Data Warehouse System Processes | Lecture #5 | Data Warehouse Tutorial for beginners
Summary
TLDRThis tutorial video delves into the processes involved in building a data warehouse. It covers the essential steps including data extraction and loading, cleaning and transforming, backup and archiving, and query management. The video emphasizes the importance of these processes for optimizing query performance, managing data efficiently, and ensuring data integrity. It also highlights the need for data warehouses to adapt as businesses grow, making it a valuable resource for anyone interested in data warehousing solutions.
Takeaways
- 📚 The video introduces various processes involved in a data warehouse and their significance with examples.
- 🔄 The first process discussed is 'Extract and Load', which involves taking data from source systems and loading it into the data warehouse after reconstruction.
- 🕒 The 'Controlling Process' is crucial for determining when to start data extraction and ensuring data consistency.
- 🔍 'Cleaning and Transforming' is the second major process, which includes making the data consistent and structuring it to improve query performance.
- 📊 'Partitioning' the data is part of the cleaning and transforming process, which optimizes hardware performance and simplifies data warehouse management.
- 🔢 'Aggregation' is performed to speed up common queries by analyzing subsets or aggregations of detailed data.
- 🛡️ 'Backup and Archiving' is essential for data recovery in case of data loss, software, or hardware failure, and for keeping old data accessible for restoration.
- 🔎 The 'Query Management Process' is vital for managing queries, speeding up their execution, directing them to effective data sources, and monitoring query profiles.
- 📈 Query management also helps in determining which aggregations to generate based on the information from query profiles, thus improving efficiency.
- 🌐 The tutorial aims to build data warehousing solutions on open system technologies like UNIX and relational databases.
- 🎥 The video is a tutorial that provides an introductory overview of the processes involved in a data warehouse, including extraction, cleaning, backup, archiving, and query management.
Q & A
What are the main processes involved in a data warehouse?
-The main processes involved in a data warehouse are extract and load, cleaning and transforming data, backup and archiving data, and query management.
What does the extract and load process involve?
-The extract and load process involves taking data from source systems and loading it into the data warehouse, ensuring the data is reconstructed in a way that is suitable for the data warehouse to store.
Why is it important to control the process during data extraction?
-Controlling the process is important to determine when to start the data extraction and to check the consistency of the data. It ensures that the tools, logic modules, and programs are executed in the correct sequence and at the right time.
What should be considered when initiating the data extraction?
-When initiating the data extraction, it is important to ensure that the data is in a consistent state and represents a single, consistent version of the information to the user.
What is the purpose of cleaning and transforming the data in a data warehouse?
-Cleaning and transforming the data helps to speed up queries by making the data consistent and converting the source data into a structure that increases query performance and decreases operational cost.
What is partitioning in the context of data warehousing?
-Partitioning is the process of dividing each fact table into multiple separate partitions to optimize hardware performance and simplify the management of the data warehouse.
Why is aggregation important in data warehousing?
-Aggregation is important to speed up common queries by relying on the fact that most common queries will analyze a subset or an aggregation of the detailed data.
What is the significance of backup and archiving in a data warehouse?
-Backup and archiving are crucial for recovering data in the event of data loss, software failure, or hardware failure. Archiving also allows for the removal of old data in a format that can be quickly restored when required.
What functions does the query management process perform?
-The query management process manages and speeds up the execution time of queries, directs queries to their most effective data sources, ensures optimal use of system resources, and monitors actual query profiles.
How does the query management process help in improving the efficiency of the data warehouse?
-The query management process improves efficiency by lowering operational costs and ensuring that all system sources are used in the most effective way, as well as by monitoring query profiles to determine which aggregations to generate.
What is the role of open system technologies in building data warehousing solutions?
-Open system technologies like UNIX and relational databases provide the foundation for building scalable and flexible data warehousing solutions that can evolve as the business grows.
Outlines

Этот раздел доступен только подписчикам платных тарифов. Пожалуйста, перейдите на платный тариф для доступа.
Перейти на платный тарифMindmap

Этот раздел доступен только подписчикам платных тарифов. Пожалуйста, перейдите на платный тариф для доступа.
Перейти на платный тарифKeywords

