"okay, but I want GPT to perform 10x for my specific use case" - Here is how
Summary
TLDRThis video explores two methods for customizing large language models: fine-tuning and creating knowledge bases. Fine-tuning enhances model behavior for specific tasks, while knowledge bases leverage existing data for accuracy, especially in fields like legal or medical applications. The presenter demonstrates fine-tuning the Falcon model using a dataset of Midjourney prompts, emphasizing the importance of data quality. The tutorial includes steps for model training, evaluation, and sharing, encouraging viewers to experiment with different use cases like customer support or financial advice, and hints at an upcoming video on creating embedded knowledge bases.
Takeaways
- 😀 Fine-tuning and knowledge bases are two methods to customize large language models for specific use cases, such as medical or legal applications.
- 🤖 Fine-tuning involves retraining a model with private data, while knowledge bases use embeddings to feed relevant information into the model without retraining.
- 📊 Fine-tuning is ideal for shaping model behavior, such as mimicking a specific person's speech style, while knowledge bases excel at providing accurate data retrieval.
- 🗂️ Quality datasets are crucial for effective fine-tuning; using high-quality public datasets or proprietary data can significantly impact the model's performance.
- 💻 Tools like Kaggle and Hugging Face provide access to a wide range of public datasets for various topics.
- 🔄 You can use GPT to generate training data by prompting it to create user inputs that correspond to desired outputs, making the data preparation process easier.
- 🔧 Platforms like Randomness AI can facilitate bulk processing of GPT prompts to quickly generate large datasets for training.
- ⏱️ Fine-tuning the Falcon model can be done on platforms like Google Colab, where users can choose between different model sizes based on their computational resources.
- 📝 Even small datasets (100-200 rows) can yield effective results when fine-tuning, emphasizing the importance of data quality over quantity.
- 🎉 There are numerous potential applications for fine-tuning, including customer support, legal document processing, medical diagnosis, and financial advisories.
Q & A
What are the two primary methods to achieve specific use cases with large language models?
-The two primary methods are fine-tuning, which involves adjusting a pre-existing model with private data, and creating a knowledge base, which uses an embedding or vector database to retrieve relevant information.
When is fine-tuning a large language model particularly useful?
