Intelligence artificielle par apprentissage automatique (Francis Bach)
Summary
TLDRCette vidéo explore les avancées récentes de l'intelligence artificielle, notamment dans des domaines comme la reconnaissance d'images, la traduction automatique et l'apprentissage automatique. Elle explique comment des données massives, une puissance de calcul accrue et l'expertise humaine en matière de recherche sont essentielles pour développer des algorithmes performants. À travers un exemple concret de reconnaissance de chiffres manuscrits, le processus d'apprentissage automatique est détaillé, mettant en lumière la nécessité de la représentation des données et de l'optimisation pour classifier efficacement de nouvelles entrées.
Takeaways
- 😀 L'intelligence artificielle est intégrée dans notre quotidien depuis plus d'une décennie, notamment dans nos téléphones.
- 😀 Les avancées récentes en IA sont dues à des progrès dans des tâches où les machines se rapprochent des performances humaines.
- 😀 Trois facteurs principaux sont nécessaires pour l'apprentissage automatique : des données, une puissance de calcul et des modèles algorithmiques.
- 😀 Pour entraîner un algorithme, il faut des données d'entraînement qui permettent de classer de nouvelles données de test.
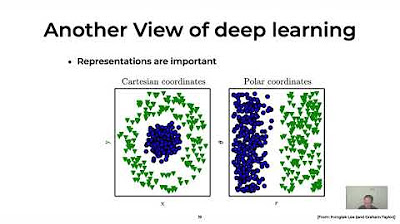
- 😀 La représentation des données est cruciale ; par exemple, les chiffres manuscrits peuvent être transformés en tableaux de pixels.
- 😀 La réduction de dimensionnalité est importante pour simplifier le problème et rendre l'apprentissage plus efficace.
- 😀 La séparation des classes (par exemple, chiffres 6 et 9) peut être effectuée à l'aide de droites dans un plan de représentation.
- 😀 L'optimisation des paramètres de séparation est essentielle pour minimiser les erreurs dans la classification des données.
- 😀 Les réseaux de neurones peuvent automatiser la recherche de représentations pertinentes pour des images complexes.
- 😀 Pour aller plus loin dans l'apprentissage automatique, il existe de nombreuses ressources en ligne, y compris des tutoriels en Python.
Q & A
Qu'est-ce que l'intelligence artificielle (IA) et où la retrouve-t-on aujourd'hui?
-L'IA est une technologie qui simule des comportements humains et est déjà présente dans nos téléphones, par exemple pour la reconnaissance faciale ou la personnalisation des contenus par des algorithmes.
Quels sont les trois facteurs principaux qui ont contribué aux récents progrès de l'IA?
-Les trois facteurs principaux sont la disponibilité de grandes quantités de données, la puissance de calcul accrue et l'expertise des chercheurs et ingénieurs qui développent des modèles et algorithmes.
Comment l'apprentissage automatique fonctionne-t-il dans le cadre de la reconnaissance de chiffres manuscrits?
-L'apprentissage automatique utilise des données d'entraînement, comme des exemples de chiffres manuscrits, pour créer un modèle qui peut classer de nouvelles images en fonction des caractéristiques apprises.
Pourquoi est-il nécessaire de réduire la dimension des données pour l'apprentissage automatique?
-Réduire la dimension des données permet de simplifier le modèle et d'identifier les caractéristiques les plus pertinentes pour la prédiction, facilitant ainsi l'apprentissage et la classification.
Comment les données sont-elles représentées dans un modèle d'apprentissage automatique?
-Les données sont souvent représentées sous forme de tableaux de nombres réels, où chaque dimension peut correspondre à une caractéristique spécifique des données, comme le nombre de pixels noircis dans une image.
Qu'est-ce qu'une droite séparatrice dans le contexte de l'apprentissage automatique?
-Une droite séparatrice est une ligne qui divise l'espace des données en différentes classes. L'objectif de l'apprentissage est de trouver la meilleure droite qui minimise les erreurs de classification.
Comment l'algorithme d'apprentissage détermine-t-il les paramètres optimaux pour la droite séparatrice?
-L'algorithme utilise des méthodes d'optimisation pour ajuster les paramètres de la droite afin de minimiser le nombre d'erreurs de classification, en vérifiant différentes configurations possibles.
Quelle est la différence entre l'apprentissage automatique traditionnel et l'apprentissage profond?
-L'apprentissage automatique traditionnel utilise souvent des méthodes simples avec un nombre limité de paramètres, tandis que l'apprentissage profond utilise des réseaux de neurones complexes avec des millions de paramètres pour traiter des données de grande dimension.
Quels types de données sont nécessaires pour entraîner un algorithme d'apprentissage automatique?
-Pour entraîner un algorithme, il faut des données d'entraînement qui incluent des exemples et les classes correspondantes, permettant à l'algorithme d'apprendre à classer de nouvelles données.
Quels outils ou ressources sont recommandés pour approfondir ses connaissances en apprentissage automatique?
-Il existe de nombreuses ressources en ligne, comme Wikipédia ou des sites spécialisés, qui offrent des cours et des tutoriels pour apprendre à coder des algorithmes d'apprentissage automatique en Python.
Outlines

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowMindmap

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowKeywords

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowHighlights

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowTranscripts

This section is available to paid users only. Please upgrade to access this part.
Upgrade NowBrowse More Related Video

Du machine learning et des données | Guillaume et les algorithmes

Introduction à l’intelligence artificielle - 7 - Frontières

Le DANGER et la Face Cachée de l'INTELLIGENCE ARTIFICIELLE ( IA, Chatgpt, chat gpt 4..) Documentaire

Yann LeCun - Réflexions sur le parcours et l’avenir de l’IA

Audition de Yann LeCun, Professeur à NYU et Scientifique en chef sur l'IA à Meta.
Week 5 -- Capsule 3 -- Learning representations
5.0 / 5 (0 votes)
