Differences between Oracle Autonomous Databases ATP & ADW
Summary
TLDRThe video script explores Oracle's two autonomous database services: ADW for analytics in columnar format and ATP for transaction processing in row format. It highlights the differences in data storage, query optimization with parallelism for ADW and indexing for ATP, and memory allocation strategies. The script also explains how statistics are automatically maintained in both services, with specific focus on the real-time updates and bulk load activities in ADW, and significant data volume changes in ATP. The next video promises to guide on provisioning an ATP database.
Takeaways
- 🗂️ ADW vs ATP: Oracle offers two autonomous database services, ADW for data warehousing and ATP for transaction processing (OLTP).
- 📊 Data Storage Formats: ADW stores data in a columnar format, ideal for analytics, while ATP uses a row format, suitable for quick access and updates in transaction processing.
- 🔍 Query Optimization: ADW queries are automatically parallelized to handle large data volumes, whereas ATP uses indexes to access specific rows, enhancing performance.
- 🚀 Automatic Indexing: ATP with Oracle 19c automatically creates indexes, optimizing access to rows of interest, a feature that enhances the efficiency of transaction processing.
- 💾 Memory Allocation: ADW allocates most memory to PGA for in-memory operations like parallel joins and aggregations, while ATP prioritizes SGA to cache the critical working set and reduce I/O operations.
- 📈 Real-time Statistics: Both ADW and ATP maintain optimizer statistics in real time, ensuring the performance of the database systems.
- 📊 Bulk Load Statistics: In ADW, statistics including histograms are automatically maintained during bulk load activities, optimizing the analytical performance post data ingestion.
- 🔄 Dynamic Stats Gathering: ATP gathers statistics dynamically when there is a significant change in data volume, adapting to the evolving data landscape for optimal query performance.
- 🛠️ Provisioning Guidance: The next video will cover how to provision an ATP database, indicating a step-by-step guide for setting up an autonomous transaction processing environment.
- 🔑 Key Differences: Despite similarities, ADW and ATP have distinct backend operations, data storage methods, and optimization strategies tailored to their specific use cases in warehousing and transaction processing.
Q & A
What are the two variants of Oracle Autonomous Databases?
-The two variants of Oracle Autonomous Databases are ADW (Autonomous Data Warehouse) and ATP (Autonomous Transaction Processing).
What type of application is ADW designed for?
-ADW is designed for data warehouse applications that require analytics processing.
What is the data storage format used in ADW?
-In ADW, data is stored in a columnar format, which is optimal for analytics processing.
What is the data storage format used in ATP?
-In ATP, data is stored in a row format, which is ideal for transaction processing or OLTP.
How does query optimization differ between ADW and ATP?
-Queries in ADW are automatically parallelized to handle large volumes of data, while ATP uses indexes to access specific rows of interest.
What is the significance of the PGA in ADW?
-In ADW, the majority of the memory is allocated to the PGA to allow for parallel joins and complex aggregations to occur in memory, reducing the need for disk access.
Why is the SGA important in ATP?
-In ATP, the majority of the memory is allocated to the SGA to ensure that the critical working set can be cached, minimizing the necessary I/O operations.
How are optimizer statistics maintained in ADW?
-Optimizer statistics in ADW are automatically maintained, including histograms, as part of bulk load activities.
How are optimizer statistics updated in ATP?
-In ATP, optimizer statistics are automatically gathered when there is a significant change in the volume of data.
What is the difference in the approach to statistics gathering between ADW and ATP during bulk load operations?
-In ADW, statistics gathering occurs as soon as a bulk load is performed, whereas in ATP, statistics are gathered only when there is a significant change in data volume.
What will be the topic of the next video in the series?
-The next video will cover how to provision an Autonomous Database, specifically focusing on ATP.
Outlines

Этот раздел доступен только подписчикам платных тарифов. Пожалуйста, перейдите на платный тариф для доступа.
Перейти на платный тарифMindmap

Этот раздел доступен только подписчикам платных тарифов. Пожалуйста, перейдите на платный тариф для доступа.
Перейти на платный тарифKeywords