-Fine-tuning is useful when you want the model to exhibit specific behaviors or mimic the speech of certain individuals, such as generating responses similar to a specific public figure.
What are the limitations of fine-tuning in specialized domains like legal and medical fields?
-Fine-tuning may not provide the accurate data required for specialized queries in legal or medical fields; instead, using a knowledge base with embeddings is recommended for better accuracy.
What is the Falcon model, and why is it recommended for fine-tuning?
-The Falcon model is a high-performance large language model that has quickly risen in popularity on model leaderboards. It's available for commercial use and supports multiple languages.
How many rows of data are needed to start fine-tuning a model effectively?
-You can start fine-tuning a model with as few as 100 rows of data, but having a higher-quality dataset generally yields better results.
What platforms can be used to prepare datasets for fine-tuning?
-Public platforms like Kaggle and Hugging Face offer a wide range of datasets. Additionally, private datasets can be generated using tools like GPT to create training data.
What is the significance of data quality in the fine-tuning process?
-The quality of the dataset directly impacts the performance and accuracy of the fine-tuned model; poor-quality data can lead to subpar results.
What are the steps to fine-tune a language model using Google Colab?
-The steps include selecting a model, setting up the training environment, installing libraries, preparing the dataset, training the model, and finally saving or uploading the model.
What type of results can be expected from a fine-tuned model compared to a base model?
-Fine-tuned models generally produce significantly better results, especially in generating contextually relevant prompts and outputs compared to base models.
What other applications can fine-tuning be useful for beyond military prompts?
-Fine-tuning can be useful for applications in customer support, legal document processing, medical diagnosis, and financial advisories, among others.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowBrowse More Related Video
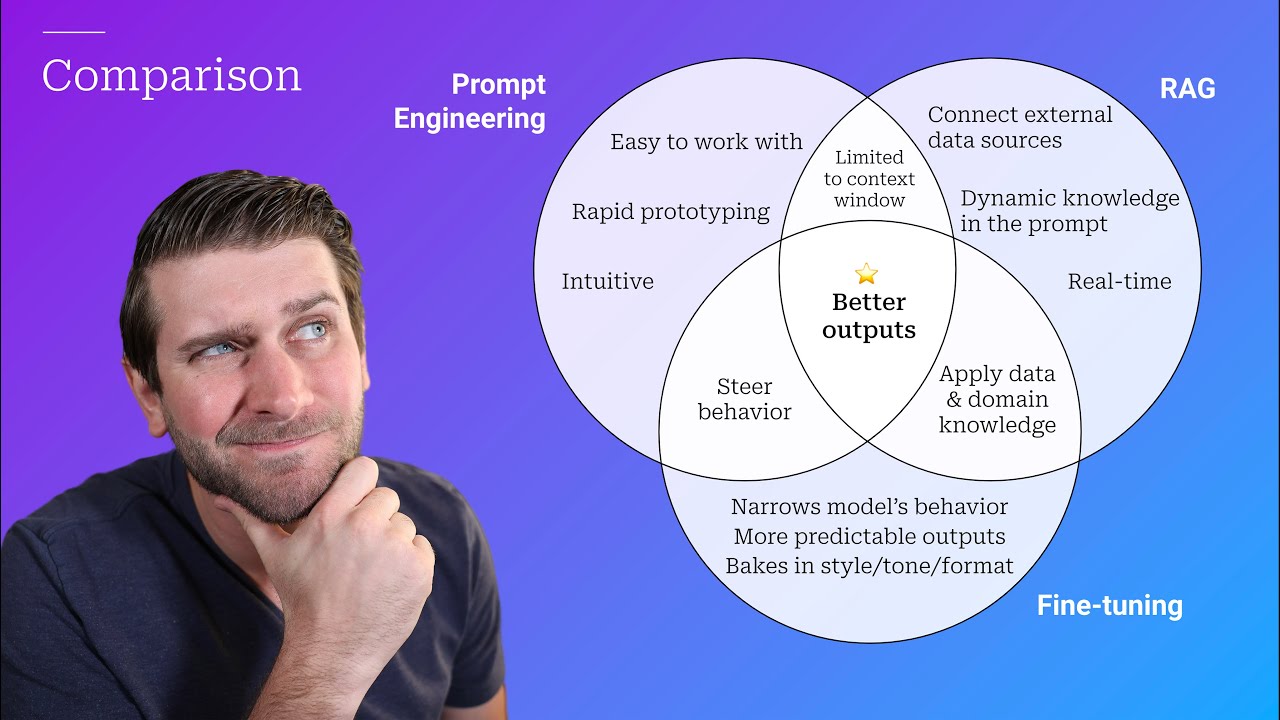
Prompt Engineering, RAG, and Fine-tuning: Benefits and When to Use
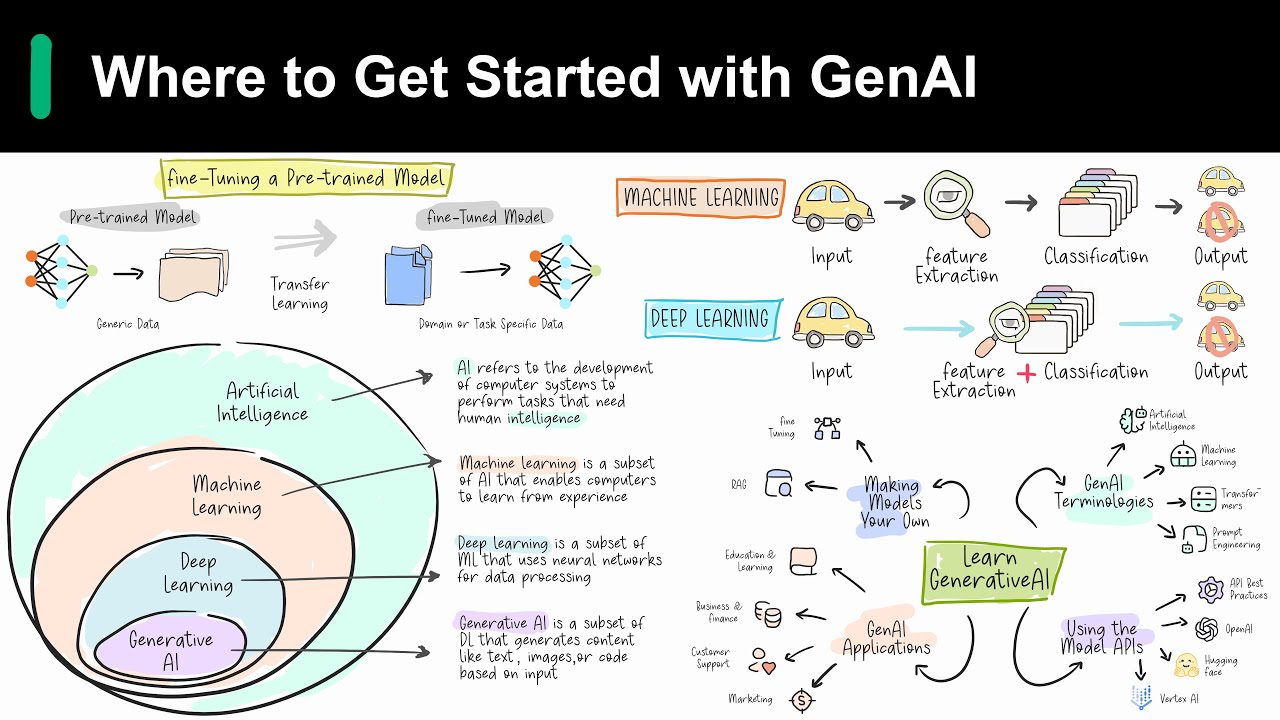
Introduction to Generative AI

Fine Tuning, RAG e Prompt Engineering: Qual é melhor? e Quando Usar?

Lessons From Fine-Tuning Llama-2

Lecture 3: Pretraining LLMs vs Finetuning LLMs

The Ultimate Writing Challenge: Longwriter Tackles 10,000 Words In One Sitting
5.0 / 5 (0 votes)