Этот раздел доступен только подписчикам платных тарифов. Пожалуйста, перейдите на платный тариф для доступа.
Перейти на платный тарифHighlights

Этот раздел доступен только подписчикам платных тарифов. Пожалуйста, перейдите на платный тариф для доступа.
Перейти на платный тарифTranscripts

Этот раздел доступен только подписчикам платных тарифов. Пожалуйста, перейдите на платный тариф для доступа.
Перейти на платный тарифПосмотреть больше похожих видео

Data Warehouse Delivery Process| Lecture #4 | Data Warehouse Tutorial for beginners
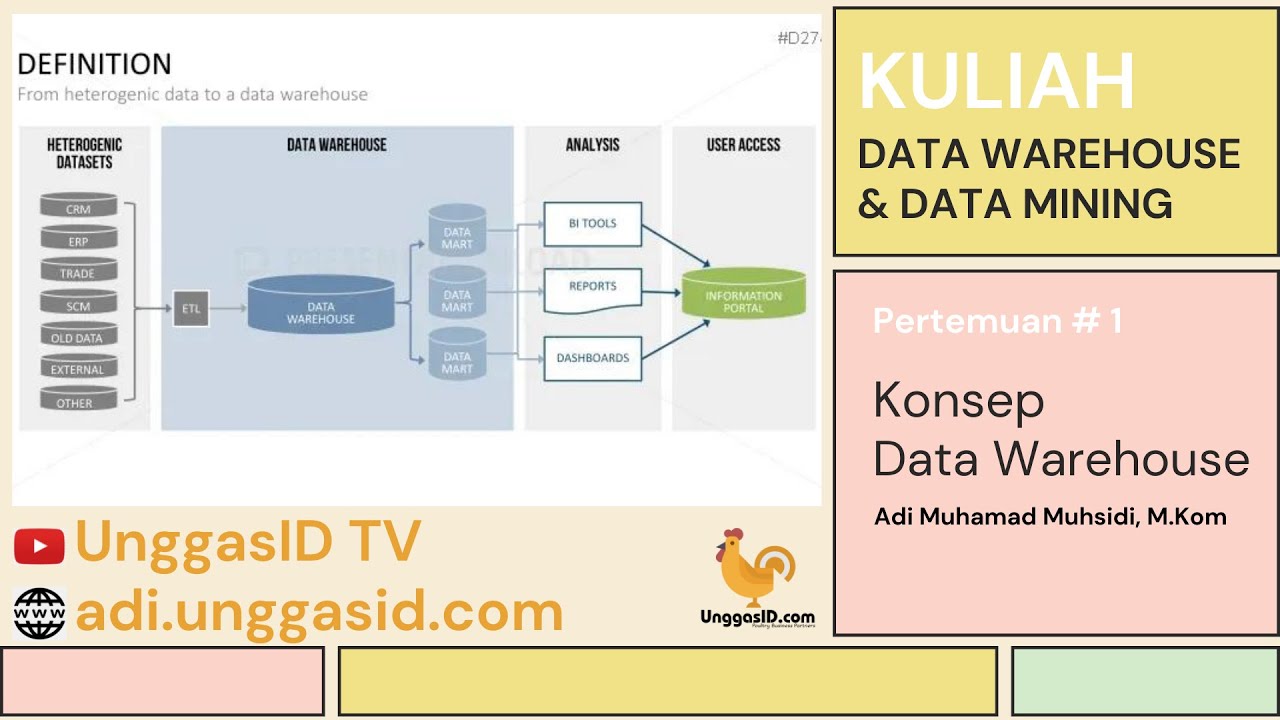
Kuliah Data Warehouse & Data Mining - 01. Konsep Data Warehouse

Data Warehouse Architecture | Lecture #6 | Data Warehouse Tutorial for beginners

Data Warehouse Terminology | Lecture #3 | Data Warehouse Tutorial for beginners

Processes of Warehousing | Warehouse Processes Explained | Warehouse Processes and Procedures

FUNCIONES del ALMACÉN - Administración EFECTIVA de Almacenes y Control de Inventarios - Video 3
5.0 / 5 (0 votes)
