Introduction to Big Data
Summary
TLDRBig data refers to datasets so large that traditional tools can't handle them, requiring new solutions and multiple computing resources working in parallel. The three main characteristics of big data are volume, velocity, and variety. Volume refers to the sheer amount of data, velocity to the speed at which data is generated, and variety to the different types of data. Managing big data is expensive, so clear goals and objectives are essential. Cloud computing has made handling big data more affordable and scalable. The video emphasizes the importance of understanding and utilizing big data effectively.
Takeaways
- 🧐 Big data refers to data sets that are too large for traditional tools and methods to handle, necessitating new solutions.
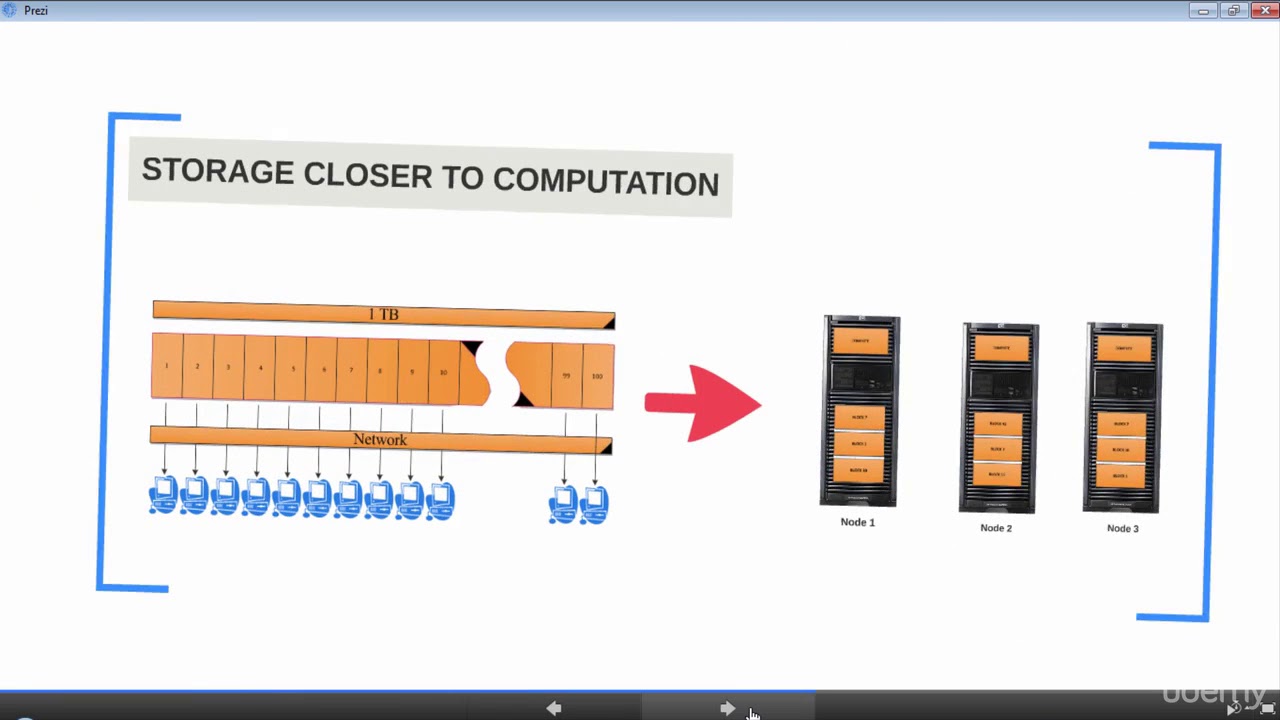
- 💻 Traditional hardware, such as a single laptop, is insufficient for processing big data due to its immense size.
- 🔄 The approach to handling big data often involves using multiple computing resources working in parallel, distributing tasks across virtual machines.
- 🔑 The concept is akin to cleaning a house with a team, where many hands make the task lighter and faster.
- 📊 Big data is characterized by the 'three Vs': Volume (large amounts of data), Velocity (fast incoming data), and Variety (a mix of structured and unstructured data types).
- 📈 The definition of 'big data' can vary by company, depending on the volume that their methods can handle.
- 🌐 The variety of data sources is continuously growing, including video, social media, and smartphone data.
- 💰 Storing and processing big data can be costly, so it's important to have clear goals and objectives for what you aim to accomplish with the data.
- 📈 Common goals for big data include visualization for business understanding, identifying trends and patterns, and building predictive models.
- ☁️ Cloud computing has made big data more affordable and scalable, helping to manage the costs and adapt to growing data volumes.
Q & A
What is big data and why do we need new solutions to handle it?
-Big data refers to data sets that are so large that traditional tools and methods cannot handle them. New solutions are needed because these data sets are too large to be processed on a standard laptop's hardware.
How do we typically handle and deal with big data?
-We often handle big data by using several computing resources working in parallel. The work is distributed across these resources, which can be virtual machines, and they work on the data simultaneously.
What is an analogy used in the script to explain the concept of handling big data with multiple resources?
-The script uses the analogy of cleaning a house. If you do it by yourself, it could take a long time, but if you have a team helping you, the task can be completed much faster, illustrating the principle of 'many hands make light work'.
What are the three Vs used to describe big data?
-The three Vs used to describe big data are volume, velocity, and variety. Volume refers to the large amount of data, velocity indicates the speed at which data comes in, and variety refers to the mix of data types, including structured and unstructured data.
Can you provide an example of what might qualify as big data in terms of volume?
-An example of big data in terms of volume might be more data than can fit in an Excel spreadsheet. However, what qualifies as big data can vary across companies and is generally when the data volume exceeds what a company's methods can handle.
What are some sources of data variety that contribute to big data?
-Data variety in big data comes from a range of sources such as video data, social media data, and data from smartphones. As time goes on, the variety of data sources continues to grow.
Why can storing and processing big data be expensive, and what considerations should be made?
-Storing and processing big data can be expensive due to the large volumes and the need for high-performance computing resources. It's important to consider goals and objectives, such as visualizing data for business understanding, identifying trends and patterns, or building predictive models, to ensure that the expense is justified.
How has cloud computing made big data handling more affordable and scalable?
-Cloud computing provides affordability and scalability for big data handling. It has made big data more affordable by offering cost-effective storage and computing options, and it is scalable, meaning it can adjust to accommodate growing data volumes quickly.
What are some goals and objectives one might have when working with big data?
-Some goals and objectives when working with big data include visualizing the data to better understand the business, identifying trends and patterns within the data, and building predictive models to forecast future outcomes.
Where can viewers find more analytics resources similar to the content of the script?
-Viewers interested in finding more analytics resources similar to the content of the script can visit codybaldwin.com for additional cheat sheets and resources.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowBrowse More Related Video

ArcGIS GeoAnalytics Engine: On-demand geospatial data analysis

Enterprise Computing Year 12 Unit 1: Data Science
005 Understanding Big Data Problem

What is Grid Computing? (in 60 seconds)

APA ITU BIG DATA? | Algoritma 2021

Hadoop Introduction | What is Hadoop? | Big Data Analytics using Hadoop | Lecture 1
5.0 / 5 (0 votes)