embedding models include specialization for specific industries, model size, performance, and whether to use closed or open-source models. The video highlights tools like Weeva and Hugging Face’s leaderboard, which help developers manage issues like rate limits and model comparisons. Ultimately, choosing the right model involves balancing performance, scalability, and ease of implementation to meet specific use cases.
Takeaways
- 😀 Embeddings are crucial for modern machine learning applications, enabling effective representation of unstructured data like text, images, and audio in high-dimensional vector spaces.
- 😀 The breakthrough for vector embeddings came in 2013 with the release of the Word2Vec paper, which shifted focus from exact matches to meaning-based encoding.
- 😀 Vector embeddings allow comparisons between data points by measuring the distance (similarity) between vectors, using methods like cosine similarity.
- 😀 Embedding models can be fine-tuned for specific industries (e.g., legal, medical, fashion) to improve performance with domain-specific terminology.
- 😀 Models can be either general-purpose (e.g., Snowflake, Arctic Embed) or specialized, and choosing the right model depends on the use case and domain.
- 😀 It is often beneficial to fine-tune a general-purpose model with your own data to enhance its quality for your specific needs.
- 😀 Embedding models can be tailored for various applications, such as classification, retrieval, reranking, or summarization, and performance can vary based on the task.
- 😀 Interacting with embedding models involves considering rate limits and batch processing when using closed-source models, and hosting requirements for open-source models.
- 😀 Model size affects both speed and accuracy: smaller models are faster but may miss nuances, while larger models offer better accuracy at the cost of speed and resource use.
- 😀 Compression techniques and multilingual support are important factors when choosing an embedding model, impacting both performance and implementation complexity.
- 😀 Tools like Weeva's embedding service and Hugging Face’s leaderboard help simplify the decision-making process by offering solutions to common problems such as rate limits and model benchmarking.
Q & A
What are vector embeddings and how are they used in modern machine learning applications?
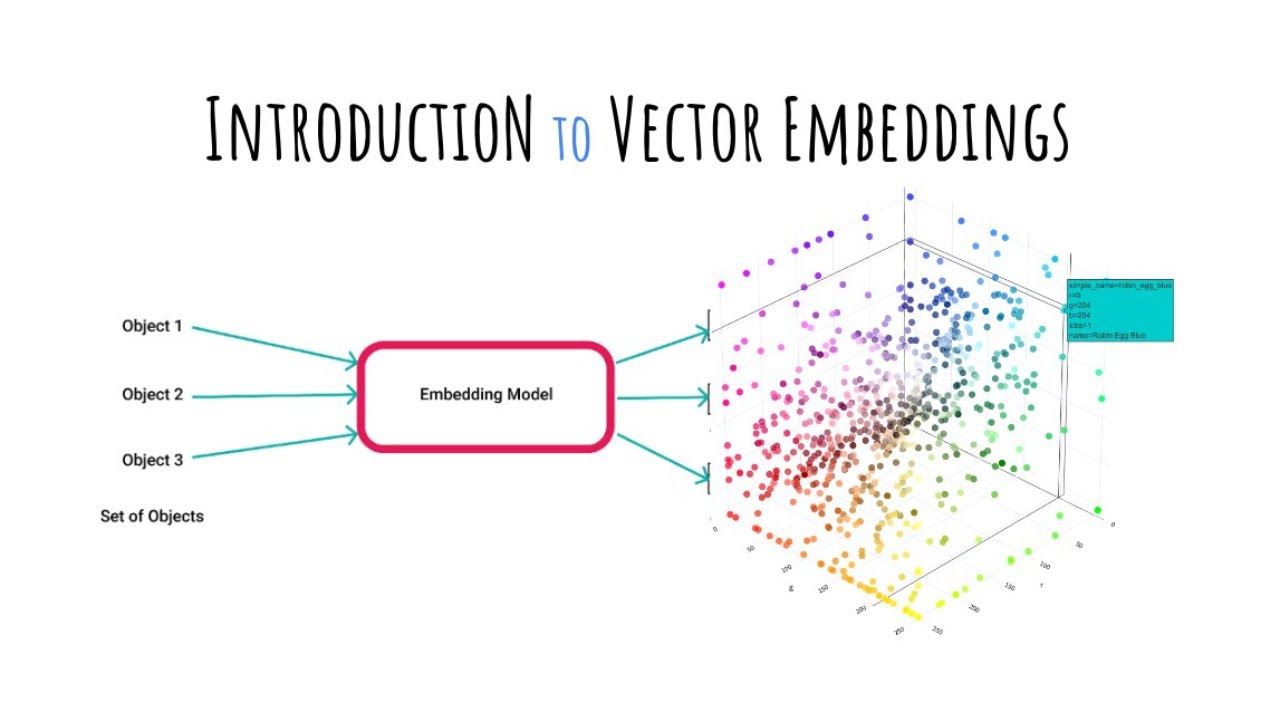
-Vector embeddings are mathematical representations of data, such as text, images, audio, or video, in a high-dimensional vector space. They are used in modern machine learning applications like large language models, vector search, and recommendation systems to encode and compare the meaning of unstructured data based on proximity in vector space.
What was the scientific breakthrough in 2013 related to vector embeddings?
-The breakthrough in 2013 came from the release of a paper on Word2Vec, which demonstrated how encoding text based on its meaning through vector representations, rather than exact matches, could significantly improve understanding in natural language processing tasks.
How do vector embeddings represent the meaning of data?
-Vector embeddings represent the meaning of data by mapping it into a high-dimensional vector space, allowing for the comparison of vectors based on their relative proximity. Similar items are close to each other in the vector space, while dissimilar ones are farther apart.
What is cosine similarity and how is it used in vector search?
-Cosine similarity is a method used to measure the similarity between two vectors by calculating the cosine of the angle between them. In vector search, this metric helps determine how similar two pieces of data are by evaluating their vector representations.
How does the fine-tuning of models affect their performance for different applications?
-Fine-tuning a model on domain-specific data, such as legal, medical, or fashion-related text, can significantly improve its performance in that domain. Models trained on specialized data can better understand specific industry terms or phrases, resulting in more accurate and relevant outputs for specialized applications.
What are the challenges of using closed-source models for generating embeddings?
-The challenges of using closed-source models include concerns over rate limits, batch processing through APIs, potential slowdowns, and the need for external provider services. These issues can affect the efficiency and scalability of embedding generation in applications.
What are the key differences between closed-source and open-source models for embeddings?
-Closed-source models often require developers to rely on external providers, which can lead to issues like rate limits and dependency on the provider. Open-source models, on the other hand, require developers to host the model themselves but offer more flexibility and control over implementation, though they come with their own challenges, such as maintenance and hosting complexities.
How does the size of the model impact performance in vector embedding tasks?
-The size of the model directly affects both speed and accuracy. Smaller models are faster but may not capture all the nuances of the data, which can affect downstream tasks. Larger models, while slower, are more accurate and can better handle complex data representations.
What are some important considerations when selecting an embedding model for a specific application?
-When selecting an embedding model, it's crucial to consider factors such as whether the model is fine-tuned for a specific domain, its ability to handle various data modalities or languages, and its suitability for tasks like retrieval, classification, or summarization. Additionally, considerations such as hosting, latency requirements, and model size should also be taken into account.
What is the role of services like Weeva in improving the use of embedding models?
-Services like Weeva help solve challenges such as rate limits or provider lock-in by allowing embedding models to be hosted closer to the data, streamlining the process for developers and improving the efficiency of embedding generation. This reduces the complexity of managing third-party dependencies and enhances scalability.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowBrowse More Related Video




5.0 / 5 (0 votes)