Этот раздел доступен только подписчикам платных тарифов. Пожалуйста, перейдите на платный тариф для доступа.
Перейти на платный тарифHighlights

Этот раздел доступен только подписчикам платных тарифов. Пожалуйста, перейдите на платный тариф для доступа.
Перейти на платный тарифTranscripts

Этот раздел доступен только подписчикам платных тарифов. Пожалуйста, перейдите на платный тариф для доступа.
Перейти на платный тарифПосмотреть больше похожих видео

ADBMS: Unit 1: Lecture 1: Database Concepts, Introduction to Transaction Control Language.
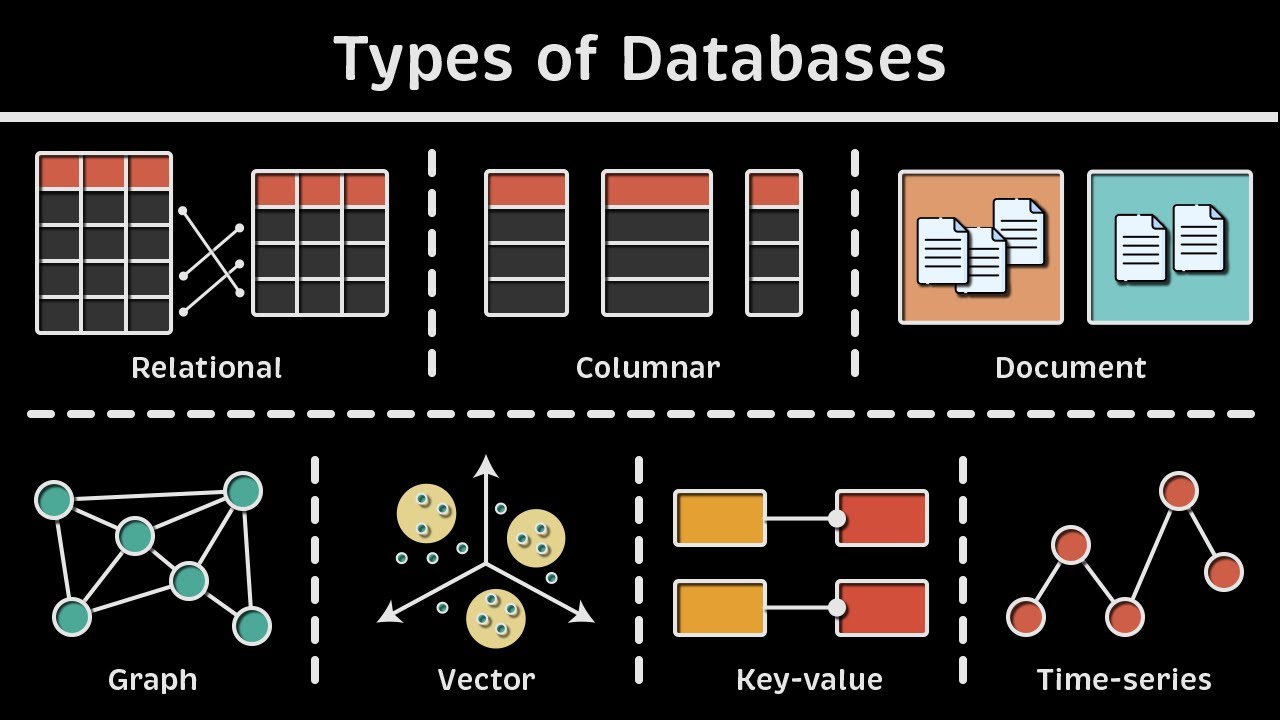
Types of Databases: Relational vs. Columnar vs. Document vs. Graph vs. Vector vs. Key-value & more

OLTP vs OLAP | Online Transaction Processing vs Online Analytical Processing | Edureka

Lecture 31: Transactions/1 : Serializability
Oracle Database Lock Monitoring with Read Committed Transaction Isolation Level Brief Explanation

What Is ClickHouse?
5.0 / 5 (0 votes)
